异常检测(anomaly detection)
版权声明:本文为博主原创文章,转载或者引用请务必注明作者和出处,尊重原创,谢谢合作 https://blog.csdn.net/u012328159/article/details/51462942
异常检测(anomaly detection)
- 异常检测定义及应用领域
- 常见的异常检测算法
- 高斯分布(正态分布)
- 异常检测算法
- 评估异常检测算法
- 异常检测VS监督学习
- 如何设计选择features
- 多元高斯分布
- 多元高斯分布在异常检测上的应用
- 欺诈检测:主要通过检测异常行为来检测是否为盗刷他人信用卡。
- 入侵检测:检测入侵计算机系统的行为
- 医疗领域:检测人的健康是否异常
- 基于模型的技术:许多异常检测技术首先建立一个数据模型,异常是那些同模型不能完美拟合的对象。例如,数据分布的模型可以通过估计概率分布的参数来创建。如果一个对象不服从该分布,则认为他是一个异常。
- 基于邻近度的技术:通常可以在对象之间定义邻近性度量,异常对象是那些远离大部分其他对象的对象。当数据能够以二维或者三维散布图呈现时,可以从视觉上检测出基于距离的离群点。
- 基于密度的技术:对象的密度估计可以相对直接计算,特别是当对象之间存在邻近性度量。低密度区域中的对象相对远离近邻,可能被看做为异常。
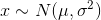 。其中
。其中 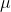 为数学期望,
为数学期望,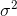 为方差,其概率密度函数为:
为方差,其概率密度函数为: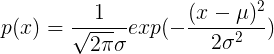
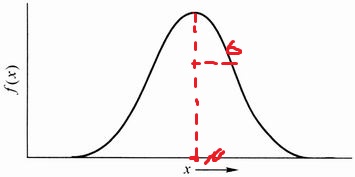 决定了其中心位置,标准差 决定了其宽度。如果
决定了其中心位置,标准差 决定了其宽度。如果 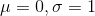 ,则称为标准正态分布,其图像如下图所示:
,则称为标准正态分布,其图像如下图所示: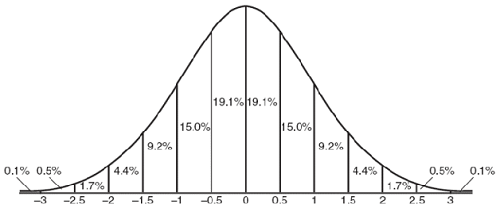 , 对图像的影响:
, 对图像的影响: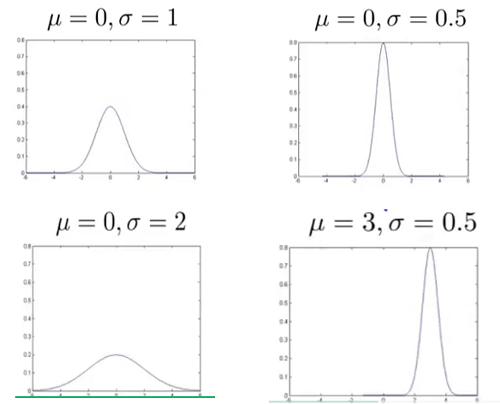
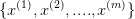 ,已知数据集中样本服从正态分布,即
,已知数据集中样本服从正态分布,即 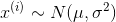 ,那么该如何求出参数 和
,那么该如何求出参数 和 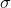 呢?这便是参数估计。我们有如下公式来估计 ,:
呢?这便是参数估计。我们有如下公式来估计 ,: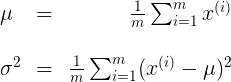
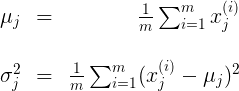 ,对于每一个样本x都有
,对于每一个样本x都有 ,即每个样本都是一个n维向量,那么可以建立一个概率模型来估计每个样本的概率密度:
,即每个样本都是一个n维向量,那么可以建立一个概率模型来估计每个样本的概率密度: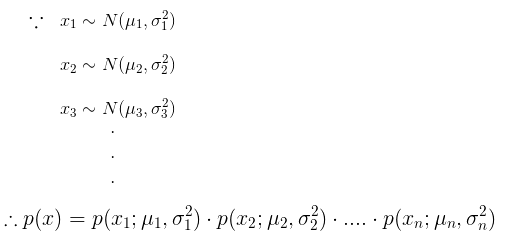

 值是怎么确定的?其实这个 是个经验值,NG给出的方法是选择在验证集上使评估指标(如F-measure)值最大的那个 。
值是怎么确定的?其实这个 是个经验值,NG给出的方法是选择在验证集上使评估指标(如F-measure)值最大的那个 。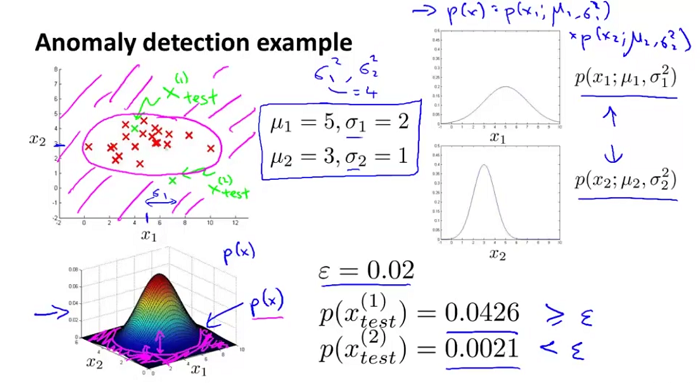
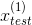 、
、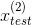 ,可以分别计算出它们的概率密度,分别为0.0426,0.0021,然后分别和给定的 值比较,能够得出为离群点。
,可以分别计算出它们的概率密度,分别为0.0426,0.0021,然后分别和给定的 值比较,能够得出为离群点。


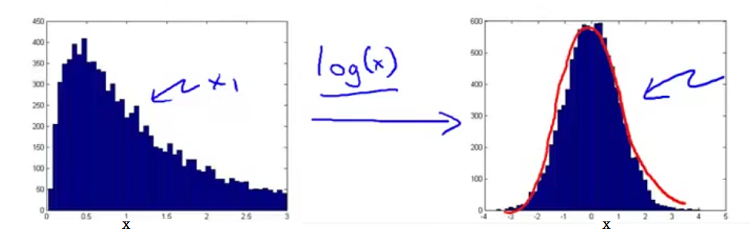

 能够更好的反应出网络的异常情况。
能够更好的反应出网络的异常情况。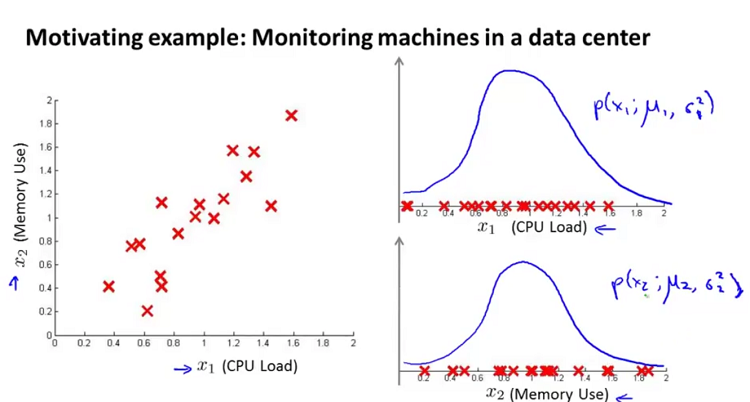
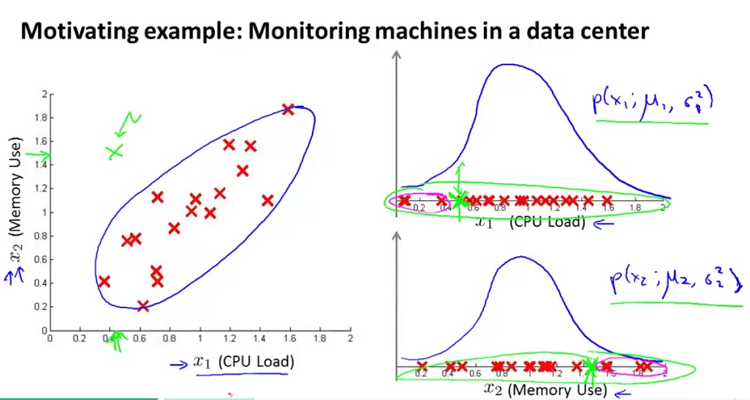
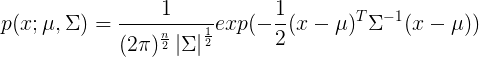
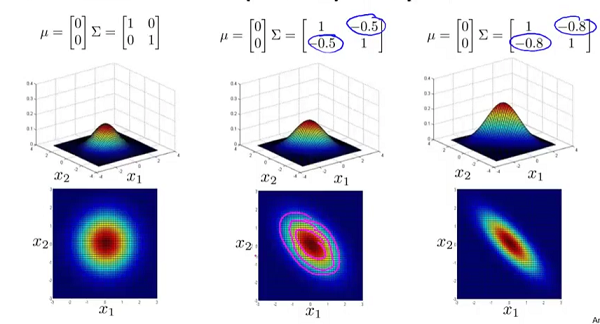
 为n*n维协方差矩阵,
为n*n维协方差矩阵, 为矩阵 的行列式。 和矩阵 对概率密度函数的影响。 的影响:
为矩阵 的行列式。 和矩阵 对概率密度函数的影响。 的影响: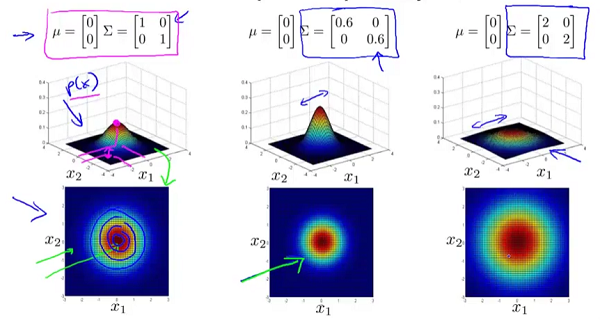
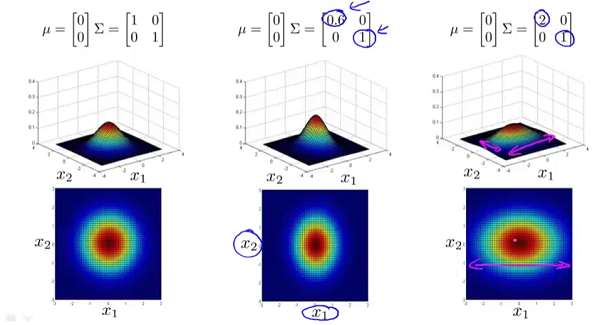
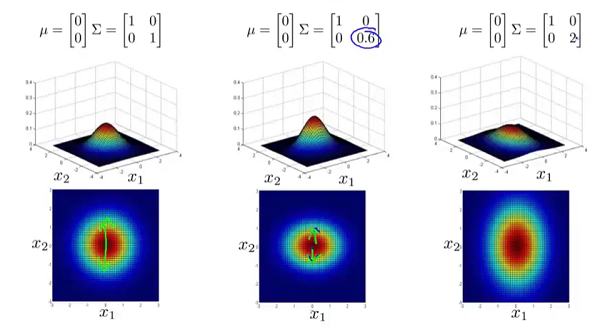 的副对角线都为0时,主对角线上的元素大小控制着概率密度函数俯瞰图的形状大小,至于具体到数字大小对应的形状,大家自己观察便知。
的副对角线都为0时,主对角线上的元素大小控制着概率密度函数俯瞰图的形状大小,至于具体到数字大小对应的形状,大家自己观察便知。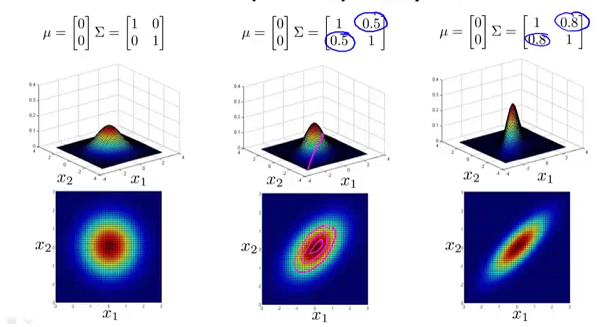
 对概率密度函数的影响:
对概率密度函数的影响: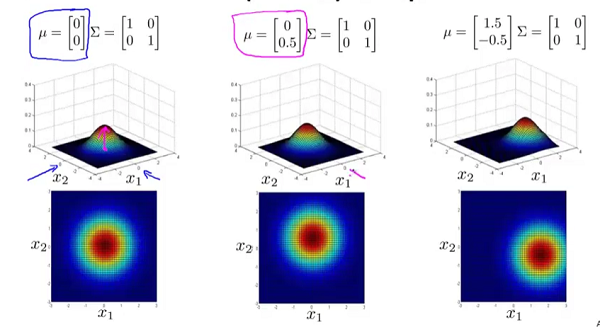 控制着图形的位置变化。
控制着图形的位置变化。
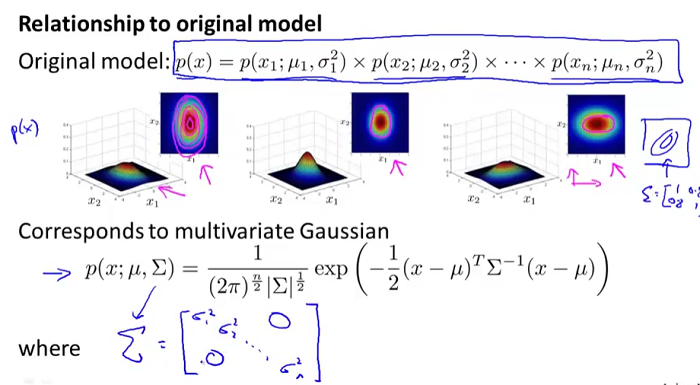 为对角矩阵,且对角线上的元素为各自一元高斯分布模型的方差时,二者是等价的。
为对角矩阵,且对角线上的元素为各自一元高斯分布模型的方差时,二者是等价的。
异常检测(anomaly detection)的更多相关文章
- 异常检测(Anomaly Detection)
十五.异常检测(Anomaly Detection) 15.1 问题的动机 参考文档: 15 - 1 - Problem Motivation (8 min).mkv 在接下来的一系列视频中,我将向大 ...
- [C10] 异常检测(Anomaly Detection)
异常检测(Anomaly Detection) 问题的动机 (Problem Motivation) 异常检测(Anomaly detection)问题是机器学习算法中的一个常见应用.这种算法的有趣之 ...
- 机器学习(十一)-------- 异常检测(Anomaly Detection)
异常检测(Anomaly Detection) 给定数据集
- 吴恩达机器学习笔记(九) —— 异常检测(Anomaly detection)
主要内容: 一.模型介绍 二.算法过程 三.算法性能评估及ε(threshold)的选择 四.Anomaly detection vs Supervised learning 五.Multivaria ...
- 基于高斯分布的异常检测(Anomaly Detection)算法
记得在做电商运营初期,每每为我们频道的促销活动锁取得的“超高”销售额感动,但后来随着工作的深入,我越来越觉得这里面水很深.商家运营.品类运营不断的通过刷单来获取其所需,或是商品搜索排名,或是某种kpi ...
- 异常检测(Anomaly detection): 什么是异常检测及其一些应用
异常检测的例子: 如飞机引擎的两个特征:产生热量与振动频率,我们有m个样本画在图中如上图的叉叉所示,这时来了一个新的样本(xtest),如果它落在上面,则表示它没有问题,如果它落在下面(如上图所示), ...
- Ng第十五课:异常检测(Anomaly Detection)
15.1 问题的动机 15.2 高斯分布 15.3 算法 15.4 开发和评价一个异常检测系统 15.5 异常检测与监督学习对比 15.6 选择特征 15.7 多元高斯分布(可选) 15 ...
- 异常检测(Anomaly detection): 异常检测算法(应用高斯分布)
估计P(x)的分布--密度估计 我们有m个样本,每个样本有n个特征值,每个特征都分别服从不同的高斯分布,上图中的公式是在假设每个特征都独立的情况下,实际无论每个特征是否独立,这个公式的效果都不错.连乘 ...
- 异常检测(Anomaly detection): 高斯分布(正态分布)
高斯分布 高斯分布也称为正态分布,μ为平均值,它描述了正态分布概率曲线的中心点.σ为标准差,σ2为方差,σ描述了曲线的宽度.在中心点附近概率密度大,远离中心点概率密度小. 高斯分布图 概率曲线下方的面 ...
- Coursera在线学习---第九节(1).异常数据检测(Anomaly Detection)
一.如何构建Anomaly Detection模型? 二.如何评估Anomaly Detection系统? 1)将样本分为6:2:2比例 2)利用交叉验证集计算出F1值,可以用F1值选取概率阈值ξ,选 ...
随机推荐
- hashCode()方法和equal()方法的区别
本文参考地址:http://www.cnblogs.com/zgq0/p/9000801.html hashCode()方法和equal()方法的作用其实一样,在Java里都是用来对比两个对象是否相等 ...
- 看懂「www.google.com」背后的逻辑
在前两篇文章中,我们完整的描述了计算机网络 OSI 五层模型的相关内容.那么,本篇将会从一个实践案例开始,带你从整体上重新认识我们的计算机网络. 我们以访问 Google 为例,当我们在浏览器地址栏中 ...
- WebApi开启CORS支持跨域POST
概念:CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing).它允许浏览器向跨源服务器,发出XMLHttpRequest请求 ...
- Filebeat+Kafka+Logstash+ElasticSearch+Kibana 日志采集方案
前言 Elastic Stack 提供 Beats 和 Logstash 套件来采集任何来源.任何格式的数据.其实Beats 和 Logstash的功能差不多,都能够与 Elasticsearch 产 ...
- Java语法之反射
一.反射机制 在前面Java语法之注解自定义注解时我们也有提到反射,要获取类方法和字段的注解信息,必须通过Java的反射技术来获取 Annotation对象.那什么是反射呢?JAVA反射机制是在运行状 ...
- [转]简单的动态修改RDLC报表页边距和列宽的方法
本文转自:http://star704983.blog.163.com/blog/static/136661264201161604413204/ 1.修改页边距 XmlDocument XMLDoc ...
- ASP.NET Web API 启用跨域访问
自定义特性 要在WebApi中实现JSONP,一种方式是实现自定义特性 http://stackoverflow.com/questions/9421312/jsonp-with-asp-net-w ...
- 【Java并发编程】14、Thread,线程说明
线程的状态:New.Runnable.Blocked.Waiting.Timed waiting.Terminated 1. RUNNABLE,对应"就绪"和"运行&qu ...
- SpringBoot注解验证参数
SpringBoot注解验证参数 废话不多说,直接上表格说明: 注解 作用类型 解释 @NotNull 任何类型 属性不能为null @NotEmpty 集合 集合不能为null,且size大于0 @ ...
- linux shell脚本之-变量极速入门与进阶(2)
1,$$:显示当前的进程id号 ghostwu@dev:~/linux/shell/how_to_use_var$ cat show_pid.sh #!/bin/bash echo $$ ghostw ...