Hadoop和Spark大数据挖掘与实战
1.概述
本节将系统讲解大数据分析的完整流程,包括数据采集、预处理、存储管理、分析挖掘与结果可视化等核心环节。与此同时,我们还将对主流数据分析工具进行横向对比,帮助读者根据实际需求选用最合适的工具,提升数据价值挖掘的效率与深度。
2.内容
1.数据采集
数据采集是大数据分析的起点,旨在通过多种手段高效获取所需的原始数据,为后续处理与分析奠定基础。常见的数据源可分为内部数据与外部数据两大类:内部数据主要包括企业业务数据、交易记录、客户信息等,具有较高的相关性和准确性;外部数据则涵盖社交媒体动态、公开数据集、传感器数据等,能够为分析提供更丰富的视角与补充信息。
为确保数据的全面性与可靠性,常用的数据采集方式包括网络爬虫、API接口调用、传感器数据实时采集及人工数据录入等方法。根据数据类型和应用场景的不同,往往需要灵活组合多种手段,以构建多源异构的数据基础。
常见的数据采集方式包括:
- 网络爬虫:通过自动化脚本,从网页中批量抓取数据,适用于结构化和非结构化数据的收集,能够高效提取公开可访问的信息资源。
- API接口调用:作为应用程序间数据交换的重要方式,API接口允许开发者直接获取平台数据。例如,调用社交媒体平台的API,可以采集用户行为、互动记录和趋势分析等信息。
- 传感器数据采集:广泛应用于物联网(IoT)领域,通过部署在各类环境中的传感器,实时收集温度、湿度、运动等多种物理数据,支持实时监控与决策分析。
- 手动数据录入:尽管效率相对较低,但在某些特定场景下仍不可或缺,尤其是在需要人工标注、验证或处理复杂、主观性较强数据的情况下,手动输入能够保证数据的准确性和细致度。
如下图所示:
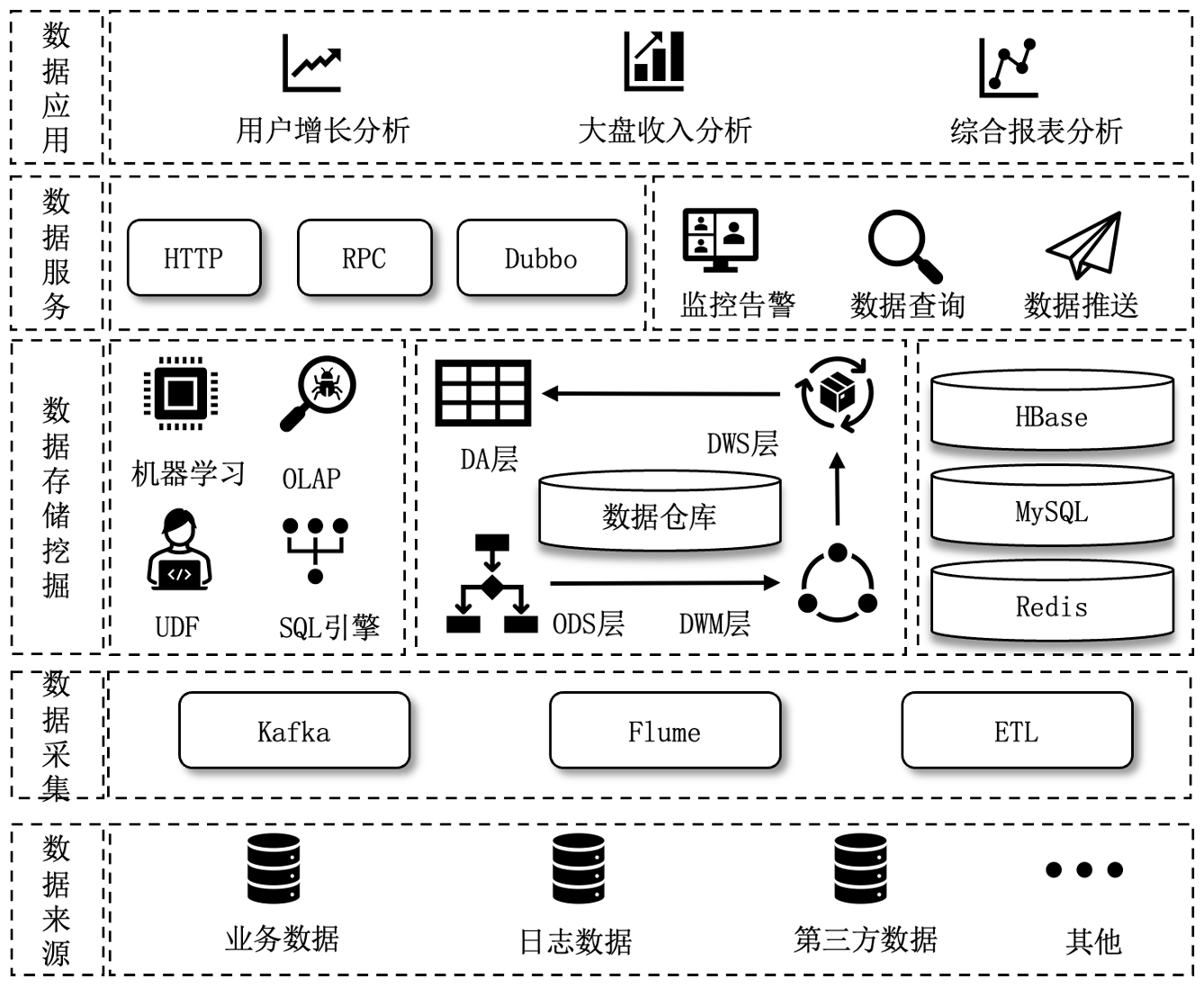
2.数据处理
数据处理是确保数据质量与一致性的关键步骤,旨在清洗原始数据中的噪声、错误和重复项,为后续分析奠定坚实基础。作为大数据分析流程中的核心环节,数据处理的质量直接影响分析结果的准确性和可靠性。
在处理过程中,常用的技术工具包括Hadoop的MapReduce框架、Spark SQL等,这些平台提供了丰富的函数库和高效的数据清洗方法,能够支撑大规模数据的快速处理。与此同时,机器学习方法也被广泛应用于数据处理环节,以提升自动化水平和精度。例如,聚类算法可以用于自动检测数据中的异常值,回归模型则可用于智能填补缺失数据。这些技术手段显著降低了人工干预的需求,提升了整个数据处理流程的效率和效果。
3.数据存储
数据存储是对采集到的数据进行分类管理的关键环节,旨在为后续的数据处理与分析提供高效、可靠的支撑。根据数据的结构化程度和应用需求,可选择不同的数据存储方案。
结构化数据通常存储在关系型数据库中,如MySQL。这类数据库通过表格化的数据模型、SQL查询语言与事务机制,保障了数据的一致性与完整性,适用于需要复杂查询、连接操作及事务支持的应用场景。
非结构化数据更适合存储在NoSQL数据库中,如HBase。NoSQL系统能够灵活处理文档、图像、日志等多种数据格式,支持弹性Schema设计与水平扩展,广泛应用于大规模数据存储、实时数据处理和高可用性场景。
在应对海量数据时,分布式存储系统显得尤为重要。Hadoop的分布式文件系统(HDFS)作为典型代表,通过数据分块并分散存储于多个节点,大幅提升了存储容量、访问速度与系统容错能力,即便部分节点故障也能实现数据自动恢复。
选择合适的存储方案时,需综合考虑数据类型、访问频率与存储成本。例如,针对频繁访问的热数据,可选用高性能存储方案,如固态硬盘(SSD)或内存数据库(如Redis),以实现高速读写;而对于访问频率较低的冷数据,则更适合采用成本更优的云存储解决方案,以提高长期存储的经济性。
数据备份与恢复机制同样是数据存储中不可忽视的重要保障,有效防范数据丢失或损坏的风险。常见备份策略包括:
- 全量备份:定期备份整个数据集,确保数据完整性;
- 增量备份:仅备份自上次备份以来发生变化的数据,节省空间与时间成本;
- 差异备份:备份自上次全量备份以来变化的数据,兼顾备份效率与恢复速度。
此外,通过引入定期备份、异地备份与快照技术,可进一步提升数据的安全性与可恢复性。多数云存储服务商还提供内置的自动备份与灾难恢复功能,为数据安全保驾护航。
4.数据分析
数据分析是通过多种算法与工具,对数据进行深入挖掘与解读,旨在提取有价值的信息与洞察,辅助科学决策。根据分析目标的不同,数据分析方法可分为描述性分析、诊断性分析、预测性分析和规范性分析,每种方法各具特色与应用场景。
- 描述性分析
- 描述性分析聚焦于总结与解释数据的基本特征。常用手段包括计算均值、中位数、标准差等统计量,并通过直方图、箱线图、散点图等可视化手段展示数据分布。该分析方法有助于理解数据的基本趋势和模式,是开展后续分析的基础。
- 诊断性分析
- 诊断性分析旨在探究数据中的关联关系与因果机制。通过相关性分析、回归分析等方法,可以识别变量之间的潜在联系,揭示问题成因,为预测性分析与规范性分析提供必要背景信息。
- 预测性分析
- 预测性分析利用历史数据与建模技术预测未来趋势。典型方法包括时间序列分析、回归模型及各类机器学习算法(如分类与回归模型、神经网络等)。高效的预测性分析不仅能洞察未来变化,还能支撑数据驱动的战略决策。
- 规范性分析
- 规范性分析致力于寻找最优决策方案,通常结合优化算法、决策树和模拟技术,推荐最优行动路径。此类分析不仅关注数据本身,还需要综合业务目标与约束条件,辅助决策者制定科学合理的行动方案。
在实际数据分析过程中,选择合适的方法与工具至关重要。对于大规模数据处理,分布式计算框架(如Hadoop、Spark)可显著提升计算效率与扩展能力;对于复杂分析任务,机器学习与深度学习算法(如线性回归、决策树、支持向量机、神经网络等)能够实现深层次的数据挖掘与洞察。
5.数据可视化
数据可视化是通过图表和视觉呈现方式,将复杂的数据分析结果直观表达,帮助用户更高效地理解数据内涵。作为数据分析流程中的关键环节,数据可视化不仅有助于识别模式和趋势,还能有效传达分析结论,辅助科学决策。
常用的数据可视化工具包括:
- ECharts:开源、高性能的图表库,支持多种图表类型和动态交互,广泛应用于交互性强的可视化仪表盘制作。
- Grafana:以实时监控和数据可视化见长,支持多数据源接入和丰富的插件扩展,常用于运维监控与业务指标展示。
- D3.js:基于JavaScript的强大可视化框架,拥有极高的自定义能力,适用于构建复杂、动态交互的高级可视化应用。
在可视化过程中,合理选择图表类型和设计风格至关重要:
- 时序数据:折线图、面积图,适合展示随时间变化的趋势和波动;
- 分类数据:柱状图、饼图,用于清晰呈现各类别的数量分布与比例关系;
- 地理数据:地图、热力图,展现不同地理区域的数据分布与变化。
良好的图表设计应遵循以下原则:
- 简洁:避免不必要的装饰,突出关键信息;
- 清晰:保证坐标轴、标签、图例等要素准确、易读;
- 突出重点:通过色彩、大小等视觉手段,强化关键数据和趋势。
此外,数据可视化设计还需充分结合用户需求与应用场景:
企业管理
- 面向高层管理者,仪表盘和实时看板是常见形式,聚焦关键绩效指标(KPI)和业务趋势,强调快速、直观的概览能力,支撑敏捷决策。
数据研究
- 面向分析人员,需提供交互式可视化功能,如下钻、筛选和动态探索,帮助深入挖掘数据细节,发现潜在规律与洞察。
综上所述,数据可视化不仅是将数据转化为视觉表现的过程,更是提升数据价值、增强分析洞察力与决策支持能力的重要手段。通过精心选择合适的图表类型与设计策略,结合具体的使用场景,数据可视化可以显著提升数据分析的效果与影响力。
3.数据挖掘算法
1.分类算法
分类算法是一类典型的有监督学习方法,旨在基于已有标注数据训练模型,以对新数据进行类别预测。分类技术广泛应用于金融风险评估、客户管理、医疗诊断等领域。常见的分类算法包括决策树(Decision Tree)、支持向量机(Support Vector Machine, SVM)、朴素贝叶斯(Naive Bayes)等,各有特点与适用场景。
- 决策树(Decision Tree)
- 决策树通过构建一系列基于特征的决策规则,将数据划分到不同类别中。其结构直观,易于理解,能够清晰展示决策过程。例如,在客户流失预测中,决策树可根据客户历史行为数据,识别出流失风险高的客户,辅助企业制定留存策略。
- 支持向量机(SVM)
- SVM通过构建最优分隔超平面,将样本划分到不同类别,特别适用于高维度、小样本数据场景。例如,在垃圾邮件过滤中,SVM能够根据邮件内容特征有效区分“垃圾邮件”与“正常邮件”,具有良好的分类性能。
- 朴素贝叶斯(Naive Bayes)
- 朴素贝叶斯基于贝叶斯定理,假设特征之间相互独立,虽然这一假设在实际应用中可能并不完全成立,但算法在文本分类、情感分析等领域表现优异。尤其适合用于对大规模数据进行快速、初步的分类处理。
分类算法的选择应综合考虑数据规模、特征维度、数据分布特性及应用需求,合理搭配模型可显著提升分类效果与应用价值。
2.预测算法
预测算法是一类有监督学习方法,旨在基于已有数据集训练模型,以预测未来的数值或类别。预测技术在金融、医疗、零售等多个领域有着广泛应用,如股票价格预测、销售量预测等。常见的预测算法包括线性回归、时间序列分析、决策树回归等。
- 线性回归(Linear Regression)
- 线性回归通过拟合一条最优直线,建模输入变量与目标变量之间的线性关系,适用于数据关系近似线性的场景。例如,在房地产市场中,可以基于历史房价、地理位置、建筑面积等特征,通过线性回归模型预测未来房价走势。
- 决策树回归(Decision Tree Regression)
- 决策树回归通过递归划分特征空间,捕捉数据中的复杂非线性关系,适合用于处理特征影响多样且关系复杂的预测任务。例如,在金融市场分析中,决策树回归能够根据多种经济指标和市场特征预测股票价格波动趋势,辅助投资决策。
预测算法的选择应根据数据特性(如线性或非线性)、噪声水平、数据量大小等因素综合考虑,从而提高模型的预测准确性和实用价值。
3.聚类分析
聚类分析是一种无监督学习算法,旨在根据数据自身的特征将数据划分为相似的组别。与监督学习不同,聚类不依赖于标记数据集,而是自动识别数据中的潜在模式。聚类分析广泛应用于市场细分、社交网络分析、图像处理等领域。常见的聚类算法包括K-means、层次聚类和密度聚类等。
- K-means
- K-means算法通过反复迭代,将数据点分配到离其最近的簇中心,并更新簇中心位置,直至聚类结果稳定。该算法广泛应用于市场细分,通过将客户分群,帮助企业根据不同群体的特点提供个性化的产品和服务。
- 层次聚类
- 层次聚类通过逐步合并(自底向上)或分割(自顶向下)数据点,构建一棵聚类树(树状图)。这种方法能很好地展示数据点之间的层次结构,适用于探索性数据分析。
- 密度聚类
- 密度聚类通过识别数据点的密度差异,能够有效处理形状不规则的簇和噪声数据。例如,DBSCAN(密度基聚类算法)能够识别任意形状的簇,且对噪声点具有较强的鲁棒性,适用于地理数据或异常检测。
聚类算法的选择需根据数据的特点、簇的形状、噪声水平等因素进行合理评估,从而实现最优的聚类效果。
4.关联分析
关联分析是一种无监督学习算法,旨在发现数据中的潜在关联关系。通过分析频繁项集,关联分析揭示了项集之间的规律性关系。该方法广泛应用于零售业、金融业等领域,如购物分析和欺诈检测。常见的关联分析算法包括Apriori和FP-Growth等。
- Apriori
- Apriori算法通过挖掘频繁项集来发现数据中的关联规则。其基本思想是通过逐层筛选,找出频繁出现的项集,再基于这些项集生成关联规则。在零售行业中,Apriori可以帮助超市识别“经常一起购买”的商品组合,进而优化商品陈列和促销策略。
- FP-Growth
- FP-Growth算法与Apriori相似,但通过构建频繁模式树(FP-Tree)来挖掘频繁项集,相比Apriori,FP-Growth算法在大规模数据集上更为高效。在电子商务领域,FP-Growth能够分析用户购买行为,帮助平台实现精准的商品推荐,提高用户体验和销售转化率。
关联分析不仅在单一场景下有效,在实际应用中,往往需要将多种算法结合使用以提升分析效果。例如,市场细分中,首先使用聚类算法对客户进行分群,再利用分类算法细分每个群体,最后通过关联分析发现群体间的关联关系。综合运用这些算法,可以全面深入地挖掘数据中的知识和价值。
在实际数据分析中,常常需要将多种数据挖掘算法结合使用,以获得更全面的洞察。例如,在市场细分中,首先可以使用聚类算法将客户划分为不同的群体;接着,使用分类算法对每个群体进行进一步细分,以识别不同类别之间的差异和特点;最后,运用关联分析算法发现各群体之间的潜在关系,如商品购买模式或消费行为的相互影响。
通过这种综合应用,能够更深入地挖掘数据中的潜在价值,不仅提高了分析的精度和效率,还能帮助企业在复杂的业务环境中做出更加科学和个性化的决策。例如,电商平台可以结合这些算法优化推荐系统、精准营销以及库存管理,从而提升用户体验和增加销售额。
4.大数据挖掘算法及其实现原理
1.决策树算法
决策树是一种常用于分类和回归任务的监督学习算法。它通过递归划分数据集,构建一棵树状结构,节点代表特征的判定,而叶子节点则表示最终的决策结果。决策树的关键在于选择最优的划分特征,常用的划分标准包括信息增益、信息增益率和基尼指数。
- 信息增益
- 信息增益衡量通过某一特征划分数据集后,不确定性(熵)的减少程度。信息增益越大,表示该特征对分类越有用。
- 信息增益率
- 信息增益率考虑了特征的取值数量,避免信息增益偏向于具有大量取值的特征。信息增益率越高,表明该特征具有更好的划分效果。
- 基尼指数
- 基尼指数表示从数据集中随机选取两个样本,它们的类别不同的概率。基尼指数越小,表示数据集中的样本越纯,决策效果越好。
决策树算法的优点在于其易于理解和可解释性强,但它也容易受到过拟合的影响,因此通常需要通过剪枝或其他方法进行优化。
实现示例代码如下:
public class JavaDecisionTreeClassificationExample {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf()
.setAppName("JavaDecisionTreeClassificationExample")
.setMaster("local");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
// 加载并解析数据文件
String datapath = "data/mllib/sample_libsvm_data.txt";
JavaRDD<LabeledPoint> data = MLUtils
.loadLibSVMFile(jsc.sc(), datapath).toJavaRDD();
// 将数据分割成训练集和测试集(30%作为测试集)
JavaRDD<LabeledPoint>[] splits = data.randomSplit(new double[]{0.7, 0.3});
JavaRDD<LabeledPoint> trainingData = splits[0]; // 训练数据
JavaRDD<LabeledPoint> testData = splits[1]; // 测试数据
// 设置参数
// 空的categoricalFeaturesInfo表示所有特征都是连续的
int numClasses = 2;
Map<Integer, Integer> categoricalFeaturesInfo = new HashMap<>();
// 用于决策树节点划分的不纯度度量标准
String impurity = "gini";
// 决策树的最大深度
int maxDepth = 5;
// 用于表示特征的桶的数量
int maxBins = 32;
// 训练一个用于分类的决策树模型
DecisionTreeModel model = DecisionTree
.trainClassifier(trainingData, numClasses,
categoricalFeaturesInfo, impurity, maxDepth, maxBins);
// 在测试实例上评估模型并计算测试误差
JavaPairRDD<Double, Double> predictionAndLabel =
testData.mapToPair(p ->
new Tuple2<>(model.predict(p.features()), p.label()));
double testErr =
predictionAndLabel.filter(pl -> !pl._1().equals(pl._2()))
.count() / (double) testData.count();
System.out.println("Test Error: " + testErr);
System.out.println("Learned classification tree model:\n"
+ model.toDebugString());
// 保存和加载模型
model.save(jsc.sc(), "target/tmp/myDecisionTreeClassificationModel");
DecisionTreeModel sameModel = DecisionTreeModel
.load(jsc.sc(), "target/tmp/myDecisionTreeClassificationModel");
}
}
2.随机森林算法
随机森林是一种集成学习方法,通过构建多个决策树来提高模型的预测性能。它通过引入随机性来解决决策树易过拟合的问题,具体体现在两个方面:
- 随机选择样本:每棵树使用从原始数据集中随机抽取的样本(有放回抽样),即所谓的自助法(Bootstrap)。
- 随机选择特征:在每个节点划分时,随机选择特征的子集进行决策,避免单一特征过于影响模型。
- 最终,随机森林的预测结果通过对所有决策树的输出进行投票(分类问题)或均值(回归问题)来决定。
适用场景
随机森林特别适用于以下应用场景:
- 高维数据分类:如文本分类,特别是在特征数量庞大的情况下表现良好。
- 异常检测:例如在金融领域的信用卡欺诈检测中,能够有效识别不正常的交易模式。
- 回归分析:如股票价格预测,可以利用多个决策树的预测结果,提升回归精度。
随机森林的优势在于其高准确性、鲁棒性以及对过拟合的有效抑制,使其在许多实际应用中广泛使用。
实现示例代码如下:
public class JavaRandomForestClassificationExample {
public static void main(String[] args) {
// 创建Spark应用的配置对象,设置应用名称和运行模式(本地模式)
SparkConf sparkConf = new SparkConf()
.setAppName("JavaRandomForestClassificationExample")
.setMaster("local");
// 创建JavaSparkContext对象,用于与Spark集群进行交互
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
// 加载并解析数据文件
String datapath = "data/mllib/sample_libsvm_data.txt"; // 数据文件路径
JavaRDD<LabeledPoint> data = MLUtils
.loadLibSVMFile(jsc.sc(), datapath).toJavaRDD(); // 读取数据并转换为JavaRDD
// 将数据随机分割为训练集和测试集(70%用于训练,30%用于测试)
JavaRDD<LabeledPoint>[] splits = data.randomSplit(new double[]{0.7, 0.3});
JavaRDD<LabeledPoint> trainingData = splits[0]; // 训练数据
JavaRDD<LabeledPoint> testData = splits[1]; // 测试数据
// 训练一个随机森林分类模型
// 空的categoricalFeaturesInfo表示所有特征都是连续的
int numClasses = 2; // 类别数,二分类问题
// 特征信息,这里为空,表示所有特征都是连续的
Map<Integer, Integer> categoricalFeaturesInfo = new HashMap<>();
int numTrees = 3; // 树的数量,实际应用中应该更多
String featureSubsetStrategy = "auto"; // 特征子集策略,让算法自动选择
String impurity = "gini"; // 用于树节点划分的不纯度度量标准
int maxDepth = 5; // 树的最大深度
int maxBins = 32; // 用于表示特征的桶的数量
int seed = 12345; // 随机种子,用于结果的可重复性
// 使用训练数据训练随机森林模型
RandomForestModel model = RandomForest
.trainClassifier(trainingData, numClasses,
categoricalFeaturesInfo, numTrees,
featureSubsetStrategy,
impurity, maxDepth, maxBins,
seed);
// 在测试数据上评估模型,并计算测试误差
// 将测试数据的特征和模型预测的标签组合在一起
JavaPairRDD<Double, Double> predictionAndLabel =
testData.mapToPair(p ->
new Tuple2<>(model.predict(p.features()), p.label()));
// 计算测试误差
double testErr =
predictionAndLabel.filter(pl -> !pl._1().equals(pl._2()))
.count() / (double) testData.count();
// 打印测试误差和学习到的随机森林模型的详细信息
System.out.println("Test Error: " + testErr);
System.out.println("Learned classification forest model:\n"
+ model.toDebugString());
// 将模型保存到指定路径
model.save(jsc.sc(), "target/tmp/myRandomForestClassificationModel");
// 从指定路径加载模型
RandomForestModel sameModel = RandomForestModel.load(jsc.sc(),
"target/tmp/myRandomForestClassificationModel");
// 停止JavaSparkContext对象
jsc.stop();
}
}
3.K均值聚类算法
K均值聚类(K-means)是一种无监督学习算法,用于将数据集划分为k个互不重叠的子集(簇)。算法的目标是通过迭代优化簇的中心点(质心),使得每个簇内样本与质心的距离总和最小。
算法步骤
- 初始化质心:随机选择k个点作为初始质心。
- 分配样本:将每个样本分配给与其最近的质心所对应的簇。
- 更新质心:重新计算每个簇的质心,即取簇内所有样本点的均值。
- 迭代:重复步骤2和3,直到质心不再变化或达到最大迭代次数。
K均值聚类的效果较大程度依赖于k值的选择。常用方法包括“肘部法则”来确定最优的k值。
适用场景
K均值聚类适用于以下应用场景:
- 市场细分:根据客户的购买行为将其分成不同群体,从而有针对性地制定营销策略。
- 图像压缩:通过将图像中的像素分为不同的颜色簇,减少颜色数量,从而实现压缩效果。
- 文档聚类:将文档聚集成不同类别或主题,帮助发现潜在的主题结构。
K均值聚类简单高效,尤其在处理大规模数据时表现出色,但其对初始质心的选择和k值的设定敏感。
实现示例代码如下:
public class JavaKMeansExample {
public static void main(String[] args) {
// 创建Spark应用的配置对象,设置应用名称和运行模式(本地模式)
SparkConf conf = new SparkConf().setAppName("JavaKMeansExample")
.setMaster("local");
// 创建JavaSparkContext对象,用于与Spark集群进行交互
JavaSparkContext jsc = new JavaSparkContext(conf);
// 加载并解析数据
// 数据文件路径
String path = "data/mllib/kmeans_data.txt";
// 读取文本文件并创建一个JavaRDD
JavaRDD<String> data = jsc.textFile(path);
JavaRDD<Vector> parsedData = data.map(s -> {
String[] sarray = s.split(" "); // 按空格分割每行数据
// 创建一个用于存储数值的数组
double[] values = new double[sarray.length];
for (int i = 0; i < sarray.length; i++) {
// 将字符串转换为双精度浮点数
values[i] = Double.parseDouble(sarray[i]);
}
return Vectors.dense(values); // 创建稠密向量
});
parsedData.cache(); // 缓存处理后的数据
// 使用KMeans算法对数据进行聚类
int numClusters = 2; // 聚类数量
int numIterations = 20; // 迭代次数
// 训练KMeans模型
KMeansModel clusters = KMeans
.train(parsedData.rdd(), numClusters, numIterations);
// 打印聚类中心
System.out.println("Cluster centers:");
for (Vector center: clusters.clusterCenters()) {
System.out.println(" " + center);
}
// 计算模型的成本
double cost = clusters.computeCost(parsedData.rdd());
System.out.println("Cost: " + cost);
// 计算Within Set Sum of Squared Errors(WSSSE)来评估聚类效果
double WSSSE = clusters.computeCost(parsedData.rdd());
System.out.println("Within Set Sum of Squared Errors = " + WSSSE);
// 将模型保存到指定路径
clusters.save(jsc.sc(),
"target/org/apache/spark/JavaKMeansExample/KMeansModel");
// 从指定路径加载模型
KMeansModel sameModel = KMeansModel.load(jsc.sc(),
"target/org/apache/spark/JavaKMeansExample/KMeansModel");
// 停止JavaSparkContext对象
jsc.stop();
}
}
4.Apriori算法
Apriori算法是一种经典的关联规则挖掘算法,广泛应用于处理事务型数据(如超市购物篮分析)。该算法基于“先验”原理:如果一个项集是频繁的,那么它的所有子集也必然是频繁的。
核心步骤
- 生成候选项集:从k-1项频繁项集中生成k项候选项集。
- 剪枝:移除不满足最小支持度阈值的候选项集。
- 生成关联规则:从频繁项集中生成满足最小置信度的关联规则。
Apriori算法的主要瓶颈是其需要多次扫描数据集,尤其在大数据集上效率较低。因此,FP-Growth等改进算法被提出,以提高挖掘效率。
适用场景
Apriori算法适用于以下场景:
- 网络安全:通过分析网络日志,发现异常模式,帮助预防或检测安全威胁。例如,入侵检测系统可以通过Apriori算法发现异常的网络行为模式。
- 金融领域:分析客户交易数据,识别潜在的欺诈行为模式,帮助金融机构进行风险管理。
Apriori算法能够发现数据中的潜在关联关系,但在大规模数据集上的性能较为有限。
实现示例代码如下:
public class JavaSimpleFPGrowth {
public static void main(String[] args) {
// 创建Spark应用的配置对象,设置应用名称和运行模式(本地模式)
SparkConf conf = new SparkConf()
.setAppName("FP-growth Example") // 设置应用名称
.setMaster("local"); // 设置运行模式为本地模式
// 创建JavaSparkContext对象,用于与Spark集群进行交互
JavaSparkContext sc = new JavaSparkContext(conf);
// $example on$
// 读取数据文件,并创建一个JavaRDD对象
JavaRDD<String> data = sc.textFile("data/mllib/sample_fpgrowth.txt");
// 将数据文件中的每一行文本映射为一个由商品组成的列表
JavaRDD<List<String>> transactions =
data.map(line -> Arrays.asList(line.split(" ")));
// 创建一个FP-growth模型对象,并设置最小支持度为0.2,分区数为10
FPGrowth fpg = new FPGrowth()
.setMinSupport(0.2) // 设置最小支持度阈值
.setNumPartitions(10); // 设置分区数
// 运行FP-growth算法,生成模型
FPGrowthModel<String> model = fpg.run(transactions);
int count = 0;
// 遍历模型中的频繁项集,并打印每个项集及其支持度
for (FPGrowth.FreqItemset<String> itemset :
model.freqItemsets().toJavaRDD().collect()) {
count++;
if (count > 5) {
break;
}
System.out.println("[" + itemset.javaItems() + "], "
+ itemset.freq());
}
// 设置最小置信度为0.8,并生成关联规则
double minConfidence = 0.8;
for (AssociationRules.Rule<String> rule
: model.generateAssociationRules(minConfidence)
.toJavaRDD().collect()) {
count++;
if (count > 5) {
break;
}
// 打印每个关联规则及其置信度
System.out.println(
rule.javaAntecedent() + " => "
+ rule.javaConsequent() + ", "
+ rule.confidence());
}
// 停止JavaSparkContext对象
sc.stop();
}
}
5.总结
本篇博客深入探讨了数据分析与挖掘的核心技术,涵盖了大数据分析流程、数据挖掘算法和特征工程的实际应用。通过具体案例,详细解析了数据挖掘算法如何从复杂的数据中提取有价值的洞察,特征工程如何优化数据特征以提升模型性能,以及大数据分析如何高效处理海量数据,揭示其中潜在的趋势和模式。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出新书了《Hadoop与Spark大数据全景解析》、同时已出版的《深入理解Hive》、《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》也可以和新书配套使用,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
Hadoop和Spark大数据挖掘与实战的更多相关文章
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 顶尖大数据挖掘实战平台(TipDM-H8)产品白皮书
顶尖大数据挖掘实战平台 (TipDM-H8) 产 品 说 明 书 广州泰迪智能科技有限公司 版权所有 地址: 广州市经济技术开发区科学城232号 网址: http: ...
- Hadoop大数据挖掘从入门到进阶实战
1.概述 大数据时代,数据的存储与挖掘至关重要.企业在追求高可用性.高扩展性及高容错性的大数据处理平台的同时还希望能够降低成本,而Hadoop为实现这些需求提供了解决方案.面对Hadoop的普及和学习 ...
- 大数据 Hadoop,Spark和Storm
大数据(Big Data) 大数据,官方定义是指那些数据量特别大.数据类别特别复杂的数据集,这种数据集无法用传统的数据库进行存储,管理和处理.大数据的主要特点为数据量大(Volume),数据类别复 ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 大数据hadoop与spark的区别
学习hadoop已经有很长一段时间了,好像是二三月份的时候朋友给了一个国产Hadoop发行版下载地址,因为还是在学习阶段就下载了一个三节点的学习版玩一下.在研究.学习hadoop的朋友可以去找一下看看 ...
- 大数据学习系列之Hadoop、Spark学习线路(想入门大数据的童鞋,强烈推荐!)
申明:本文出自:http://www.cnblogs.com/zlslch/p/5448857.html(该博客干货较多) 1 Java基础: 视频方面: 推荐<毕向东JAVA ...
- 量化派基于Hadoop、Spark、Storm的大数据风控架构--转
原文地址:http://www.csdn.net/article/2015-10-06/2825849 量化派是一家金融大数据公司,为金融机构提供数据服务和技术支持,也通过旗下产品“信用钱包”帮助个人 ...
- Python3实战Spark大数据分析及调度 (网盘分享)
Python3实战Spark大数据分析及调度 搜索QQ号直接加群获取其它学习资料:715301384 部分课程截图: 链接:https://pan.baidu.com/s/12VDmdhN4hr7yp ...
- [转帖]大数据hadoop与spark的区别
大数据hadoop与spark的区别 https://www.cnblogs.com/adnb34g/p/9233906.html Posted on 2018-06-27 14:43 左手中倒影 阅 ...
随机推荐
- 关于galaxy戒色的通知
明天开始--一小段时间内辅以半退网 如果想打胶 就做100个卷腹 睡不着就吃褪黑素 恁还是多写写诗吧,恁现在这个精虫上脑的脑子连意识流都扛不住 恁还想写<阑山><莲天>< ...
- 一个SQL就让内存耗光了
一个SQL内存为什么就没了呢 最近遇到一个故障,研发新上线一个功能,成功把主机内存耗光,导致实例重启.复现一个SQL如何把数据库的内存耗光. 实验环境 Oracle Database 19c(故障发生 ...
- 15. Docker容器监控之(CAdvisor+InfluxDB+Granfana)的详细安装和常规使用
15. Docker容器监控之(CAdvisor+InfluxDB+Granfana)的详细安装和常规使用 @ 目录 15. Docker容器监控之(CAdvisor+InfluxDB+Granfan ...
- SpringBoot 2.x 接入非标准SSE格式大模型流式响应实践 🚀
近期DeepSeek等国产大模型热度持续攀升,其关注度甚至超过了OpenAI(被戏称为CloseAI).在SpringBoot3.x环境中,可以使用官方的Spring AI轻松接入,但对于仍在使用JD ...
- 13. MySQL 事务基础知识(详细说明实操剖析)
13. MySQL 事务基础知识(详细说明实操剖析) @ 目录 13. MySQL 事务基础知识(详细说明实操剖析) 1. 数据库事务概述 1.1 存储引擎支持情况 1.2 事务基本概念 1.3 事务 ...
- 最新版go-cqhttp的sign 签名服务器搭建教程
安装go-cqhttp 传送门 自建sign签名服务器容器: 拉取镜像(只支持amd64) docker pull hansaes/unidbg-fetch-qsign:latest 启动容器 doc ...
- zabbix - [03] 安装部署
参考:https://www.yuque.com/fenghuo-tbnd9/ffmkvs zabbix6要求操作系统为Centos8,所以一开始安装部署的时候发现少了zabbix-server-my ...
- 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
从 Chrome 125 开始,支持了一个全新的 CSS 特性 - Anchor Positioning,翻译过来即是锚点定位. 在之前的文章中,我们较为系统的讲述了这个新特性的使用,感兴趣的可以翻开 ...
- 面试题 17.12. BiNode
地址:https://leetcode-cn.com/problems/binode-lcci/ <?php /** 二叉树数据结构TreeNode可用来表示单向链表(其中left置空,righ ...
- Feedalyze - 让你听得见、听得清用户的反馈
满足用户需求,解决用户问题,获得适当报酬是商业成功最为重要的因素.然而扪心自问,当您推出新产品后,您真的在听.听得见.听得清用户的反馈么? 当今信息传播迅猛,渠道繁多,优秀产品随口碑效应供不应求,劣质 ...