关于subGradent descent和Proximal gradient descent的迭代速度
clc;clear;
D=1000;N=10000;thre=10e-8;zeroRatio=0.6;
X = randn(N,D);
r=rand(1,D);
r=sign(1-2*r).*(2+2*r);
perm=randperm(D);r(perm(1:floor(D*zeroRatio)))=0;
Y = X*r' + randn(N,1)*.1; % small added noise
lamda=1;stepsize=10e-5;
%%% y=x*beta'
%%% Loss=0.5*(y-x*beta')_2++lamda|beta| %%%% GD
%%% al_y/al_beta=sigma(x_i*(x_i*beta'-y_i)+fabs(lamda))
beta=zeros(size(r)); pre_error=inf;new_error=0;
count=1;tic;
while abs(pre_error-new_error)>thre
pre_error=new_error;
tmp=0;
for j=1:length(Y)
tmp=tmp+X(j,:)*(X(j,:)*beta'-Y(j,:));
end
beta=beta-stepsize*(tmp+lamda);
new_error=lamda*norm(beta,1);
for j=1:length(Y)
new_error=new_error+(Y(j,:)-X(j,:)*beta')*(Y(j,:)-X(j,:)*beta');
end
fprintf('%d..%f\n',count,new_error);
count=count+1;
end
toc; % %%%% Proximal GD
% Loss=0.5*(y-x*beta')_2++lamda|beta|=g(x)+h(x)
% 左边可导 x_{t+1}=x_{t}-stepsize*sigma(x_i*(x_i*beta'-y_i)
% X_{t+1}=prox_{l1-norm ball}(x_{t+1})= disp('pgd')
beta_pgd=zeros(size(r));
pre_error=inf;new_error=0;count=1;tic;
while abs(pre_error-new_error)>thre
pre_error=new_error;
tmp=0;
for j=1:length(Y)
tmp=tmp+X(j,:)*(X(j,:)*beta_pgd'-Y(j,:));
end
newbeta=beta_pgd-stepsize*(tmp+lamda); add=stepsize*lamda;
pidx=newbeta>add;beta_pgd(pidx)=newbeta(pidx)-add;
zeroidx=newbeta<abs(add);beta_pgd(zeroidx)=0;
nidx=newbeta+add<0;beta_pgd(nidx)=newbeta(nidx)+add; new_error=lamda*norm(beta_pgd,1);
for j=1:length(Y)
new_error=new_error+(Y(j,:)-X(j,:)*beta_pgd')*(Y(j,:)-X(j,:)*beta_pgd');
end
fprintf('%d..%f\n',count,new_error);
count=count+1;
end
toc;
PGD的代码说明见下图
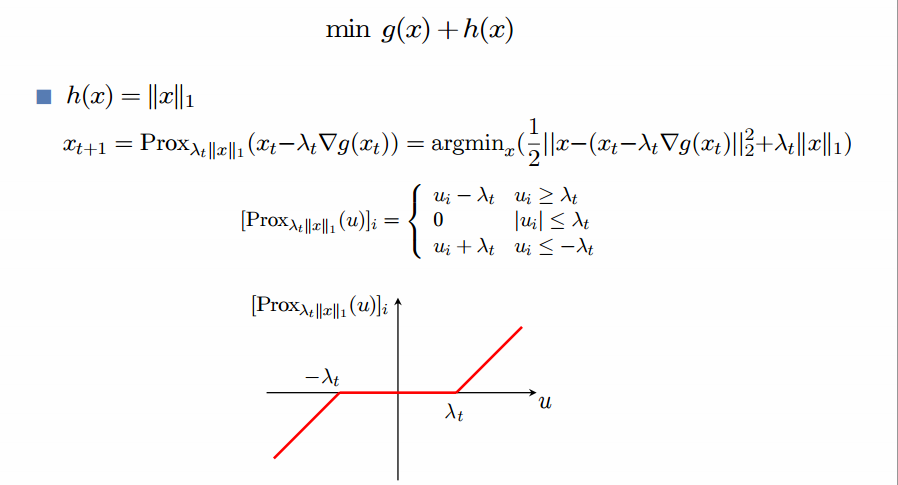
PGD主要是projection那一步有解析解,速度快
subGradent收敛速度O(1/sqrt(T))
速度提升不明显可能是因为步长的原因。。。
关于subGradent descent和Proximal gradient descent的迭代速度的更多相关文章
- Proximal Gradient Descent for L1 Regularization
[本文链接:http://www.cnblogs.com/breezedeus/p/3426757.html,转载请注明出处] 假设我们要求解以下的最小化问题: ...
- Proximal Gradient Descent for L1 Regularization(近端梯度下降求解L1正则化问题)
假设我们要求解以下的最小化问题: $min_xf(x)$ 如果$f(x)$可导,那么一个简单的方法是使用Gradient Descent (GD)方法,也即使用以下的式子进行迭代求解: $x_{k+1 ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- Gradient Descent 和 Stochastic Gradient Descent(随机梯度下降法)
Gradient Descent(Batch Gradient)也就是梯度下降法是一种常用的的寻找局域最小值的方法.其主要思想就是计算当前位置的梯度,取梯度反方向并结合合适步长使其向最小值移动.通过柯 ...
- Batch Gradient Descent vs. Stochastic Gradient Descent
梯度下降法(Gradient Descent)是用于最小化代价函数的方法. When $a \ne 0$, there are two solutions to \(ax^2 + bx + c = 0 ...
- 近端梯度算法(Proximal Gradient Descent)
L1正则化是一种常用的获取稀疏解的手段,同时L1范数也是L0范数的松弛范数.求解L1正则化问题最常用的手段就是通过加速近端梯度算法来实现的. 考虑一个这样的问题: minx f(x)+λg(x) x ...
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
随机推荐
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- javascript 利用匿名函数对象给你异步回调方法传参数
先来创建一个匿名函数对象: /*** * 匿名函数 */ var callChangeBtn=new function(bugBtn){ this.chage=function(json){ bugB ...
- ubuntu中常用软件的安装
1.有道词典 1.百度有道词典,进入有道首页,点"下载词典客户端",下载对应版本. 2.打开终端,进入下载目录,输入sudo dpkg -i youdao-dict_1.0.2~u ...
- iPad开发
获得view: self.categoryItem.customView 设置控制起 : 在POP ver中的尺寸 self.preferredContentSize = 坚挺三部曲 1. 通过设置 ...
- centos7 firewall 防火墙
在部署dubbo-monitor 和dubbo-admin zookeeper时候,外部访问不了部署好的服务,因为端口问题 ,现在把端口操作总结一下 参考: http://www.cnblogs.co ...
- C#封装好的Win32API
Kernel.cs using System; using System.Runtime.InteropServices; using System.Text; using HANDLE = Syst ...
- 百度地图API功能集锦
1.点个数太多导致加载缓慢的解决. 2.可视化区域内加载的解决. 3.自定义信息窗口解决. 4.区域/板块/商圈等的绘制功能解决. 基本包含了用到百度地图API会使用到的大部分常规性场景.(聚合点功能 ...
- Java三大主流框架概述
Struts.Hibernate和Spring是我们Java开发中的常用关键,他们分别针对不同的应用场景给出最合适的解决方案.但你是否知道,这些知名框架最初是怎样产生的? 我们知道,传统的Java W ...
- <工作一周的心情总结>
到公司一个星期有余,明天就要周六了,蛮开心的,兴奋的今天下午没看一点代码,哈哈~ 我做的算是代码界里最简单,最好玩,最有成就感的html,web网页的编程. 截止到目前,除了看不懂的JavaScrip ...
- http://blog.csdn.net/krislight/article/details/9391455
http://blog.csdn.net/krislight/article/details/9391455