selenium自动化测试-登录网站用户
昨天学习了selenium自动化测试工具的入门,知道了Selenium是用于自动化控制浏览器做各种操作,打开网页,点击按钮,输入表单等等。
今天学习通过selenium自动化测试工具自动登录某网站用户操作。
第一步:确定目标网址
比如:天天基金网站登录页面"https://login.1234567.com.cn/login"
第二步:确定登录表单元素位置
通过谷歌浏览器F12调试功能可以很快的定位页面元素位置,这也是开发常用谷歌浏览器的原因吧!
比如:用户账号输入框位置
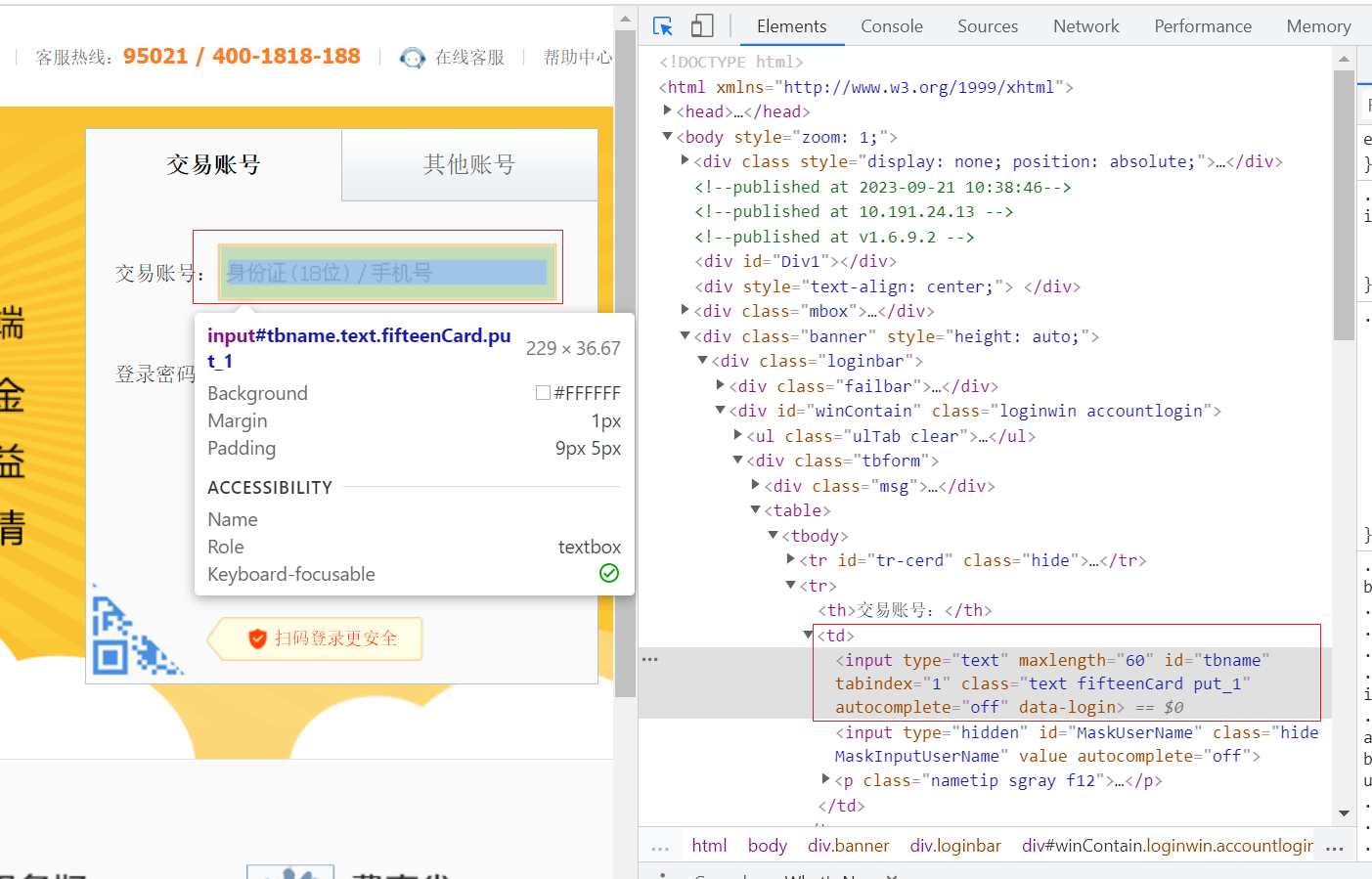

通过 F12 调试确定元素位置,然后右键--》Copy--》Copy XPath: 获得账号输入框位置: //*[@id="tbname"]
在后面写代码操作该元素使用该方法即可: driver.find_element(By.ID, "tbname")
依次类推,获取密码,记住交易账号单选框,已阅读单选框,登录按钮等等表单元素位置。
第三步:编写代码
采用拆分步骤细化功能模块封装方法编写代码,便于后续扩展功能模块。
ttjj_webdriver.py:
# -*- coding: UTF-8 -*-
# selenium 自动化测试工具
import time
import random
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By # 打开驱动
def open_driver():
try:
# 连接浏览器web驱动全局变量
global driver
# Linux系统下浏览器驱动无界面显示,需要设置参数
# “–no-sandbox”参数是让Chrome在root权限下跑
# “–headless”参数是不用打开图形界面
'''
chrome_options = Options()
# 设为无头模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--disable-dev-shm-usage')
# 连接Chrome浏览器驱动,获取驱动
driver = webdriver.Chrome(chrome_options=chrome_options)
''' # 此步骤很重要,设置chrome为开发者模式,防止被各大网站识别出来使用了Selenium
options = Options()
# 去掉提示:Chrome正收到自动测试软件的控制
# options.add_argument('disable-infobars')
# 以键值对的形式加入参数,打开浏览器开发者模式
# options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 打开浏览器开发者模式
# options.add_argument("--auto-open-devtools-for-tabs")
driver = webdriver.Chrome(chrome_options=options) # driver = webdriver.Chrome()
print('连接Chrome浏览器驱动')
# 浏览器窗口最大化
driver.maximize_window()
'''
1, 隐式等待方法
driver.implicitly_wait(最大等待时间, 单位: 秒)
2, 隐式等待作用
在规定的时间内等待页面所有元素加载;
3,使用场景:
在有页面跳转的时候, 可以使用隐式等待。
'''
driver.implicitly_wait(3)
# 强制等待,随机休眠 暂停0-3秒的整数秒,时间区间:[0,3]
time.sleep(random.randint(0, 3)) except Exception as e:
driver = None
print(str(e)) # 关闭驱动
def close_driver():
driver.quit()
print('关闭Chrome浏览器驱动') # 检查元素是否存在
def check_element_exists(condition, element):
'''
@方法名称: 校验判断网页元素是否存在
@中文注释: 校验判断网页元素是否存在
@入参:
@param condition str 网页元素定位条件
@param element str 网页元素定位坐标
@出参:
@返回状态:
@return 0 失败
@return 1 成功
@return 2 异常
@返回错误码
@返回错误信息
@作 者: PandaCode辉
@创建时间: 2023-09-21
@使用范例: check_element_exists('id', 'username')
'''
try:
if (not type(condition) is str):
print('条件参数错误,不是字符串:' + element)
return [0, "111111", "条件参数错误,不是字符串", [None]]
if (not type(element) is str):
print('元素参数错误,不是字符串:' + element)
return [0, "111112", "元素参数错误,不是字符串", [None]]
# 根据条件定位元素
if condition == 'class':
driver.find_element(By.CLASS_NAME, element)
elif condition == 'id':
driver.find_element(By.ID, element)
elif condition == 'xpath':
driver.find_element(By.XPATH, element)
return [1, '000000', "判断网页元素成功", [None]]
except Exception as e:
return [0, '999999', "判断网页元素是否存在异常," + str(e), [None]] def pc_ttjj_login(username, password):
'''
@方法名称: 登录天天基金用户
@中文注释: 登录天天基金用户
@入参:
@param username str 登录用户
@param password str 登录密码
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@作 者: PandaCode辉
@创建时间: 2023-09-21
@使用范例: ['user123','pwd123']
'''
try: if (not type(username) is str):
return [0, "111111", "登录用户参数类型错误,不为字符串", [None]]
if (not type(password) is str):
return [0, "111112", "登录密码参数类型错误,不为字符串", [None]] print('开始打开Chrome浏览器驱动')
open_driver() print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2)) print('username:' + username + '/password:' + password) # 登录时请求的url
login_url = 'https://login.1234567.com.cn/login'
driver.get(login_url) print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2)) # 清空登录框
# 通过webdriver对象的find_element_by_xx(" "),在selenium的4.0版本中此种用法已经抛弃。
# driver.find_element_by_xpath("./*//input[@id='tbname']").clear()
'''
通过webdriver模块中的By,以指定方式定位元素
导入模块:from selenium.webdriver.common.by import By driver.find_element(By.ID,"username")
driver.find_element(By.CLASS_NAME,"passwors")
driver.find_element(By.TAG_NAME,"imput"
'''
driver.find_element(By.ID, "tbname").clear()
print('输入用户名')
# 自动填入登录用户名
# driver.find_element_by_xpath("./*//input[@id='tbname']").send_keys(username)
driver.find_element(By.ID, "tbname").send_keys(username) print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2)) # 清空密码框
driver.find_element(By.ID, "tbpwd").clear()
print('输入密码')
# 自动填入登录密码
driver.find_element(By.ID, "tbpwd").send_keys(password) print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2)) # 点击#记住交易帐号
driver.find_element(By.ID, "tbcook").click()
print('点击记住交易帐号') # 点击#同意服务协议
driver.find_element(By.ID, "protocolCheckbox").click()
print('点击同意服务协议') # 点击登录按钮进行登录
driver.find_element(By.ID, "btn_login").click()
print('点击登录按钮')
# 等待3秒启动完成
driver.implicitly_wait(3)
time.sleep(3) print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2)) # 检查元素是否存在,查看持仓明细元素,用来判断是否登录成功
check_rsp = check_element_exists('id', "myassets_hold")
if check_rsp[0] == 1:
print("登录成功")
print('开始关闭Chrome浏览器驱动')
close_driver()
# 返回容器
return [1, '000000', "登录成功", [None]]
else:
return check_rsp except Exception as e:
print("登录账户异常," + str(e))
print('开始关闭Chrome浏览器驱动')
close_driver()
return [0, '999999', "登录账户异常," + str(e), [None]] # 主方法
if __name__ == '__main__':
username = "123456789"
password = "password123" # 登录用户
rst = pc_ttjj_login(username, password)
第四步:运行测试效果
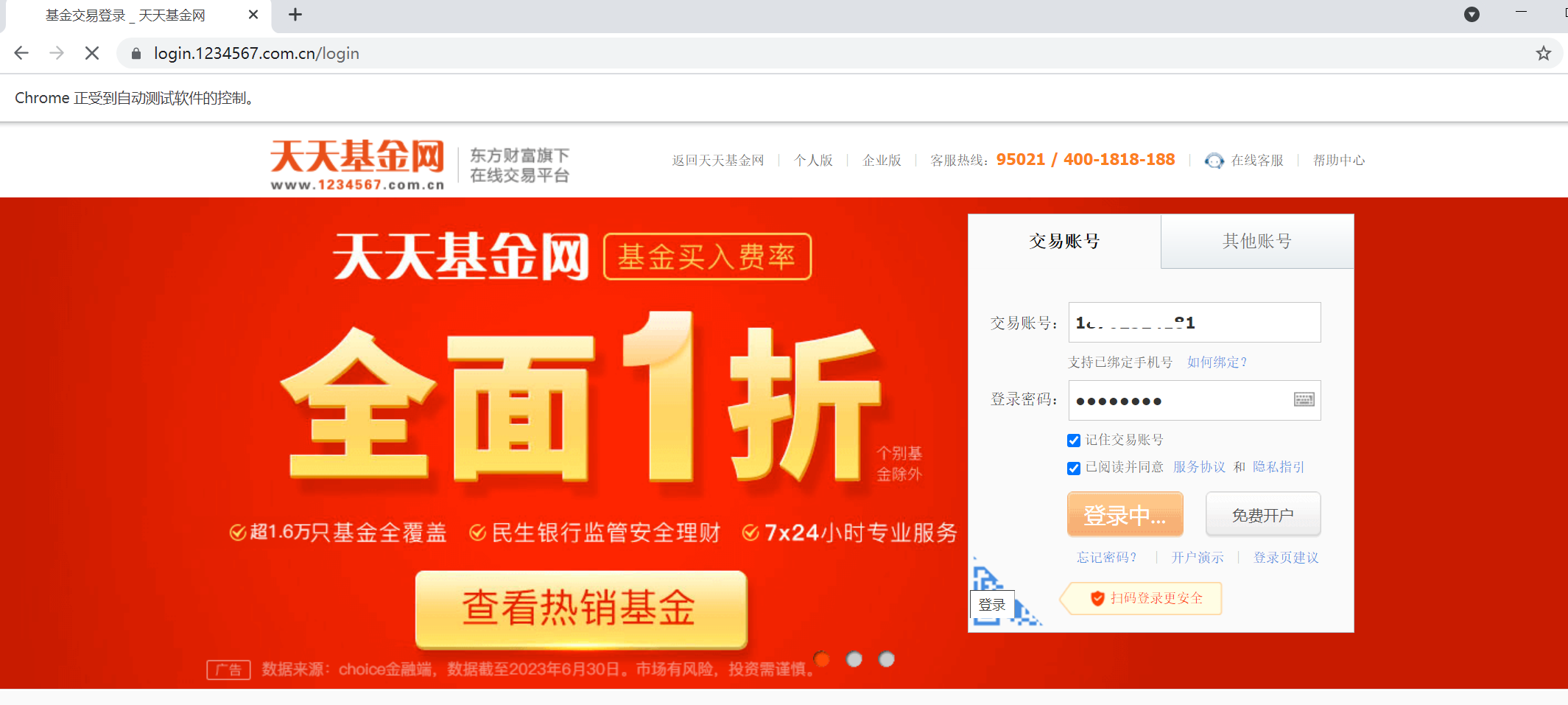
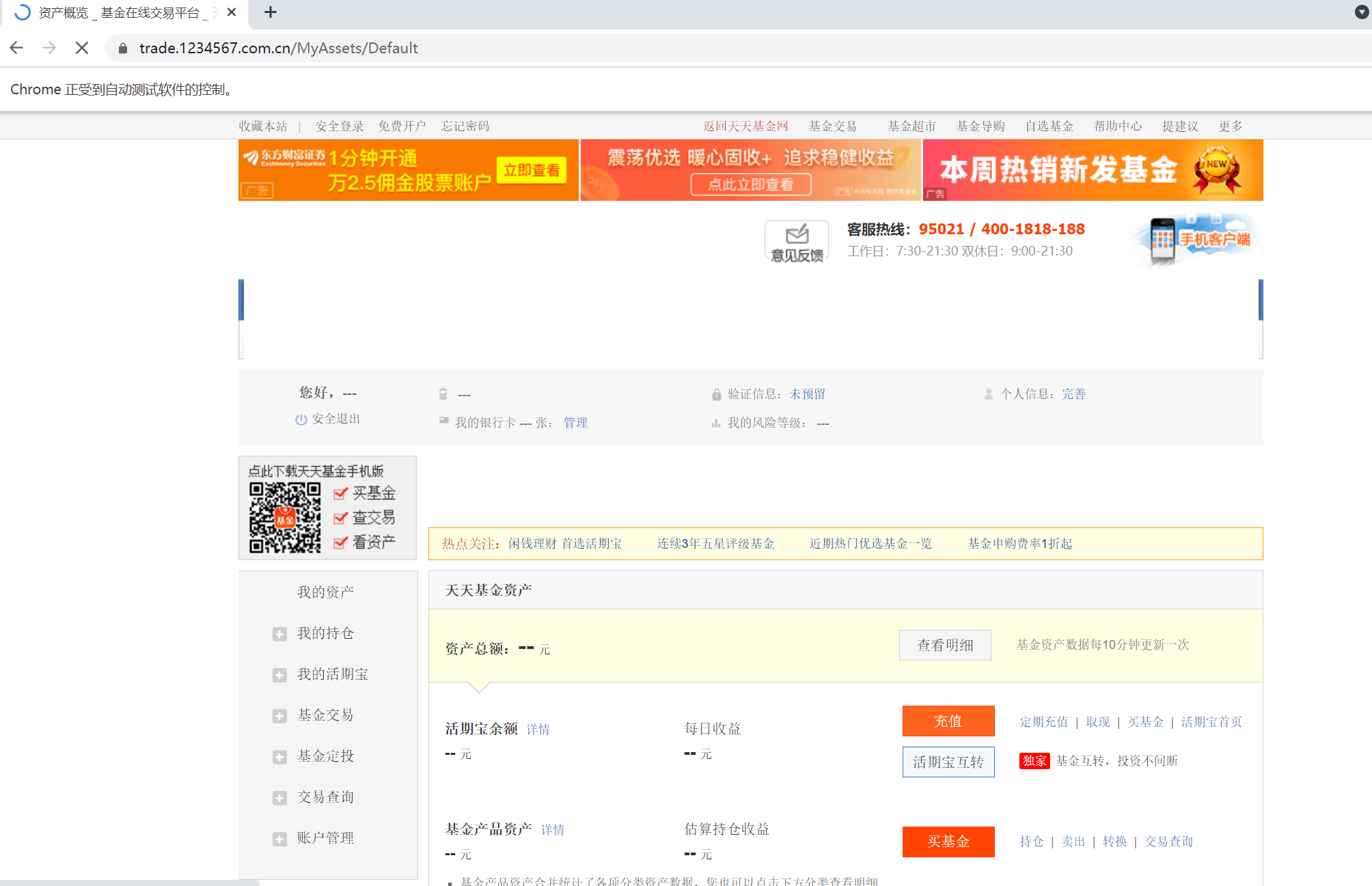
-------------------------------------------end---------------------------------------
selenium自动化测试-登录网站用户的更多相关文章
- 自动化测试: Selenium 自动登录授权,再 Requests 请求内容
Selenium 自动登录网站.截图及 Requests 抓取登录后的网页内容.一起了解下吧. Selenium: 支持 Web 浏览器自动化的一系列工具和库的综合项目. Requests: 唯一的一 ...
- C#模拟网站用户登录
我们在写灌水机器人.抓资源机器人和Web网游辅助工具的时候第一步要实现的就是用户登录.那么怎么用C#来模拟一个用户的登录拉?要实现用户的登录,那么首先就必须要了解一般网站中是怎么判断用户是否登录的. ...
- 写了一个Windows服务,通过C#模拟网站用户登录并爬取BUG列表查询有没有新的BUG,并提醒我
写了一个Windows服务,通过C#模拟网站用户登录并爬取BUG列表查询有没有新的BUG,并提醒我 1.HttpUtil工具类,用于模拟用户登录以及爬取网页: using System; using ...
- 使用C#实现网站用户登录
我们在写灌水机器人.抓资源机器人和Web网游辅助工具的时候第一步要实现的就是用户登录.那么怎么用C#来模拟一个用户的登录拉?要实现用户的登录,那么首先就必须要了解一般网站中是怎么判断用户是否登录的.H ...
- Selenium自动化测试Python二:WebDriver基础
WebDriver基础 欢迎阅读WebDriver基础讲义.本篇讲义将会重点介绍Selenium WebDriver的环境搭建和基本使用方法. WebDriver环境搭建 Selenium WebDr ...
- 《手把手教你》系列技巧篇(二十八)-java+ selenium自动化测试-处理模态对话框弹窗(详解教程)
1.简介 在前边的文章中窗口句柄切换宏哥介绍了switchTo方法,这篇继续介绍switchTo中关于处理alert弹窗的问题.很多时候,我们进入一个网站,就会弹窗一个alert框,有些我们直接关闭, ...
- Selenium自动化测试,接口自动化测试开发,性能测试从入门到精通
Selenium自动化测试,接口自动化测试开发,性能测试从入门到精通Selenium接口性能自动化测试基础部分:分层自动化思想Slenium介绍Selenium1.0/2.0/3.0Slenium R ...
- Selenium自动化测试Python一:Selenium入门
Selenium入门 欢迎阅读Selenium入门讲义,本讲义将会重点介绍Selenium的入门知识以及Selenium的前置知识. 自动化测试的基础 在Selenium的课程以前,我们先回顾一下软件 ...
- 使用Selenium爬取网站表格类数据
本文转载自一下网站:Python爬虫(5):Selenium 爬取东方财富网股票财务报表 https://www.makcyun.top/web_scraping_withpython5.html 需 ...
- 使用Python+Selenium模拟登录QQ空间
使用Python+Selenium模拟登录QQ空间爬QQ空间之类的页面时大多需要进行登录,研究QQ登录规则的话,得分析大量Javascript的加密解密,这绝对能掉好几斤头发.而现在有了seleniu ...
随机推荐
- Qt项目升级到Qt6吐血经验总结
Qt的版本发布越来越频繁,Qt6发布已经有一段时间了,越来越多的人咨询之前的代码是否可以增加对Qt6的支持,包括开源的项目QWidgetDemo(一年时间超过2.6K star),近期百忙之中,对所有 ...
- 主打一个“小巧灵动”:Vite + Svelte
作者:来自 vivo 互联网大前端团队- Wei Xing 在研发小型项目时,传统的 Vue.React 显得太"笨重".本文主要针对开发小型项目的场景,谈谈 Vite+Svel ...
- 饿了么组件中el-menu el-submenu el-menu-item三者之间的关系
饿了么组件中el-menu el-submenu el-menu-item三者之间的关系: 1.<el-menu>是菜单标签,里面可以包括:<el-submenu>和&l ...
- itextpdf 找出PDF中 文字的坐标
目录 添加引用 添加工具类 调用 找到位置,签名的话见:https://www.cnblogs.com/vipsoft/p/18644127 新项目可以尝试一下 iText 7 , 我这边是老项目所以 ...
- Canvas简历编辑器-选中绘制与拖拽多选交互方案
Canvas简历编辑器-选中绘制与拖拽多选交互方案 在之前我们聊了聊如何基于Canvas与基本事件组合实现了轻量级DOM,并且在此基础上实现了如何进行管理事件以及多层级渲染的能力设计.那么此时我们就依 ...
- 利用Linq Skip() Take()分页
private void TestPostData() { string all = ""; List<int> listTimeCard = new List< ...
- SpringBoot(九) - Swagger
1.依赖 <!-- swagger 核心 --> <dependency> <groupId>io.springfox</groupId> <ar ...
- Golang-包8
http://c.biancheng.net/golang/package/ Go语言包的基本概念 Go语言是使用包来组织源代码的,包(package)是多个 Go 源码的集合,是一种高级的代码复用方 ...
- Golang-语言简介1
http://c.biancheng.net/golang/intro/ Go语言的特性 Go语言也称为 Golang,是由 Google 公司开发的一种静态强类型.编译型.并发型.并具有垃圾回收功能 ...
- 使用Python的一维卷积
学习&转载文章:使用Python的一维卷积 背景 在开发机器学习算法时,最重要的事情之一(如果不是最重要的话)是提取最相关的特征,这是在项目的特征工程部分中完成的. 在CNNs中,此过程由网络 ...