关于subGradent descent和Proximal gradient descent的迭代速度
clc;clear;
D=1000;N=10000;thre=10e-8;zeroRatio=0.6;
X = randn(N,D);
r=rand(1,D);
r=sign(1-2*r).*(2+2*r);
perm=randperm(D);r(perm(1:floor(D*zeroRatio)))=0;
Y = X*r' + randn(N,1)*.1; % small added noise
lamda=1;stepsize=10e-5;
%%% y=x*beta'
%%% Loss=0.5*(y-x*beta')_2++lamda|beta| %%%% GD
%%% al_y/al_beta=sigma(x_i*(x_i*beta'-y_i)+fabs(lamda))
beta=zeros(size(r)); pre_error=inf;new_error=0;
count=1;tic;
while abs(pre_error-new_error)>thre
pre_error=new_error;
tmp=0;
for j=1:length(Y)
tmp=tmp+X(j,:)*(X(j,:)*beta'-Y(j,:));
end
beta=beta-stepsize*(tmp+lamda);
new_error=lamda*norm(beta,1);
for j=1:length(Y)
new_error=new_error+(Y(j,:)-X(j,:)*beta')*(Y(j,:)-X(j,:)*beta');
end
fprintf('%d..%f\n',count,new_error);
count=count+1;
end
toc; % %%%% Proximal GD
% Loss=0.5*(y-x*beta')_2++lamda|beta|=g(x)+h(x)
% 左边可导 x_{t+1}=x_{t}-stepsize*sigma(x_i*(x_i*beta'-y_i)
% X_{t+1}=prox_{l1-norm ball}(x_{t+1})= disp('pgd')
beta_pgd=zeros(size(r));
pre_error=inf;new_error=0;count=1;tic;
while abs(pre_error-new_error)>thre
pre_error=new_error;
tmp=0;
for j=1:length(Y)
tmp=tmp+X(j,:)*(X(j,:)*beta_pgd'-Y(j,:));
end
newbeta=beta_pgd-stepsize*(tmp+lamda); add=stepsize*lamda;
pidx=newbeta>add;beta_pgd(pidx)=newbeta(pidx)-add;
zeroidx=newbeta<abs(add);beta_pgd(zeroidx)=0;
nidx=newbeta+add<0;beta_pgd(nidx)=newbeta(nidx)+add; new_error=lamda*norm(beta_pgd,1);
for j=1:length(Y)
new_error=new_error+(Y(j,:)-X(j,:)*beta_pgd')*(Y(j,:)-X(j,:)*beta_pgd');
end
fprintf('%d..%f\n',count,new_error);
count=count+1;
end
toc;
PGD的代码说明见下图
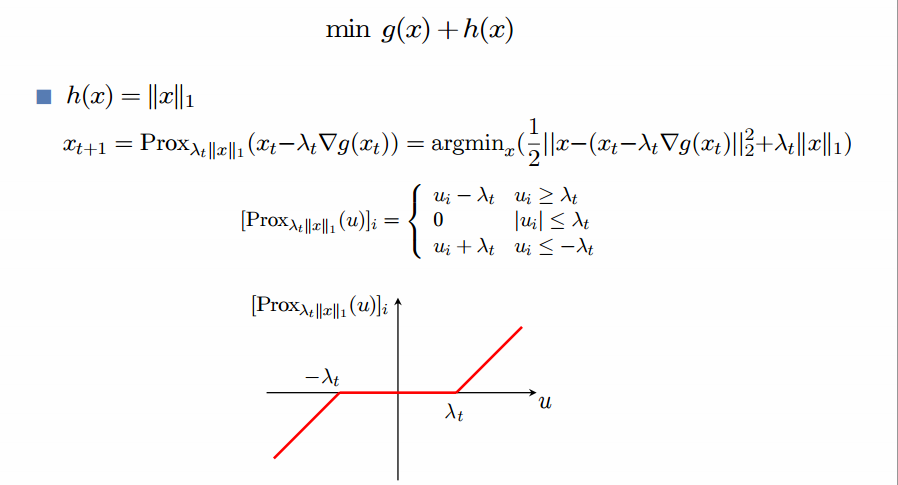
PGD主要是projection那一步有解析解,速度快
subGradent收敛速度O(1/sqrt(T))
速度提升不明显可能是因为步长的原因。。。
关于subGradent descent和Proximal gradient descent的迭代速度的更多相关文章
- Proximal Gradient Descent for L1 Regularization
[本文链接:http://www.cnblogs.com/breezedeus/p/3426757.html,转载请注明出处] 假设我们要求解以下的最小化问题: ...
- Proximal Gradient Descent for L1 Regularization(近端梯度下降求解L1正则化问题)
假设我们要求解以下的最小化问题: $min_xf(x)$ 如果$f(x)$可导,那么一个简单的方法是使用Gradient Descent (GD)方法,也即使用以下的式子进行迭代求解: $x_{k+1 ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- Gradient Descent 和 Stochastic Gradient Descent(随机梯度下降法)
Gradient Descent(Batch Gradient)也就是梯度下降法是一种常用的的寻找局域最小值的方法.其主要思想就是计算当前位置的梯度,取梯度反方向并结合合适步长使其向最小值移动.通过柯 ...
- Batch Gradient Descent vs. Stochastic Gradient Descent
梯度下降法(Gradient Descent)是用于最小化代价函数的方法. When $a \ne 0$, there are two solutions to \(ax^2 + bx + c = 0 ...
- 近端梯度算法(Proximal Gradient Descent)
L1正则化是一种常用的获取稀疏解的手段,同时L1范数也是L0范数的松弛范数.求解L1正则化问题最常用的手段就是通过加速近端梯度算法来实现的. 考虑一个这样的问题: minx f(x)+λg(x) x ...
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
随机推荐
- php lock_sh共享锁 与 lock_ex排他锁
参考网站:http://hi.baidu.com/honly1215/item/8d27a66d11689c3aac3e83fe 文件锁有两种:共享锁和排他锁,也就是读锁(LOCK_SH)和写锁(LO ...
- fastdfs-nginx扩展模块源码分析
FastDFS-Nginx扩展模块源码分析 1. 背景 在大多数业务场景中,往往需要为FastDFS存储的文件提供http下载服务,而尽管FastDFS在其storage及tracker都内置了htt ...
- Selenium2入门(二)WebDriver
前文Selenium2入门(一)说到Selenium是Web 应用程序测试框架,那么如果对一个简单的web应用需求:打开浏览器,登录百度首页,输入“欧洲杯”关键词,点击搜索按钮 这一系列操作,能否用S ...
- KMPlayer 捆绑商业软件问题以及解决办法
Kmplayer 本来是很好的播放软件,支持的格式很多,特别我要在本地播放flash swf 就用它.昨天下载安装了他们推荐已久的更新之后,莫名帮我安装了几个软件,都是我不能选择的,例如Winzip. ...
- mvc中Url.RouteUrl或者Html.RouteLink实现灵活超链接,使href的值随路由名称或配置的改变而改变[bubuko.com]
mvc,超链接除了直接写在a标签的href内还可以使用路由规则来生成,这样在改变了路由规则或者路由名称时不用再去代码中更改href的值,而且还容易遗漏.借助Url.RouteUrl或者Html.Rou ...
- Join two DataTables in C#
var query = (from x in a.AsEnumerable() join y in b.AsEnumerable() on x.Field<int>("col1& ...
- xml保存基本信息
public static string getXML(string nodeName) { string strReturn = ""; try { string fileNam ...
- NLP情感分析监督学习样本打标
1). 情感打标 a). 全句 单句 标签 好吃是好吃 pos 真材实料 pos 不过感觉一人份的量就有点小贵 neg 点的是肥牛米线 neu b). 全文本 文本 标签 分量足,味道不错,味道也不错 ...
- delphi 一个线程和主界面的交互的演示代码
求一个线程和主界面的交互的演示代码求一个线程和主界面的交互的演示代码.线程和主界面处于两个Unit.线程中的user中不能引用主窗口.我只是想学习一下,线程和主界面交互的方法.去网上查了好几天资料,能 ...
- Entity Framework 学习笔记
1.自定义数据库链接字符串上下文 public class PetDbContext : DbContext { public PetDbContext() : base("name=Dem ...