机器学习入门-主成分分析(PCA)
主成分分析:
用途:降维中最常用的一种方法
目标:提取有用的信息(基于方差的大小)
存在的问题:降维后的数据将失去原本的数据意义
向量的内积:A*B = |A|*|B|*cos(a) 如果|B| = 1,那么A*B = |A| * cos(a) 即在B的方向上对A做投影

基变化: 如果向量为(3, 2)那么它可以有(1, 0)和(0, 1)一组基进行表示,这两个基是正交的

在基变化过程中,每一个基都是正交的即线性无关
数据与第一个基进行内积,形成一个新的分量,数据与第二个基做内积,形成第二个分量,由于基是正交的,而内积表示的是投影,因此这两个分量也是正交的
即 1/m ai.dot(bi) = 0。
方差:变量的方差越大,其分散程度也就越大,方差 (ai-ui).dot((ai-ui).T) ui表示的是样本的均值
协方差:两个向量的内积,协方差越小,表示两个向量越不相似cov(a, b) = 1/m*(a.dot(b.T))
引入协方差的目的:
如果单纯只看变化后的方差大小,那么求得的基可能都在方差最大的方向附件进行徘徊,因为我们为了使变换后的特征尽可能的表示原始信息,我们使得变化后的特征是正交的情况,即特征之间线性无关,协方差cov=0
结合上述的两个条件:第一:变换后的矩阵的方差最大1/m ai.dot(ai.T)
第二:变换后的矩阵的协方差等于0 1/m ai.dot(bi.T)
我们引入了协方差矩阵,协方差矩阵对角线是方差,非对角线上是协方差
公式: 1/m X.dot(X.T)
1/m * Y.dot(Y.T) = 1/m PX.dot((PX).T) = 1/m(P* X * X^T * P^T)
令上面的式子中的 X*X^T等于C,那么上面的式子就是 1/m * Y.dot(Y.T) = 1/m(P* C * P^T)
我们需要使得1/m * Y.dot(Y.T) 满足上述两个条件,即对C做一个对角化变化,使得变化后的矩阵对角线上的表示方差(从大到小排列), 非对角线上等于0

这个问题前人已经研究了很透,即上述变化的P就是C的特征向量,而C等于X*X^T
我们只需要求得X*X^T的特征向量即可
上述的过程的实现步骤:
1.对特征进行标准化
2.去均值
3.求协方差矩阵 X*X^T
4.协方差矩阵的特征向量
5.使用前几维的特征向量与特征进行内积,实现特征降维
代码:
第一步:导入数据, 进行列名赋值
第二步:提取特征和标签
第三步:对每一个特征进行物体类别画直方图,研究不同变量对特征分布的影响
第四步:对样本特征进行标准化操作
第五步:对样本去均值并构造协方差矩阵X.dot(X.T)
第六步:对构造好的协方差矩阵求特征值和特征向量
第七步:将求得的特征值和特征向量进行组合, 对组合的特征进行排序操作,将排序后的特征进行使用np.cumsum对特征值进行加和
第八步:使用条形图和步进图对特征值和加和后的特征进行作图操作
第九步:选取前两个特征向量与标准化后的特征进行内积操作,获得降维后的特征
第十步:对降维后的特征画出散点图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt # 第一步 数据读取
data = pd.read_csv('iris.data') data.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'classes'] # 第二步 提取特征
X = data[['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid']].values
y = data['classes'].values feature_names = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid']
label_names = data['classes'].unique() # 第三步 对每一个特征的样品类别做直方图
for feature in range(len(feature_names)):
plt.subplot(2, 2, feature+1)
for label in label_names:
plt.hist(X[y==label, feature], bins=10, alpha=0.5, label=label)
plt.legend(loc='best')
plt.show()
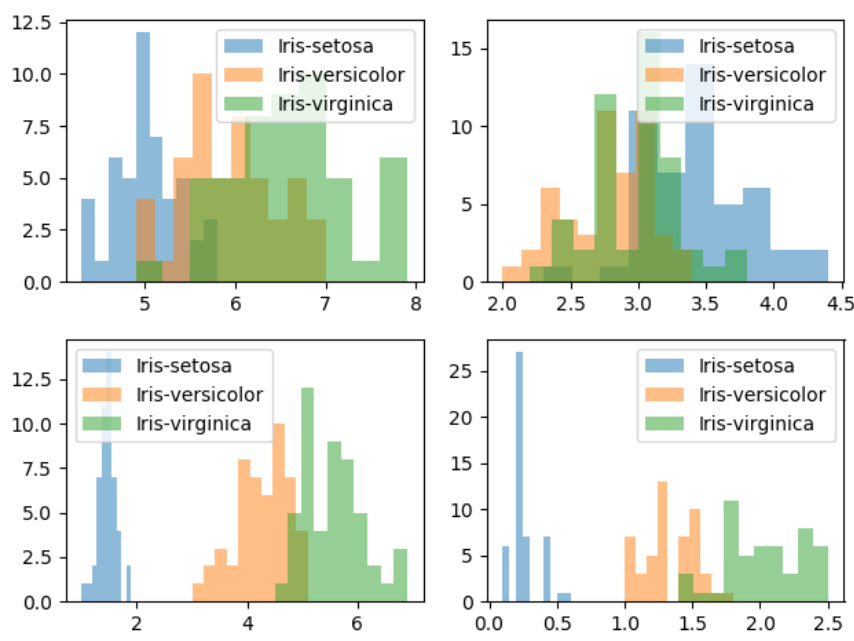
不同变量对类别分布的影响
# 第四步 对特征进行标准化操作
from sklearn.preprocessing import StandardScaler std_feature = StandardScaler().fit_transform(X) # 第五步 对特征去除均值, 并构造协方差矩阵, 也可以使用np.conv进行构造
mean_fea = std_feature.mean(axis=0)
cov_matrix = (std_feature - mean_fea).T.dot(std_feature-mean_fea) # 第六步 使用np.linalg.eig 求出协方差矩阵的特征值和特征向量 eig_val, eig_vector = np.linalg.eig(cov_matrix) # 第七步:我们将特征值和特征向量进行组合 eig_paries = [(eig_val[j], eig_vector[:, j]) for j in range(len(eig_val))] # 获得对组合的特征值进行排序,获得重要性的占比
sum_val = np.sum(eig_val)
feature_importance = [eig_v[0]/sum_val * 100 for eig_v in sorted(eig_paries, key=lambda x:x[0], reverse=True)]
print(feature_importance)
# 使用np.cumsum进行两两的前后加和
su_feature_importance = np.cumsum(feature_importance)
# 第八步:对特征重要性进行作图操作
figure = plt.figure(figsize=(8, 6))
plt.bar(range(4), feature_importance, align='center', label='identity explain variance', alpha=0.5)
# plt.step表示的是步进图, where表示的线条的表示方式
plt.step(range(4), su_feature_importance, where='mid', label='cumidentity explain variance')
plt.xlabel('PC component')
plt.ylabel('variance importance')
plt.show()
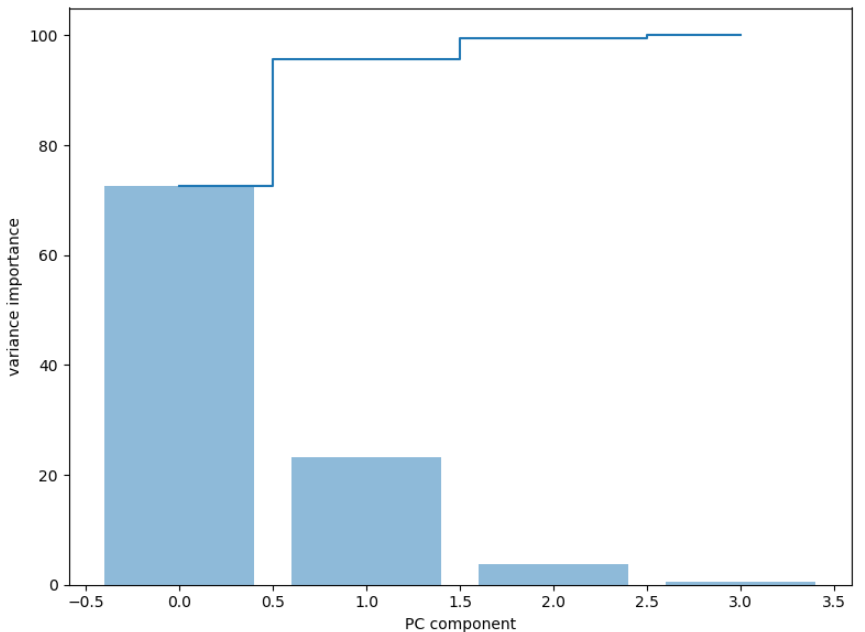
特征值重要比例图
# 第九步:使用前两个特征向量进行矩阵的变换 eig_vector_two = np.vstack([eig_paries[0][1], eig_paries[1][1]])
trans_std_X = std_feature.dot(eig_vector_two.T) # 第十步: 对变化后的数据进行画图操作 figure = plt.figure(figsize=(8, 6))
for label, c in zip(label_names, ['red', 'green', 'black']):
plt.scatter(std_feature[y==label][:, 0], std_feature[y==label][:, 1], c=c, label=label, alpha=0.6, s=20)
leg = plt.legend(loc='best')
leg.get_frame().set_alpha(0.6)
plt.xlabel(feature_names[0])
plt.ylabel(feature_names[1])
plt.show() figure = plt.figure(figsize=(8, 6))
for label, c in zip(label_names, ['red', 'green', 'black']):
plt.scatter(trans_std_X[y==label][:, 0], trans_std_X[y==label][:, 1], c=c, label=label, alpha=0.6, s=20)
leg = plt.legend(loc='best')
leg.get_frame().set_alpha(0.6)
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.show()


原始特征图 降维后的特征图
机器学习入门-主成分分析(PCA)的更多相关文章
- 机器学习之主成分分析PCA原理笔记
1. 相关背景 在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律.多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的 ...
- [机器学习笔记]主成分分析PCA简介及其python实现
主成分分析(principal component analysis)是一种常见的数据降维方法,其目的是在“信息”损失较小的前提下,将高维的数据转换到低维,从而减小计算量. PCA的本质就是找一些投影 ...
- 【机器学习】--主成分分析PCA降维从初识到应用
一.前述 主成分分析(Principal Component Analysis,PCA), 是一种统计方法.通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分. ...
- 【机器学习】主成分分析PCA(Principal components analysis)
1. 问题 真实的训练数据总是存在各种各样的问题: 1. 比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余. 2. 拿到 ...
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
- 机器学习降维方法概括, LASSO参数缩减、主成分分析PCA、小波分析、线性判别LDA、拉普拉斯映射、深度学习SparseAutoEncoder、矩阵奇异值分解SVD、LLE局部线性嵌入、Isomap等距映射
机器学习降维方法概括 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014772862/article/details/52335970 最近 ...
- 深度学习入门教程UFLDL学习实验笔记三:主成分分析PCA与白化whitening
主成分分析与白化是在做深度学习训练时最常见的两种预处理的方法,主成分分析是一种我们用的很多的降维的一种手段,通过PCA降维,我们能够有效的降低数据的维度,加快运算速度.而白化就是为了使得每个特征能有同 ...
- 机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩 第二种类型的 无监督学习问题,称为 降维.有几个不同的的原因使你可能想要做降维.一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快 ...
- 线性判别分析(LDA), 主成分分析(PCA)及其推导【转】
前言: 如果学习分类算法,最好从线性的入手,线性分类器最简单的就是LDA,它可以看做是简化版的SVM,如果想理解SVM这种分类器,那理解LDA就是很有必要的了. 谈到LDA,就不得不谈谈PCA,PCA ...
随机推荐
- smarty学习——高级知识
1.Objects 对象 smarty允许通过模板访问PHP对象.有两种方式来访问它们.一种是注册对象到模板,然后通过类似于用户自定义函数的形式来访问它. 另一种方法给模板分配对象,然后通过访问其它赋 ...
- centos7 lvs keepalived做DNS集群负载
2LVS + keepalived 5 bind dns源站 yum -y install ipvsadm keepalived lvs增加并发 echo "options ip_vs c ...
- jquery ajax 上传文件
html:<!-- /.tab-pane --> <div class="tab-pane" id="head_portrait"> & ...
- ncnn编译安装-20190415
ncnn编译安装 1.git clone https://github.com/Tencent/ncnn 2.按照wiki说明来编译,根据需要,选择不同的编译方式.在ncnn/CMakeLists.t ...
- DataSet和DataTable有用的方法
每一个DataSet都是一个或多个DataTable 对象的集合(DataTable相当于数据库中的表),这些对象由数据行(DataRow).数据列(DataColumn).字段名(Column Na ...
- JDBC进行简单的增删改查
一.准备工作(一):MySQL安装配置和基础学习 二.准备工作(二):下载数据库对应的jar包并导入 三.JDBC基本操作 (1)定义记录的类(可选) (2)连接的获取 (3)insert (4)up ...
- 如何制作Jar包并在android中调用jar包
android制作jar包: 新建android工程,然后右击,点击导出,选择导出类型为Java下的JAR file,在java file specification 中不要选择androidmani ...
- 【EasyUI学习-1】MyEclipse+easyui学习官方Demo
介绍 easyui的介绍,网上很多,这里就不进行介绍了. easyUI获取 官网: http://www.jeasyui.com/ 下载地址:http://www.jeasyui.com/downl ...
- bzoj 3768: spoj 4660 Binary palindrome二进制回文串
Description 给定k个长度不超过L的01串,求有多少长度为n的01串S满足: 1.该串是回文串 2.该串不存在两个不重叠的子串,在给定的k个串中. 即不存在a<=b<c<= ...
- 峰Spring4学习(3)注入参数的几种类型
People.java model类: package com.cy.entity; import java.util.ArrayList; import java.util.HashMap; im ...