Python爬虫学习笔记之模拟登陆并爬去GitHub
(1)环境准备:
请确保已经安装了requests和lxml库
(2)分析登陆过程:
首先要分析登陆的过程,需要探究后台的登陆请求是怎样发送的,登陆之后又有怎样的处理过程。
如果已经登陆GitHub,则需要先退出登陆,同时清除Cookies
打开GitHub的登陆页面,链接为https://github.com/login,输入GitHub的用户名和密码,打开开发者工具
,将Preserver Log选项勾选上,这表示持续日志,如下图所示
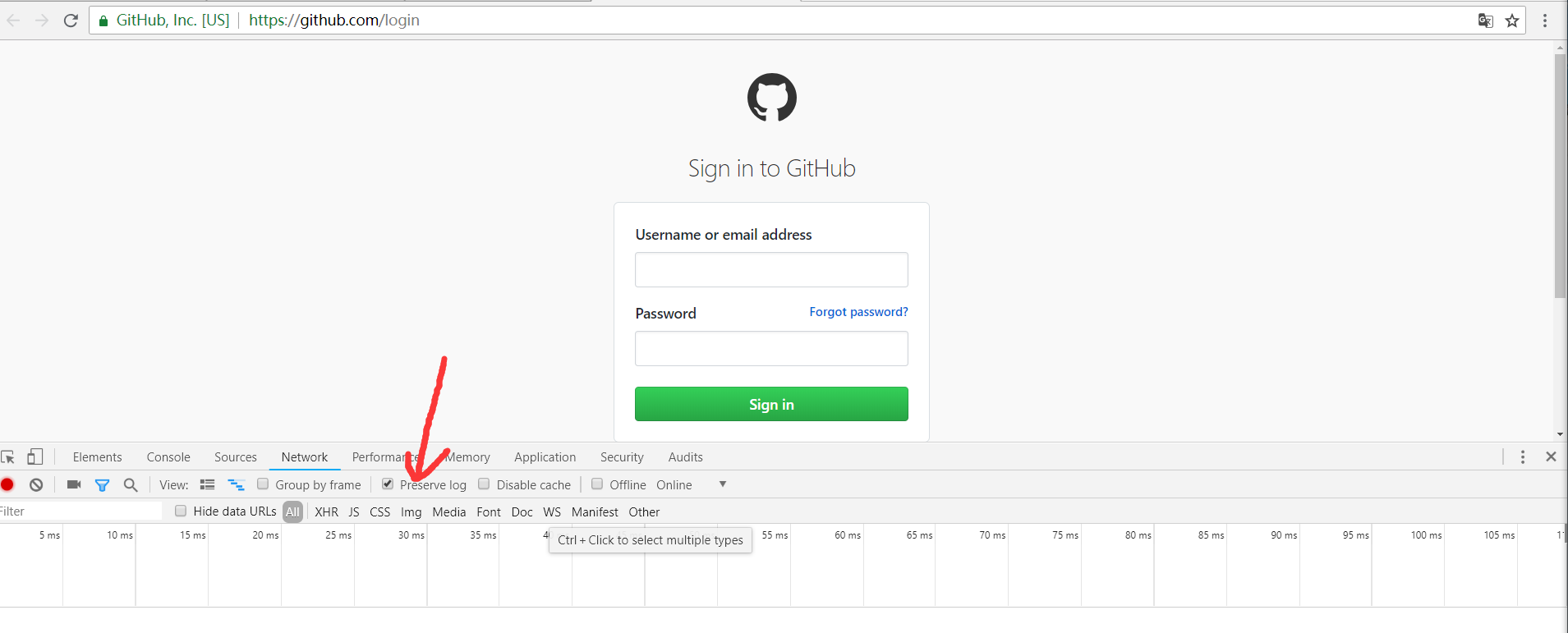
点击登录按钮,这时便会看到开发者工具下方显示了各个请求过程,如下图所示:
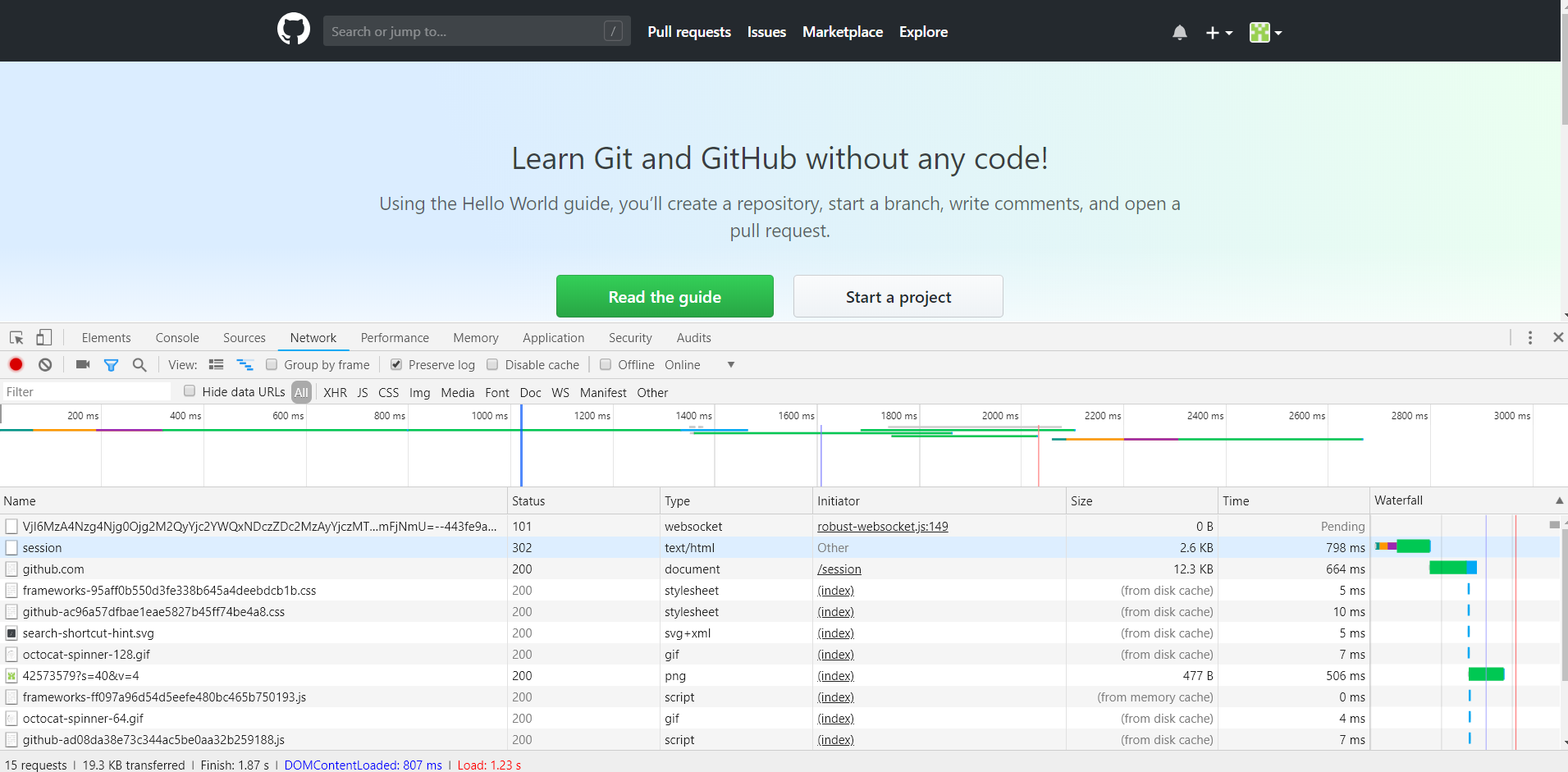
点击session请求,进入其详情,如下图所示:
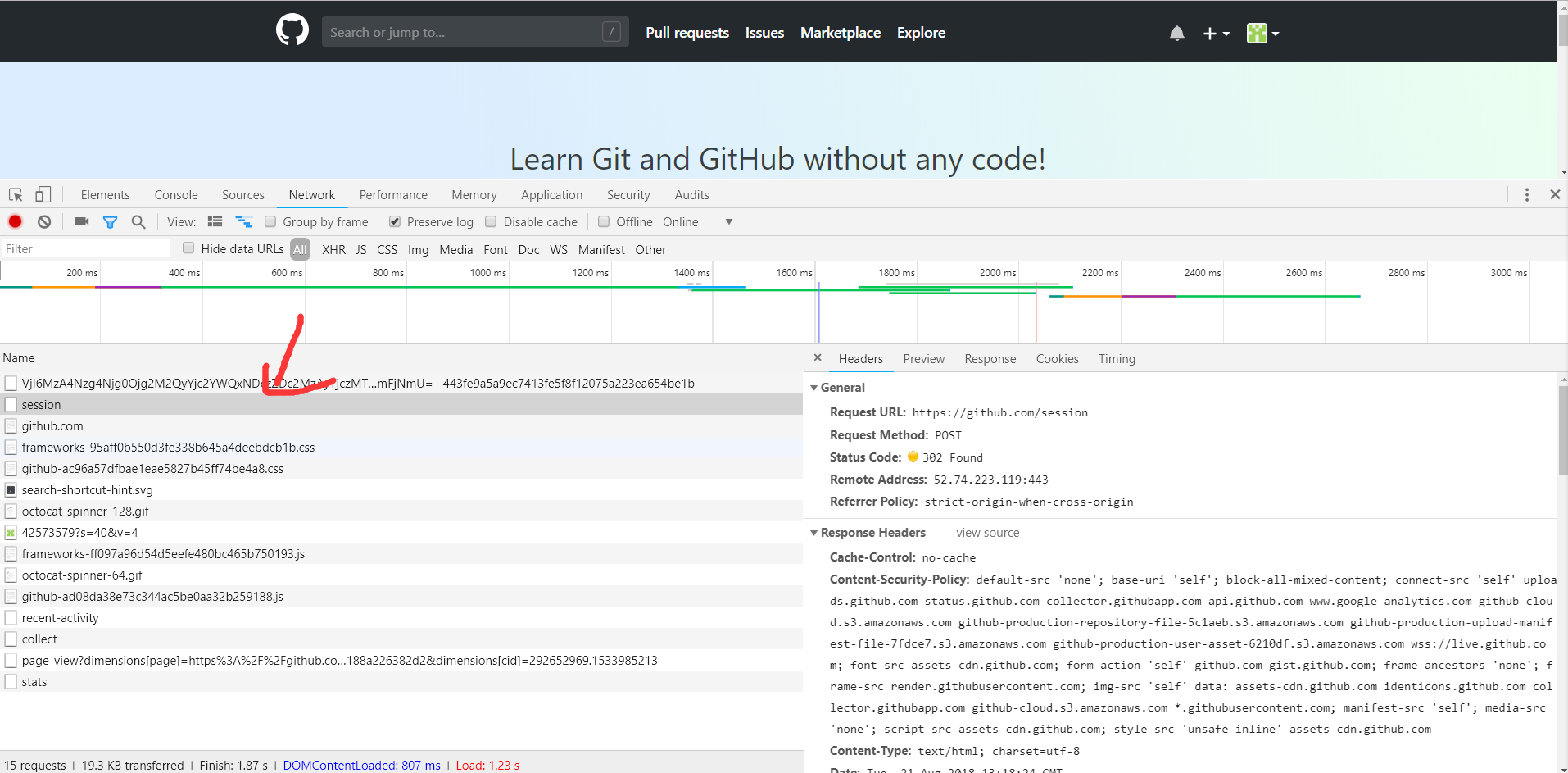
可以看到请求的URL为https://www.github.com/session,请求方式为POST。再往下看,我们观察到他的Form Data和Headers这两部分内容,
如下图所示:
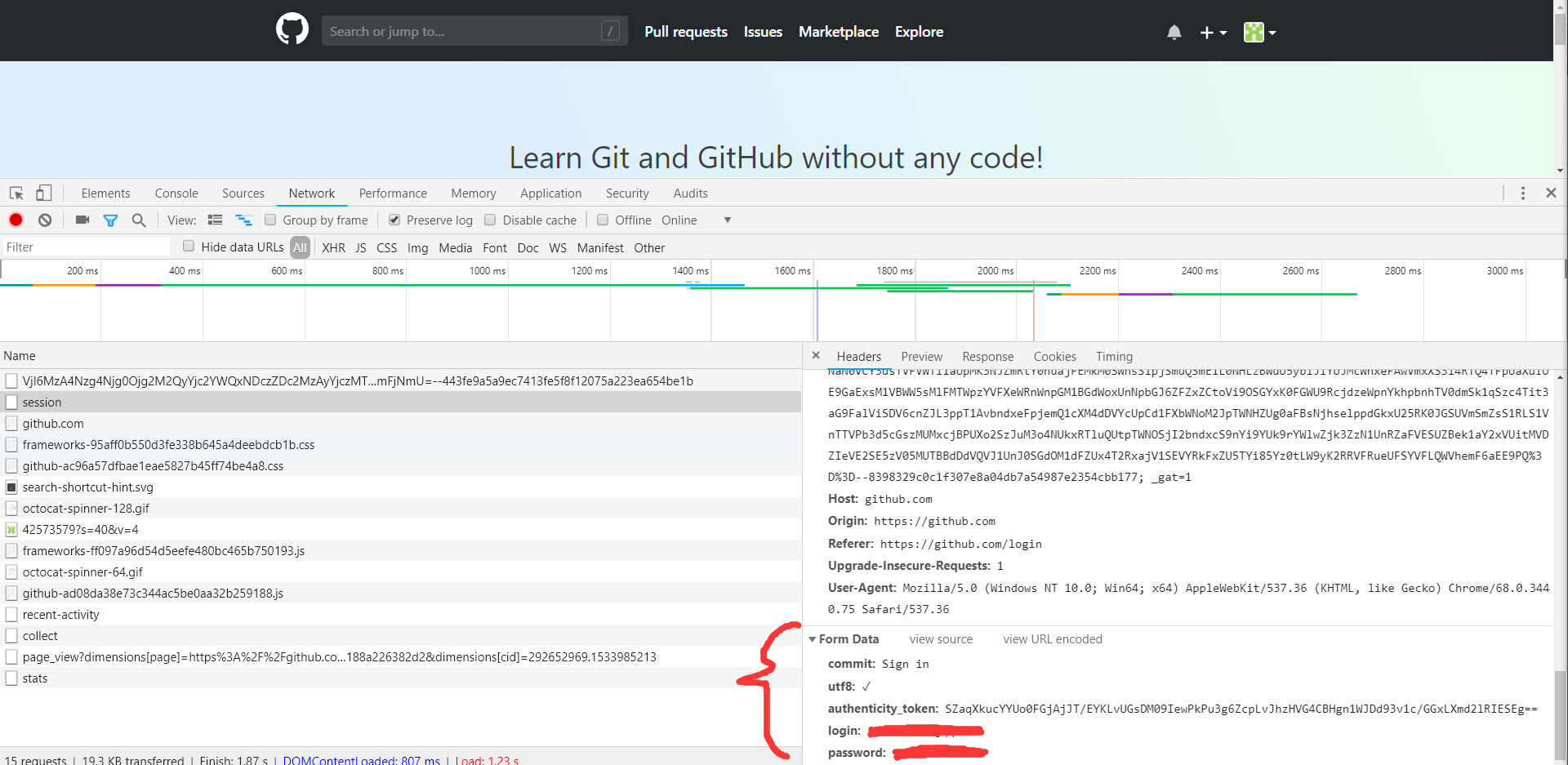
Headers里面包含了Cookies,Host,Origin,Refer,User-Agent等信息。Form Data包含了5个字段,commit是固定的字符串Sign in,utf8
是一个勾选字符,authenticity_token较长,其初步判断是一个Base64加密的字符串,login是登陆的用户名,password是登陆的密码。
综上所述,我们现在无法直接构造的内容有Cookies和authenticity_token。下面我们再来探寻一下这部分内容如何获取。
在登陆之前我们会访问到一个登陆页面,此页面是通过GET形式访问的。输入用户名和密码,点击登录按钮,浏览器发送这两部分信息,也就是
说Cookies和authenticity_token一定在访问扥估页面时候设置的。
这时在退出登陆,回到登录页,同时清除Cookies,重新访问登录页,截获发生的请求,如下图所示:
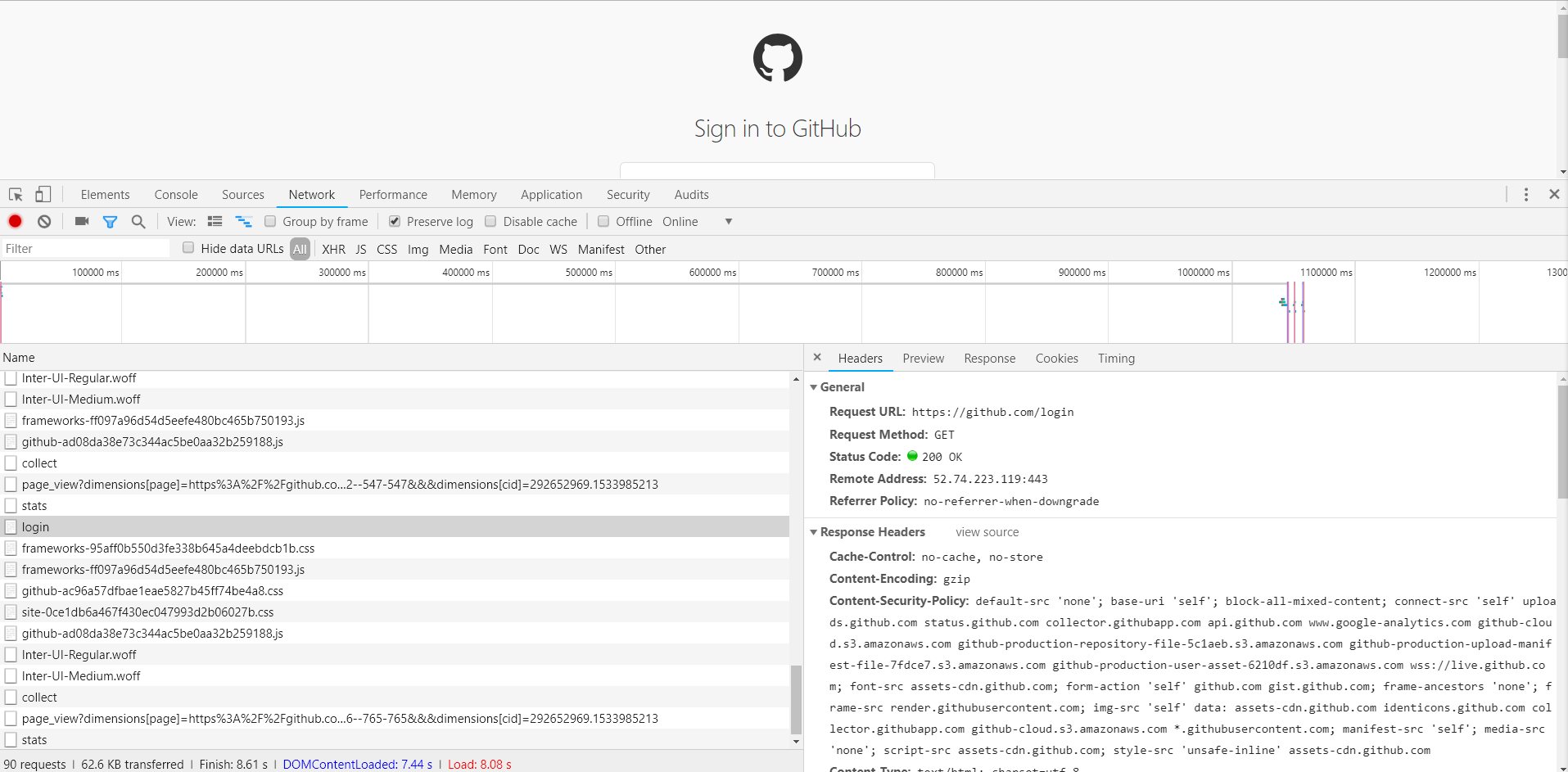
访问登陆页面的请求如上,Response Headers有一个Set-Cookie字段。这就是设置Cookies的过程。
另外,我们发现Response Headers没有和authenticity_token相关的信息,所以可能authenticity_token还隐藏在其他的地方或者是计算出来的
。我们再从网页的源码探寻,搜索相关字段,发现源代码里面还隐藏着此信息,他是一个隐藏式表单元素,如下图所示:
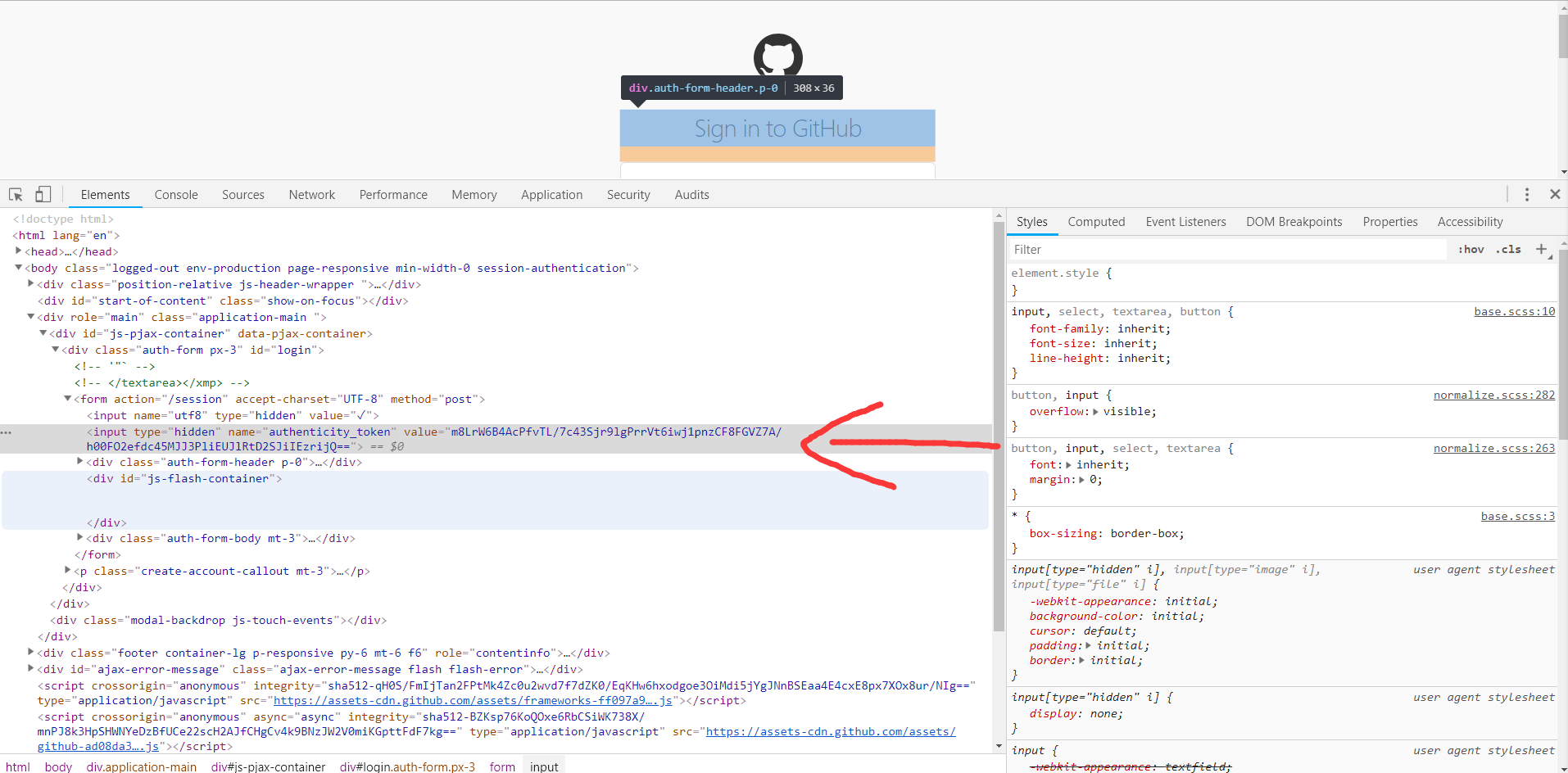
现在我们已经获取到网页所有信息,接下来让我们 实现模拟登陆
(3)代码如下:
import requests
from lxml import etree class Login(object):
def __init__(self):
self.headers = {
'Refer': 'https://github.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/68.0.3440.75 Safari/537.36',
'Host': 'github.com'
}
self.login_url = 'https://github.com/login'
self.post_url = 'https://github.com/session'
self.logined_url = 'https://github.com/settings/profile'
self.session = requests.Session() # 此函数可以帮助我们维持一个会话,而且可以自动处理cookies,我们不用再去担心cookies的问题 def token(self):
response = self.session.get(self.login_url, headers=self.headers) # 访问GitHub的登录页面
selector = etree.HTML(response.text)
token = selector.xpath('//div//input[2]/@value')[0] # 解析出登陆所需的authenticity_token信息
return token def login(self, email, password):
post_data = {
'commit': 'Sign in',
'utf-8': '✓',
'authenticity_token': self.token(),
'login': email,
'password': password
}
response = self.session.post(self.post_url, data=post_data, headers=self.headers)
if response.status_code == 200:
self.dynamics(response.text) response = self.session.get(self.logined_url, headers=self.headers)
if response.status_code == 200:
self.profile(response.text) def dynamics(self, html): # 使用此方法提取所有动态信息
selector = etree.HTML(html)
dynamics = selector.xpath('//div[contains(@class, "news")]//div[contains(@class, "alert")]')
for item in dynamics:
dynamics = ' '.join(item.xpath('.//div[@class="title"]//text()')).strip()
print(dynamics) def profile(self, html): # 使用此方法提取个人的昵称和绑定的邮箱
selector = etree.HTML(html)
name = selector.xpath('//input[@id="user_profile_name"]/@value')[0]
email = selector.xpath('//select[@id="user_profile_email"]/option[@value!=""]/text()')
print(name, email) if __name__ == "__main__":
login = Login()
login.login(email='', password='') # 此处填自己的
Python爬虫学习笔记之模拟登陆并爬去GitHub的更多相关文章
- python爬虫学习(3)_模拟登陆
1.登陆超星慕课,chrome抓包,模拟header,提取表单隐藏元素构成params. 主要是验证码图片地址,在js中发现由js->new Date().getTime()时间戳动态生成url ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- Python爬虫学习笔记——豆瓣登陆(三)
之前是不会想到登陆一个豆瓣会需要写三次博客,修改三次代码的. 本来昨天上午之前的代码用的挺好的,下午时候,我重新注册了一个号,怕豆瓣大号被封,想用小号爬,然后就开始出问题了,发现无法模拟登陆豆瓣了,开 ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
- Python爬虫学习笔记-1.Urllib库
urllib 是python内置的基本库,提供了一系列用于操作URL的功能,我们可以通过它来做一个简单的爬虫. 0X01 基本使用 简单的爬取一个页面: import urllib2 request ...
- Python爬虫学习笔记(一)
概念: 使用代码模拟用户,批量发送网络请求,批量获取数据. 分类: 通用爬虫: 通用爬虫是搜索引擎(Baidu.Google.Yahoo等)"抓取系统"的重要组成部分. 主要目的是 ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- 模拟登陆并爬取Github
因为崔前辈给出的代码运行有误,略作修改和简化了. 书上例题,不做介绍. import requests from lxml import etree class Login(object): def ...
随机推荐
- Ext JS 6学习文档–第2章–核心概念
核心概念 在下一章我们会构建一个示例项目,而在这之前,你需要学习一些在 Ext JS 中的核心概念,这有助于你更容易理解示例项目.这一章我们将学习以下知识点: 类系统,创建和扩展类 事件 Ext JS ...
- Icingaweb2监控oracle数据库的安装配置流程
Icinga2安装配置check_oracle_health流程 1.安装 由于check_oracle_health是使用perl语言编写的,因此在安装该插件之前,首先要安装oracle的客户端实例 ...
- 今年暑假不AC (贪心)
Description “今年暑假不AC?” “是的.” “那你干什么呢?” “看世界杯呀,笨蛋!” “@#$%^&*%...” 确实如此,世界杯来了,球迷的节日也来了,估计很多ACMer也会 ...
- Python 再谈字符串
字符串除了要用引号来创建之外,其他和元组一样,不能修改,如果要修改只能用切片或者拼接的方式. 其他的什么乱七八糟的运算符都一样 一些不同 capitalize()-将字符串的第一个字母大写 str1. ...
- Python 字符串与基本语句
Python特点 python中没有变量的声明 语句结束后没有分号 严格要求缩进 支持很长很长的大数运算(直接在Idle中输入即可) 用"#"来注释 BIF:Bulit-in fu ...
- 软工网络15团队作业4——Alpha阶段敏捷冲刺-1
各个成员在 Alpha 阶段认领的任务 成员 Alpha 阶段认领的任务 肖世松 编写界面设计代码 杨泽斌 服务器连接与配置 叶文柠 数据库连接与配置 谢庆圆 编写功能板块代码 林伟航 编写功能板块代 ...
- 【Python】Python中的下划线
单下划线(如: _var): 使用单下划线,用于指定该名变量或函数属性为“私有”.这仅仅是一个惯例,不是强制规定.用于向其他程序员表明这个变量或函数仅仅供内部使用,外部不要访问它.但实际上外部还是可以 ...
- Python文件传输模块ftplib
ftplib是基于FTP协议实现的一个Python模块 from ftplib import FTP # 创建一个FTP连接对象 ftp = FTP() #[ 当带有参数时,即:ftp = FTP(h ...
- git log 查看提交记录
git log 查看提交记录 1. git log 查看提交历史记录2. git log --oneline 或者 git log --pretty=oneline 以精简模式显示3. git log ...
- 【以前的空间】BZOJ2733[HNOI2012]永无乡
启发式合并?! 似乎当时写并查集的时候就有看到过类似于把小并查集并到大并查集上的说法,原来这就是启发式…… 具体做法就是把小树里面的一个个拿出来,然后加到大树里面去(裸的不敢相信) const max ...