使用自己的域名解析cnblogs博客(CSDN也可以)
本文主要介绍怎样使用自己购买的域名指向cnblogs博客
通常来说技术人员都会创建个自己的技术博客,总结下工作中的问题,经验等等,不过某些博客的访问链接的确是不太容易记忆或者输入,对我们分享造成一定的困扰,本文通过配置github page静态页面的功能,跳转到指定的博客地址来解决这个问题。
(直接配置域名解析到博客地址无法访问)
实现原理:
用户访问--->阿里云解析--->github page跳转--->真实的博客地址
1.创建github page静态页面跳转进行访问博客地址
1.1.创建github账号
https://github.com
1.2.建立一个以账号名开始的仓库
命名格式:[账号名.github.io],如下:
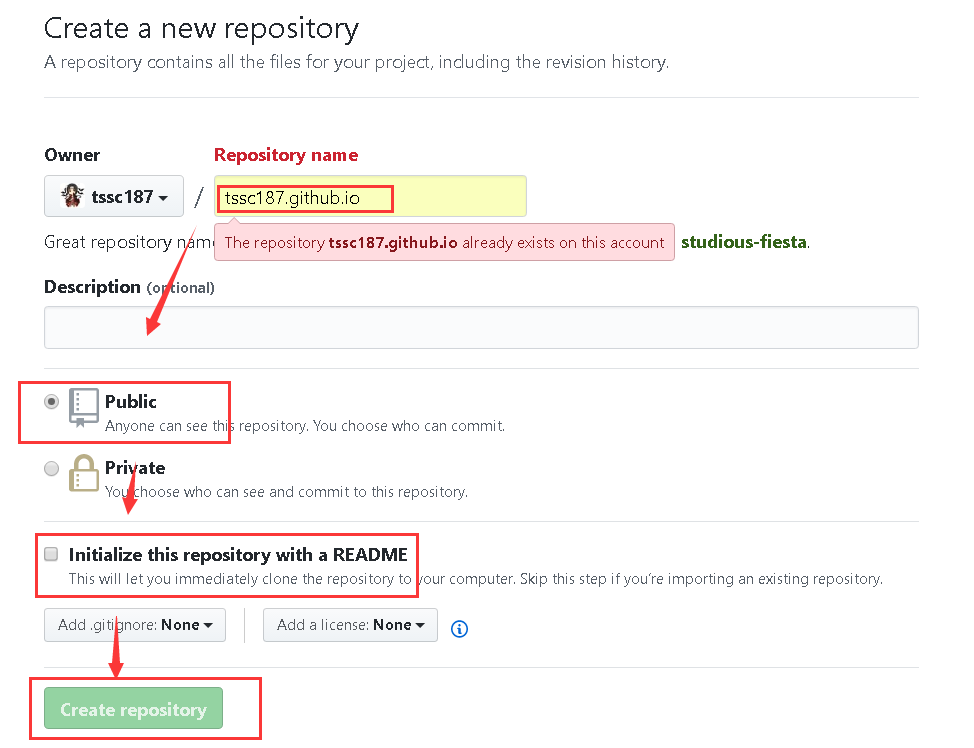
我这个已经创建了,选择public项目,可以选择初始化一些配置文件,之后直接创建仓库就行
1.3.创建静态页面指向博客真实地址
创建静态页面文件“index.html”

index.html 文件内容如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
<style media="screen">
* {
margin: ;
padding: ;
}
</style>
</head>
<body>
</body>
<script type="text/javascript">
window.location.href="http://www.cnblogs.com/tssc"; // 将这个地址修改成需要的博客地址
</script>
</html>
该文件文件创建完成,即可使用上面创建好的仓库域名链接访问对应的博客,证明github到博客的链路已经通了
https://tssc187.github.io
如果返回404,可能需要检查index.html配置,或者等待github后台进行解析
2.配置域名解析指向github page页面
配置域名解析,我这个是阿里云的域名,按照下面的事例进行域名解析配置,记录类型需要配置为别名cname

域名配置完成,检查下是否解析成功
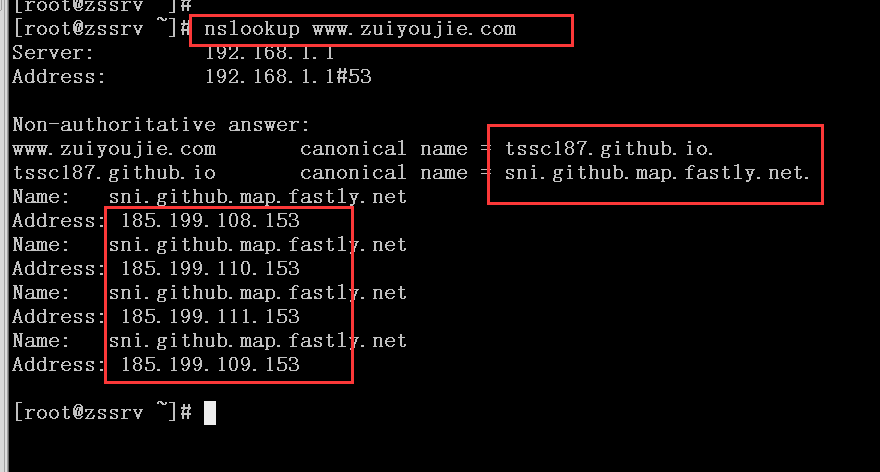
如上图,解析已经成功,阿里云可以访问到github,但是github并没有设置好接收阿里云的访问请求,接下来就解决这个问题
3.配置github page接受阿里云域名解析
在仓库中创建名称为“CNAME”的域名解析文件,内容为阿里云解析的域名
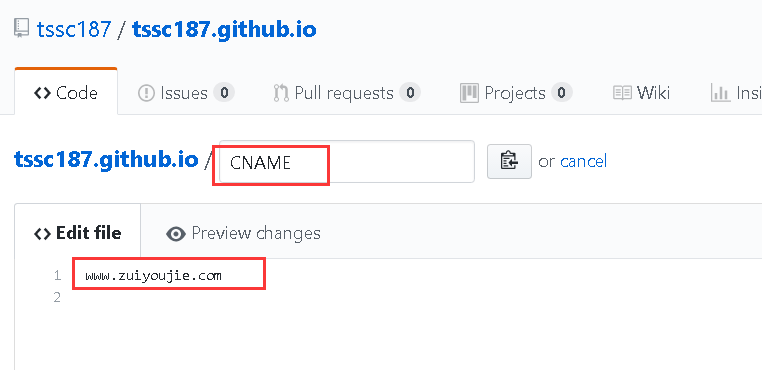
以上配置完成,整个通道就完全打通,就可以使用自己的域名www.zuiyoujie.com访问博客了
完毕,呵呵呵呵
使用自己的域名解析cnblogs博客(CSDN也可以)的更多相关文章
- 使用自己的域名解析 cnblogs 博客
使用自己的域名解析 cnblogs 博客(博客园) 1.实现原理 用户访问 -> 阿里云解析 -> github page 跳转 -> 真实的博客地址 2.创建 github pag ...
- docker 安装redis 并配置外网可以访问 - flymoringbird的博客 - CSDN博客
原文:docker 安装redis 并配置外网可以访问 - flymoringbird的博客 - CSDN博客 端口映射,data目录映射,配置文件映射(在当前目录下进行启动). docker run ...
- 把cnblogs变成简书 - cnblogs博客自定义皮肤css样式
吐槽 博客园cnblogs作为老牌的IT技术博客类网站,为广大的开发者提供了非常不错的学习交流平台. 虽然博客内容才是重点,但是如果有赏心悦目的页面不更好吗! cnblogs可以更换博客模板,并且提供 ...
- cnblogs博客申请完毕,以后再这里安家落户
cnblogs博客申请完毕,以后再这里安家落户,之前的博客就不转载了,好好搞技术,安稳过日子.
- 微服务架构的分布式事务解决方案 - zhaorui2017的博客 - CSDN博客
微服务架构的分布式事务解决方案 - zhaorui2017的博客 - CSDN博客 http://blog.csdn.net/zhaorui2017/article/details/7643679 ...
- 开源的服务发现项目Zookeeper,Doozer,Etcd - 木精灵的技术博客 - CSDN博客
开源的服务发现项目Zookeeper,Doozer,Etcd - 木精灵的技术博客 - CSDN博客 http://blog.csdn.net/shlazww/article/details/38 ...
- cnblogs博客迁移到hexo
cnblogs博客备份 备份地址:https://i.cnblogs.com/BlogBackup.aspx?type=1 备份文件为xml格式,打开备份文件,如下所示: <?xml versi ...
- FFMPEG推流到RTMP服务器命令 - weixin_37897683的博客 - CSDN博客 https://blog.csdn.net/weixin_37897683/article/details/81225228
FFMPEG推流到RTMP服务器命令 - weixin_37897683的博客 - CSDN博客 https://blog.csdn.net/weixin_37897683/article/detai ...
- 利用Word发布文章到cnblogs博客
利用Word发布文章到cnblogs博客 用博客园cnblogs:http://www.cnblogs.com/博客名称/services/metablogapi.aspx,word老是提醒" ...
随机推荐
- c++ 二分法查找(binary_search)
#include <iostream> // cout #include <algorithm> // binary_search, sort #include <vec ...
- Android JNI学习(三)——Java与Native相互调用
本系列文章如下: Android JNI(一)——NDK与JNI基础 Android JNI学习(二)——实战JNI之“hello world” Android JNI学习(三)——Java与Nati ...
- 【Jmeter】Linux(Mac)上使用最新版本Jmeter(5.0)做性能测试
本文我们一起来学习在Linux(Mac)上利用Jmeter进行性能测试并生成测试报告的方法. 环境准备 JDK 访问这个地址 [JDK11.01],根据实际环境下载一个JDK. Jmeter Jmet ...
- NHibernate 映射关系
基本映射关系如下: NHibernate类型 .NET类型 Database类型 备注 AnsiChar System.Char DbType.AnsiStringFixedLength - 1 ch ...
- 慕课网Hibernate初探之一对多映射实验及总结
慕课网Hibernate初探之一对多映射实验及总结 一.本课核心 * 1.如何在MyEclipse中使用Hibernate * 2.如何实现Hibernate中一对多的映射 * 3.如何创建Sessi ...
- delphi文件名获取方法
取文件名 ExtractFileName(FileName); 取文件扩展名: ExtractFileExt(filename); 取文件名,不带扩展名: 方法一: Function Extrac ...
- codeforces 853b//Jury Meeting// Codeforces Round #433 (Div. 1)
题意:几个人要去一个城市k天,现给出各航班的日期和花费,让这n个人能相会k天的最小花费? 用数组arr1[i]记录在第i天人到齐的最小花费.arr2[i]记录第i天之后才有人开始走的最小花费.然后取a ...
- Skills CodeForces - 614D (贪心)
链接 大意: $n$门课, 第$i$门分数$a_i$, 可以增加共$m$分, 求$cnt_{mx}*cf+mi*cm$的最大值 $cnt_{mx}$为满分的科目数, $mi$为最低分, $cf$, $ ...
- 『cs231n』线性分类器损失函数
代码部分 SVM损失函数 & SoftMax损失函数: 注意一下softmax损失的用法: SVM损失函数: import numpy as np def L_i(x, y, W): ''' ...
- 使用a标签实现软件下载及下载量统计
通常最简单的软件下载就是采用如下方式: <a id="welcomeMiddleBtn" href="${basePath}/files/client/instal ...