基于SVM的鸢尾花数据集分类实现[使用Matlab]
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
数据的获取:
file=importdata('iris.csv');%读取csv文件中从第R-1行,第C-1列的数据开始的数据
data=file.data;
features=data(:,:);%特征列表
classlabel=data(:,);%对应类别
n = randperm(size(features,));%随机产生训练集和测试集
绘制散点图查看数据:
%% 绘制散点图
class_0 = find(data(:,)==);
class_1 = find(data(:,)==);
class_2 = find(data(:,)==);%返回类别为2的位置索引
subplot(,,)
hold on
scatter(features(class_0,),features(class_0,),'x','b')
scatter(features(class_1,),features(class_1,),'+','g')
scatter(features(class_2,),features(class_2,),'o','r')
subplot(,,)
hold on
scatter(features(class_0,),features(class_0,),'x','b')
scatter(features(class_1,),features(class_1,),'+','g')
scatter(features(class_2,),features(class_2,),'o','r')
subplot(,,)
hold on
scatter(features(class_0,),features(class_0,),'x','b')
scatter(features(class_1,),features(class_1,),'+','g')
scatter(features(class_2,),features(class_2,),'o','r')
subplot(,,)
hold on
scatter(features(class_0,),features(class_0,),'x','b')
scatter(features(class_1,),features(class_1,),'+','g')
scatter(features(class_2,),features(class_2,),'o','r')
subplot(,,)
hold on
scatter(features(class_0,),features(class_0,),'x','b')
scatter(features(class_1,),features(class_1,),'+','g')
scatter(features(class_2,),features(class_2,),'o','r')
subplot(,,)
hold on
scatter(features(class_0,),features(class_0,),'x','b')
scatter(features(class_1,),features(class_1,),'+','g')
scatter(features(class_2,),features(class_2,),'o','r')
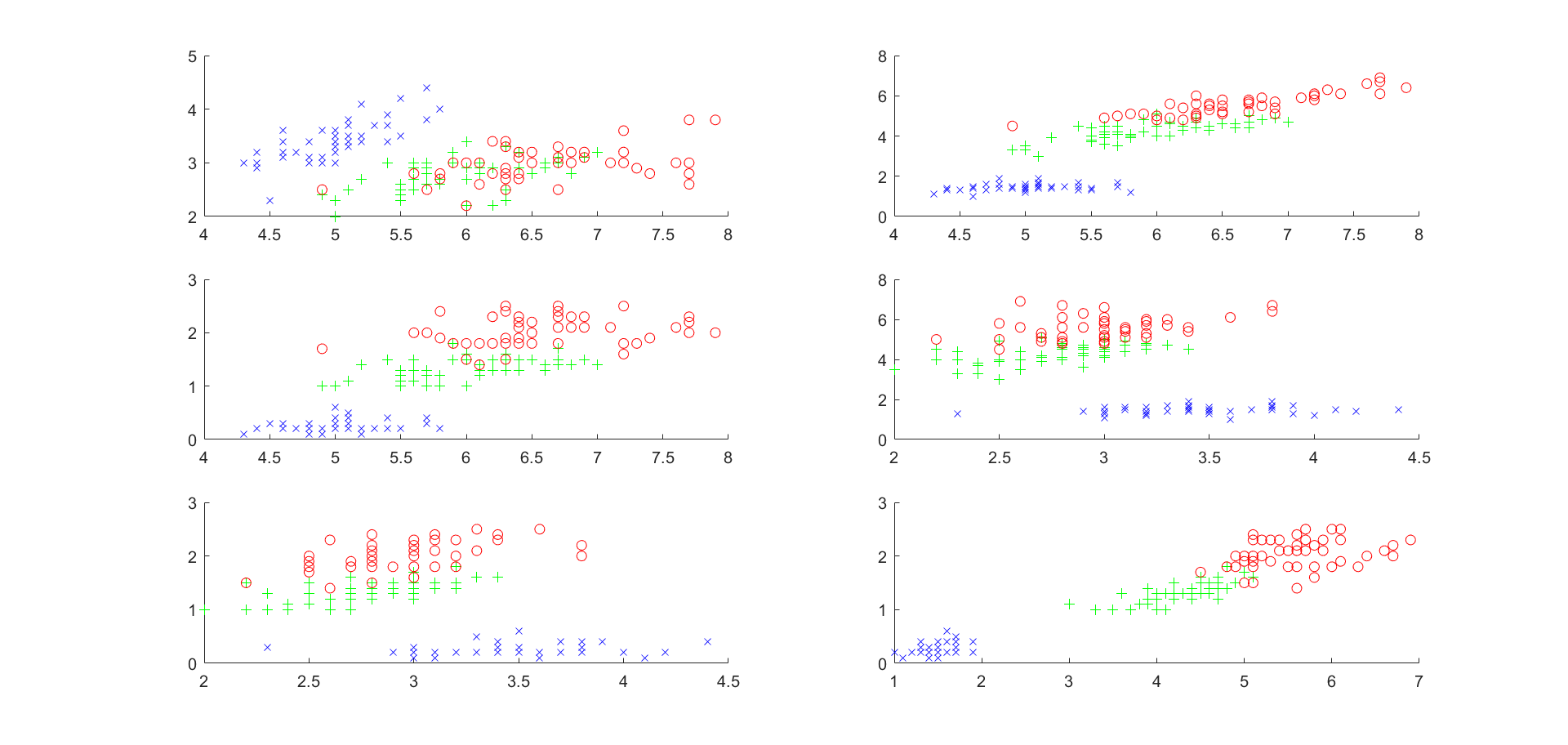
曲线为根据花萼长度、花萼宽度、花瓣长度、花瓣宽度之间的关系绘制的散点图。
训练集与测试集:
%% 训练集--70个样本
train_features=features(n(:),:);
train_label=classlabel(n(:),:);
%% 测试集--30个样本
test_features=features(n(:end),:);
test_label=classlabel(n(:end),:);
数据归一化:
%% 数据归一化
[Train_features,PS] = mapminmax(train_features');
Train_features = Train_features';
Test_features = mapminmax('apply',test_features',PS);
Test_features = Test_features';
使用SVM进行分类:
%% 创建/训练SVM模型
model = svmtrain(train_label,Train_features);
%% SVM仿真测试
[predict_train_label] = svmpredict(train_label,Train_features,model);
[predict_test_label] = svmpredict(test_label,Test_features,model);
%% 打印准确率
compare_train = (train_label == predict_train_label);
accuracy_train = sum(compare_train)/size(train_label,)*;
fprintf('训练集准确率:%f\n',accuracy_train)
compare_test = (test_label == predict_test_label);
accuracy_test = sum(compare_test)/size(test_label,)*;
fprintf('测试集准确率:%f\n',accuracy_test)
结果:
*
optimization finished, #iter = 18
nu = 0.668633
obj = -21.678546, rho = 0.380620
nSV = 30, nBSV = 28
*
optimization finished, #iter = 29
nu = 0.145900
obj = -3.676315, rho = -0.010665
nSV = 9, nBSV = 4
*
optimization finished, #iter = 21
nu = 0.088102
obj = -2.256080, rho = -0.133432
nSV = 7, nBSV = 2
Total nSV = 40
Accuracy = 97.1429% (68/70) (classification)
Accuracy = 97.5% (78/80) (classification)
训练集准确率:97.142857
测试集准确率:97.500000
基于SVM的鸢尾花数据集分类实现[使用Matlab]的更多相关文章
- Python实现鸢尾花数据集分类问题——基于skearn的SVM
Python实现鸢尾花数据集分类问题——基于skearn的SVM 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = 'Xiaoli ...
- Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes
Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = ...
- Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression
Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression 一. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题, ...
- python实现HOG+SVM对CIFAR-10数据集分类(上)
本博客只用于学习,如果有错误的地方,恳请指正,如需转载请注明出处. 看机器学习也是有一段时间了,这两天终于勇敢地踏出了第一步,实现了HOG+SVM对图片分类,具体代码可以在github上下载,http ...
- Python实现鸢尾花数据集分类问题——使用LogisticRegression分类器
. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法. 概率p与因变量往 ...
- ML学习笔记之XGBoost实现对鸢尾花数据集分类预测
import xgboost as xgb import numpy as np import pandas as pd from sklearn.model_selection import tra ...
- 基于SKLearn的SVM模型垃圾邮件分类——代码实现及优化
一. 前言 由于最近有一个邮件分类的工作需要完成,研究了一下基于SVM的垃圾邮件分类模型.参照这位作者的思路(https://blog.csdn.net/qq_40186809/article/det ...
- 做一个logitic分类之鸢尾花数据集的分类
做一个logitic分类之鸢尾花数据集的分类 Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例.数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都 ...
- 实验一 使用sklearn的决策树实现iris鸢尾花数据集的分类
使用sklearn的决策树实现iris鸢尾花数据集的分类 要求: 建立分类模型,至少包含4个剪枝参数:max_depth.min_samples_leaf .min_samples_split.max ...
随机推荐
- Lucene 04 - 学习使用Lucene的Field(字段)
目录 1 Field的特性 2 常用的Field类型 3 常用的Field种类使用 3.1 准备环境 3.2 需求分析 3.3 修改代码 3.4 重新建立索引 1 Field的特性 Document( ...
- 自定义微信小程序导航(兼容各种手机)
详细代码请见github,请点击地址,其中有原生小程序的实现,也有wepy版本的实现 了解小程序默认导航 如上图所示,微信导航分为两部分,第一个部分为statusBarHeight,刘海屏手机(iPh ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- leetcode — word-search
import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * Source : https://o ...
- Java开发知识之XML文档使用,解析
目录 XML文件详解 一丶XML简介 1.文档结构 2.XML中的元素(Element)或者叫做标签(Tab).属性 文本内容. 节点(Node) 3.XML语法规则 二丶XML文档解析 三丶使用XP ...
- Jenkins结合.net平台综合之完整示例项目
前面每一个部分我们都是介绍的单个功能,这里介绍一个完整项目,本文中所用到的命令都放在了github示例代码仓库中 https://github.com/mrtylerzhou/netdevops 命令 ...
- BlockingQueue 阻塞队列实现异步事件
转载请注明出处:https://www.cnblogs.com/wenjunwei/p/10411444.html 前言 本文通过一个简单的例子,来展现如何使用阻塞队列(BlockingQueue)来 ...
- [SRM603] WinterAndSnowmen
Description Sol 设 \(A=\text{XOR}(X)\),\(B=\text{XOR}(Y)\). 因为 \(A<B\),所以写下他们的二进制表示,一定是最高的几位先是相等,紧 ...
- 【前端】js中数组对象根据内容查找符合的第一个对象
今天在写一个混合开发版的app,其中一个功能是扫描快递单号,客户要求不能扫描重复的快递单号!所有就验证查出. 首先实现思路就是: 1.定义一个全局数组变量:var nubList = []; 2.进入 ...
- 17、字符串转换整数 (atoi)
17.字符串转换整数 (atoi) 请你来实现一个 atoi 函数,使其能将字符串转换成整数. 首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止. 当我们寻找到的第一个非 ...