FocusBI: 使用Python爬虫为BI准备数据源(原创)
关注微信公众号:FocusBI 查看更多文章;加QQ群:808774277 获取学习资料和一起探讨问题。
《商业智能教程》pdf下载地址
链接:https://pan.baidu.com/s/1f9VdZUXztwylkOdFLbcmWw 密码:2r4v
在为企业实施商业智能时,大部分都是使用内部数据建模和可视化;以前极少企业有爬虫工程师来为企业准备外部数据,最近一年来Python爬虫异常火爆,企业也开始招爬虫工程师为企业丰富数据来源。
我使用Python 抓取过一些网站数据,如:美团、点评、一亩田、租房等;这些数据并没有用作商业用途而是个人兴趣爬取下来做练习使用;这里我已 一亩田为例使用 scrapy框架去抓取它的数据。
一亩田
它是一个农产品网站,汇集了中国大部分农产品产地和市场行情,发展初期由百度系的人员创建,最初是招了大量的业务员去农村收集和教育农民把产品信息发布到一亩田网上..。
一亩田一开始是网页版,由于爬虫太多和农户在外劳作使用不方便而改成APP版废弃网页版,一亩田App反爬能力非常强悍;另外一亩田有一亩田产地行情和市场行情网页版,它的信息量也非常多,所以我选择爬取一亩田产地行情数据。
爬取一亩田使用的是Scrapy框架,这个框架的原理及dome我在这里不讲,直接给爬取一亩田的分析思路及源码;
一亩田爬虫分析思路
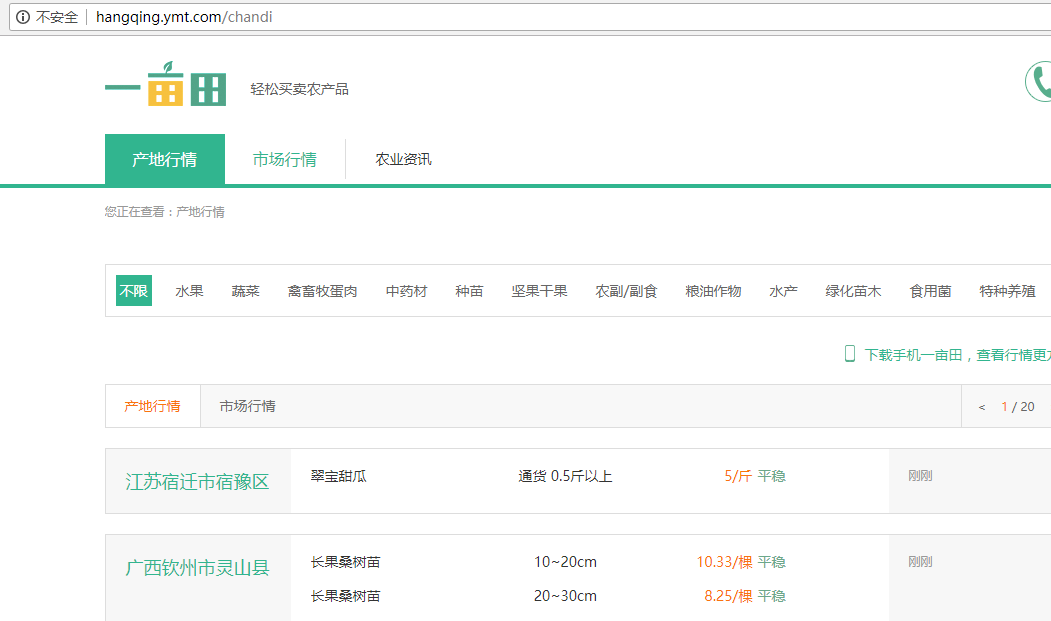
首先登陆一亩田产地行情:http://hangqing.ymt.com/chandi,看到农产品分类
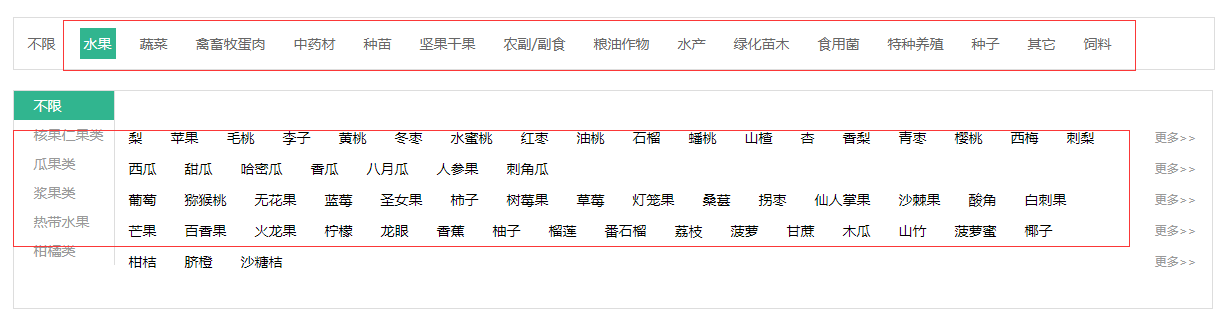
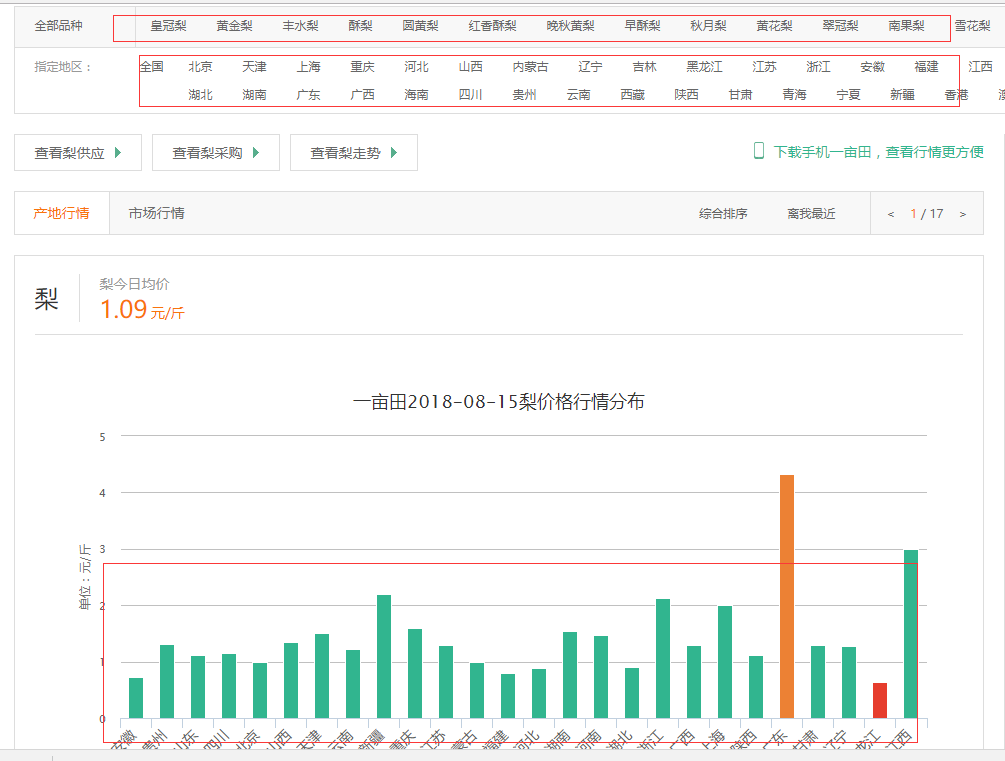
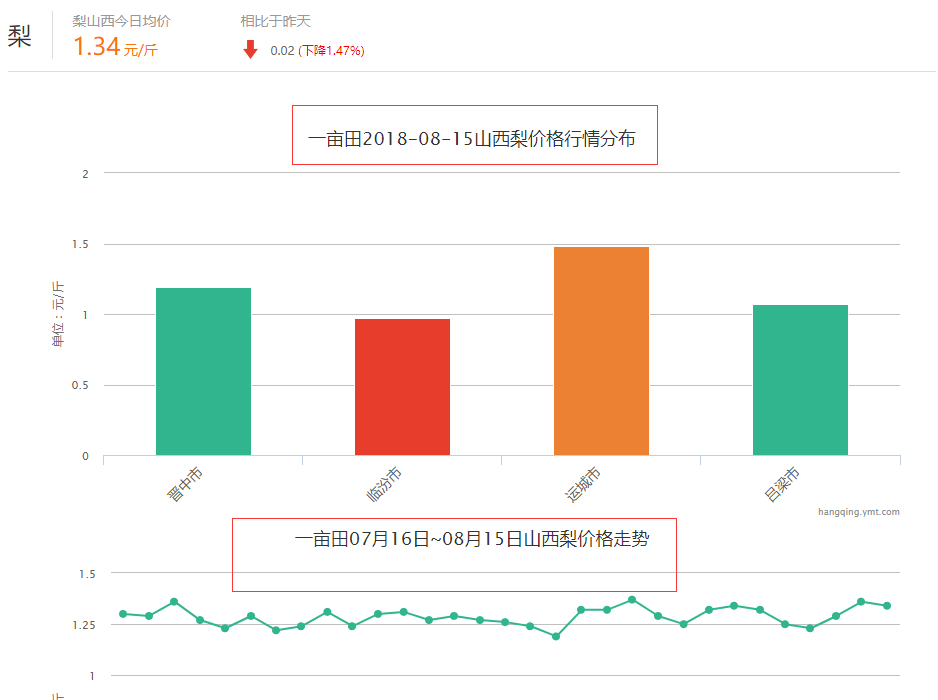
单击水果分类就能看到它下面有很多小分类,单击梨进入水果梨的行情页,能看到它下面有全部品种和指定地区选择一个省就能看到当天的行情和一个月的走势;
看到这一连串的网页我就根据这个思路去抓取数据。
一亩田爬虫源码
1.首先创建一个Spider
2.行情数据
抓取大类、中类、小类、品种 hangqing.py
# -*- coding: utf-8 -*-
import scrapy
from mySpider.items import MyspiderItem
from copy import deepcopy
import time class HangqingSpider(scrapy.Spider):
name = "hangqing"
allowed_domains = ["hangqing.ymt.com"]
start_urls = (
'http://hangqing.ymt.com/',
) # 大分类数据
def parse(self, response):
a_list = response.xpath("//div[@id='purchase_wrapper']/div//a[@class='hide']") for a in a_list:
items = MyspiderItem()
items["ymt_bigsort_href"] = a.xpath("./@href").extract_first()
items["ymt_bigsort_id"] = items["ymt_bigsort_href"].replace("http://hangqing.ymt.com/common/nav_chandi_", "")
items["ymt_bigsort_name"] = a.xpath("./text()").extract_first() # 发送详情页的请求
yield scrapy.Request(
items["ymt_bigsort_href"],
callback=self.parse_medium_detail,
meta={"item": deepcopy(items)}
) # 中分类数据 其中小类也包含在其中
def parse_medium_detail(self, response):
items = response.meta["item"]
li_list = response.xpath("//div[@class='cate_nav_wrap']//a")
for li in li_list:
items["ymt_mediumsort_id"] = li.xpath("./@data-id").extract_first()
items["ymt_mediumsort_name"] = li.xpath("./text()").extract_first()
yield scrapy.Request(
items["ymt_bigsort_href"],
callback=self.parse_small_detail,
meta={"item": deepcopy(items)},
dont_filter=True
) # 小分类数据
def parse_small_detail(self, response):
item = response.meta["item"]
mediumsort_id = item["ymt_mediumsort_id"]
if int(mediumsort_id) > 0:
nav_product_id = "nav-product-" + mediumsort_id
a_list = response.xpath("//div[@class='cate_content_1']//div[contains(@class,'{}')]//ul//a".format(nav_product_id))
for a in a_list:
item["ymt_smallsort_id"] = a.xpath("./@data-id").extract_first()
item["ymt_smallsort_href"] = a.xpath("./@href").extract_first()
item["ymt_smallsort_name"] = a.xpath("./text()").extract_first()
yield scrapy.Request(
item["ymt_smallsort_href"],
callback=self.parse_variety_detail,
meta={"item": deepcopy(item)}
) # 品种数据
def parse_variety_detail(self, response):
item = response.meta["item"]
li_list = response.xpath("//ul[@class='all_cate clearfix']//li")
if len(li_list) > 0:
for li in li_list:
item["ymt_breed_href"] = li.xpath("./a/@href").extract_first()
item["ymt_breed_name"] = li.xpath("./a/text()").extract_first()
item["ymt_breed_id"] = item["ymt_breed_href"].split("_")[2] yield item else:
item["ymt_breed_href"] = ""
item["ymt_breed_name"] = ""
item["ymt_breed_id"] = -1 yield item
3.产地数据
抓取省份、城市、县市 chandi.py
# -*- coding: utf-8 -*-
import scrapy
from mySpider.items import MyspiderChanDi
from copy import deepcopy class ChandiSpider(scrapy.Spider):
name = 'chandi'
allowed_domains = ['hangqing.ymt.com']
start_urls = ['http://hangqing.ymt.com/chandi_8031_0_0'] # 省份数据
def parse(self, response):
# 产地列表
li_list = response.xpath("//div[@class='fl sku_name']/ul//li")
for li in li_list:
items = MyspiderChanDi()
items["ymt_province_href"] = li.xpath("./a/@href").extract_first()
items["ymt_province_id"] = items["ymt_province_href"].split("_")[-1]
items["ymt_province_name"] = li.xpath("./a/text()").extract_first() yield scrapy.Request(
items["ymt_province_href"],
callback=self.parse_city_detail,
meta={"item": deepcopy(items)}
) # 城市数据
def parse_city_detail(self, response):
item = response.meta["item"]
option = response.xpath("//select[@class='location_select'][1]//option") if len(option) > 0:
for op in option:
name = op.xpath("./text()").extract_first()
if name != "全部":
item["ymt_city_name"] = name
item["ymt_city_href"] = op.xpath("./@data-url").extract_first()
item["ymt_city_id"] = item["ymt_city_href"].split("_")[-1]
yield scrapy.Request(
item["ymt_city_href"],
callback=self.parse_area_detail,
meta={"item": deepcopy(item)}
)
else:
item["ymt_city_name"] = ""
item["ymt_city_href"] = ""
item["ymt_city_id"] = 0
yield scrapy.Request(
item["ymt_city_href"],
callback=self.parse_area_detail,
meta={"item": deepcopy(item)} ) # 县市数据
def parse_area_detail(self, response):
item = response.meta["item"]
area_list = response.xpath("//select[@class='location_select'][2]//option") if len(area_list) > 0:
for area in area_list:
name = area.xpath("./text()").extract_first()
if name != "全部":
item["ymt_area_name"] = name
item["ymt_area_href"] = area.xpath("./@data-url").extract_first()
item["ymt_area_id"] = item["ymt_area_href"].split("_")[-1]
yield item
else:
item["ymt_area_name"] = ""
item["ymt_area_href"] = ""
item["ymt_area_id"] = 0
yield item
4.行情分布
location_char.py
# -*- coding: utf-8 -*-
import scrapy
import pymysql
import json
from copy import deepcopy
from mySpider.items import MySpiderSmallProvincePrice
import datetime class LocationCharSpider(scrapy.Spider):
name = 'location_char'
allowed_domains = ['hangqing.ymt.com']
start_urls = ['http://hangqing.ymt.com/'] i = datetime.datetime.now()
dateKey = str(i.year) + str(i.month) + str(i.day)
db = pymysql.connect(
host="127.0.0.1", port=3306,
user='root', password='mysql',
db='ymt_db', charset='utf8'
) def parse(self, response):
cur = self.db.cursor()
location_char_sql = "select small_id from ymt_price_small where dateKey = {} and day_avg_price > 0".format(self.dateKey) cur.execute(location_char_sql)
location_chars = cur.fetchall()
for ch in location_chars:
item = MySpiderSmallProvincePrice()
item["small_id"] = ch[0]
location_char_url = "http://hangqing.ymt.com/chandi/location_charts"
small_id = str(item["small_id"])
form_data = {
"locationId": "",
"productId": small_id,
"breedId": ""
}
yield scrapy.FormRequest(
location_char_url,
formdata=form_data,
callback=self.location_char,
meta={"item": deepcopy(item)}
) def location_char(self, response):
item = response.meta["item"] html_str = json.loads(response.text)
status = html_str["status"]
if status == 0:
item["unit"] = html_str["data"]["unit"]
item["dateKey"] = self.dateKey
dataList = html_str["data"]["dataList"]
for data in dataList:
if type(data) == type([]):
item["province_name"] = data[0]
item["province_price"] = data[1]
elif type(data) == type({}):
item["province_name"] = data["name"]
item["province_price"] = data["y"] location_char_url = "http://hangqing.ymt.com/chandi/location_charts"
small_id = str(item["small_id"])
province_name = str(item["province_name"])
province_id_sql = "select province_id from ymt_1_dim_cdProvince where province_name = \"{}\" ".format(province_name)
cur = self.db.cursor()
cur.execute(province_id_sql)
province_id = cur.fetchone() item["province_id"] = province_id[0] province_id = str(province_id[0])
form_data = {
"locationId": province_id,
"productId": small_id,
"breedId": ""
}
yield scrapy.FormRequest(
location_char_url,
formdata=form_data,
callback=self.location_char_province,
meta={"item": deepcopy(item)}
) def location_char_province(self, response):
item = response.meta["item"] html_str = json.loads(response.text)
status = html_str["status"] if status == 0:
dataList = html_str["data"]["dataList"]
for data in dataList:
if type(data) == type([]):
item["city_name"] = data[0]
item["city_price"] = data[1]
elif type(data) == type({}):
item["city_name"] = data["name"]
item["city_price"] = data["y"] location_char_url = "http://hangqing.ymt.com/chandi/location_charts"
small_id = str(item["small_id"])
city_name = str(item["city_name"])
city_id_sql = "select city_id from ymt_1_dim_cdCity where city_name = \"{}\" ".format(city_name)
cur = self.db.cursor()
cur.execute(city_id_sql)
city_id = cur.fetchone() item["city_id"] = city_id[0] city_id = str(city_id[0])
form_data = {
"locationId": city_id,
"productId": small_id,
"breedId": ""
}
yield scrapy.FormRequest(
location_char_url,
formdata=form_data,
callback=self.location_char_province_city,
meta={"item": deepcopy(item)}
) def location_char_province_city(self, response):
item = response.meta["item"] html_str = json.loads(response.text)
status = html_str["status"] if status == 0:
dataList = html_str["data"]["dataList"]
for data in dataList:
if type(data) == type([]):
item["area_name"] = data[0]
item["area_price"] = data[1]
elif type(data) == type({}):
item["area_name"] = data["name"]
item["area_price"] = data["y"]
area_name = item["area_name"]
area_id_sql = "select area_id from ymt_1_dim_cdArea where area_name = \"{}\" ".format(area_name)
cur1 = self.db.cursor()
cur1.execute(area_id_sql)
area_id = cur1.fetchone() item["area_id"] = area_id[0] breed_id_sql = "select breed_id from ymt_all_info_sort where small_id = {} and breed_id > 0".format(item["small_id"])
cur1.execute(breed_id_sql)
breed_ids = cur1.fetchall()
# print(len(breed_ids))
location_char_url = "http://hangqing.ymt.com/chandi/location_charts"
for breed_id in breed_ids:
item["breed_id"] = breed_id[0]
form_data = {
"locationId": str(item["city_id"]),
"productId": str(item["small_id"]),
"breedId": str(breed_id[0])
}
# print(form_data, breed_id)
yield scrapy.FormRequest(
location_char_url,
formdata=form_data,
callback=self.location_char_province_city_breed,
meta={"item": deepcopy(item)}
) def location_char_province_city_breed(self, response):
item = response.meta["item"] html_str = json.loads(response.text)
status = html_str["status"] if status == 0:
dataList = html_str["data"]["dataList"]
for data in dataList:
if type(data) == type([]):
item["breed_city_name"] = data[0]
item["breed_city_price"] = data[1]
elif type(data) == type({}):
item["breed_city_name"] = data["name"]
item["breed_city_price"] = data["y"] yield item
5.价格走势
pricedata.py
# -*- coding: utf-8 -*-
import scrapy
import pymysql.cursors
from copy import deepcopy
from mySpider.items import MySpiderSmallprice import datetime
import json class PricedataSpider(scrapy.Spider):
name = 'pricedata'
allowed_domains = ['hangqing.ymt.com']
start_urls = ['http://hangqing.ymt.com/chandi_8031_0_0']
i = datetime.datetime.now() def parse(self, response):
db = pymysql.connect(
host="127.0.0.1", port=3306,
user='root', password='mysql',
db='ymt_db', charset='utf8'
)
cur = db.cursor() all_small_sql = "select distinct small_id,small_name,small_href from ymt_all_info_sort" cur.execute(all_small_sql)
small_all = cur.fetchall() for small in small_all:
item = MySpiderSmallprice()
item["small_href"] = small[2]
# item["small_name"] = small[1]
item["small_id"] = small[0]
yield scrapy.Request(
item["small_href"],
callback=self.small_breed_info,
meta={"item": deepcopy(item)}
) def small_breed_info(self, response):
item = response.meta["item"]
item["day_avg_price"] = response.xpath("//dd[@class='c_origin_price']/p[2]//span[1]/text()").extract_first()
item["unit"] = response.xpath("//dd[@class='c_origin_price']/p[2]//span[2]/text()").extract_first()
item["dateKey"] = str(self.i.year)+str(self.i.month)+str(self.i.day) if item["day_avg_price"] is None:
item["day_avg_price"] = 0
item["unit"] = "" yield item
6.设计字典
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy # 行情爬虫字段 class MyspiderItem(scrapy.Item):
ymt_bigsort_href = scrapy.Field()
ymt_bigsort_id = scrapy.Field()
ymt_bigsort_name = scrapy.Field()
ymt_mediumsort_id = scrapy.Field()
ymt_mediumsort_name = scrapy.Field()
ymt_smallsort_id = scrapy.Field()
ymt_smallsort_href = scrapy.Field()
ymt_smallsort_name = scrapy.Field()
ymt_breed_id = scrapy.Field()
ymt_breed_name = scrapy.Field()
ymt_breed_href = scrapy.Field() # 产地爬虫字段 class MyspiderChanDi(scrapy.Item):
ymt_province_id = scrapy.Field()
ymt_province_name = scrapy.Field()
ymt_province_href = scrapy.Field()
ymt_city_id = scrapy.Field()
ymt_city_name = scrapy.Field()
ymt_city_href = scrapy.Field()
ymt_area_id = scrapy.Field()
ymt_area_name = scrapy.Field()
ymt_area_href = scrapy.Field() # 小类产地价格 class MySpiderSmallprice(scrapy.Item):
small_href = scrapy.Field()
small_id = scrapy.Field()
day_avg_price = scrapy.Field()
unit = scrapy.Field()
dateKey = scrapy.Field() # 小分类 省份/城市/县市 价格 class MySpiderSmallProvincePrice(scrapy.Item):
small_id = scrapy.Field()
unit = scrapy.Field()
province_name = scrapy.Field()
province_price = scrapy.Field() # 小类 省份 均价
province_id = scrapy.Field()
city_name = scrapy.Field()
city_price = scrapy.Field() # 小类 城市 均价
city_id = scrapy.Field()
area_name = scrapy.Field()
area_price = scrapy.Field() # 小类 县市均价
area_id = scrapy.Field() breed_city_name = scrapy.Field()
breed_city_price = scrapy.Field()
breed_id = scrapy.Field() dateKey = scrapy.Field()
7.数据入库
pipelines.py
# -*- coding: utf-8 -*- from pymongo import MongoClient
import pymysql.cursors class MyspiderPipeline(object):
def open_spider(self, spider):
# client = MongoClient(host=spider.settings["MONGO_HOST"], port=spider.settings["MONGO_PORT"])
# self.collection = client["ymt"]["hangqing"]
pass def process_item(self, item, spider):
db = pymysql.connect(
host="127.0.0.1", port=3306,
user='root', password='mysql',
db='ymt_db', charset='utf8'
)
cur = db.cursor() if spider.name == "hangqing": # 所有 分类数据
all_sort_sql = "insert into ymt_all_info_sort(big_id, big_name, big_href, " \
"medium_id, medium_name, " \
"small_id, small_name, small_href, " \
"breed_id, breed_name, breed_href) " \
"VALUES({},\"{}\",\"{}\",\"{}\",\"{}\",\"{}\",\"{}\",\"{}\",\"{}\",\"{}\",\"{}\")".format(
item["ymt_bigsort_id"], item["ymt_bigsort_name"], item["ymt_bigsort_href"],
item["ymt_mediumsort_id"], item["ymt_mediumsort_name"],
item["ymt_smallsort_id"], item["ymt_smallsort_name"], item["ymt_smallsort_href"],
item["ymt_breed_id"], item["ymt_breed_name"], item["ymt_breed_href"]) try:
cur.execute(all_sort_sql)
db.commit() except Exception as e:
db.rollback()
finally:
cur.close()
db.close() return item elif spider.name == "chandi": # 所有的产地数据
all_cd_sql = "insert into ymt_all_info_cd(" \
"province_id, province_name, province_href, " \
"city_id, city_name, city_href," \
"area_id, area_name, area_href) " \
"VALUES({},\"{}\",\"{}\",{},\"{}\",\"{}\",{},\"{}\",\"{}\")".format(
item["ymt_province_id"], item["ymt_province_name"], item["ymt_province_href"],
item["ymt_city_id"], item["ymt_city_name"], item["ymt_city_href"],
item["ymt_area_id"], item["ymt_area_name"], item["ymt_area_href"])
try:
# 产地数据
cur.execute(all_cd_sql)
db.commit()
except Exception as e:
db.rollback() finally:
cur.close()
db.close() return item elif spider.name == "pricedata":
avg_day_price_sql = "insert into ymt_price_small(small_href, small_id, day_avg_price, unit, dateKey) " \
"VALUES(\"{}\",{},{},\"{}\",\"{}\")".format(item["small_href"], item["small_id"], item["day_avg_price"], item["unit"], item["dateKey"])
try:
cur.execute(avg_day_price_sql)
db.commit()
except Exception as e:
db.rollback()
finally:
cur.close()
db.close() elif spider.name == "location_char":
location_char_sql = "insert into ymt_price_provice(small_id, province_name, provice_price, city_name, city_price, area_name, area_price,unit, dateKey, area_id, city_id, provice_id, breed_city_name, breed_city_price, breed_id) " \
"VALUES({},\"{}\",{},\"{}\",{},\"{}\",{},\"{}\",{},{},{},{},\"{}\",{},{})".format(item["small_id"], item["province_name"], item["province_price"], item["city_name"], item["city_price"],
item["area_name"], item["area_price"], item["unit"], item["dateKey"],
item["area_id"], item["city_id"], item["province_id"],
item["breed_city_name"], item["breed_city_price"], item["breed_id"])
try:
cur.execute(location_char_sql)
db.commit()
except Exception as e:
db.rollback()
finally:
cur.close()
db.close() else:
cur.close()
db.close()
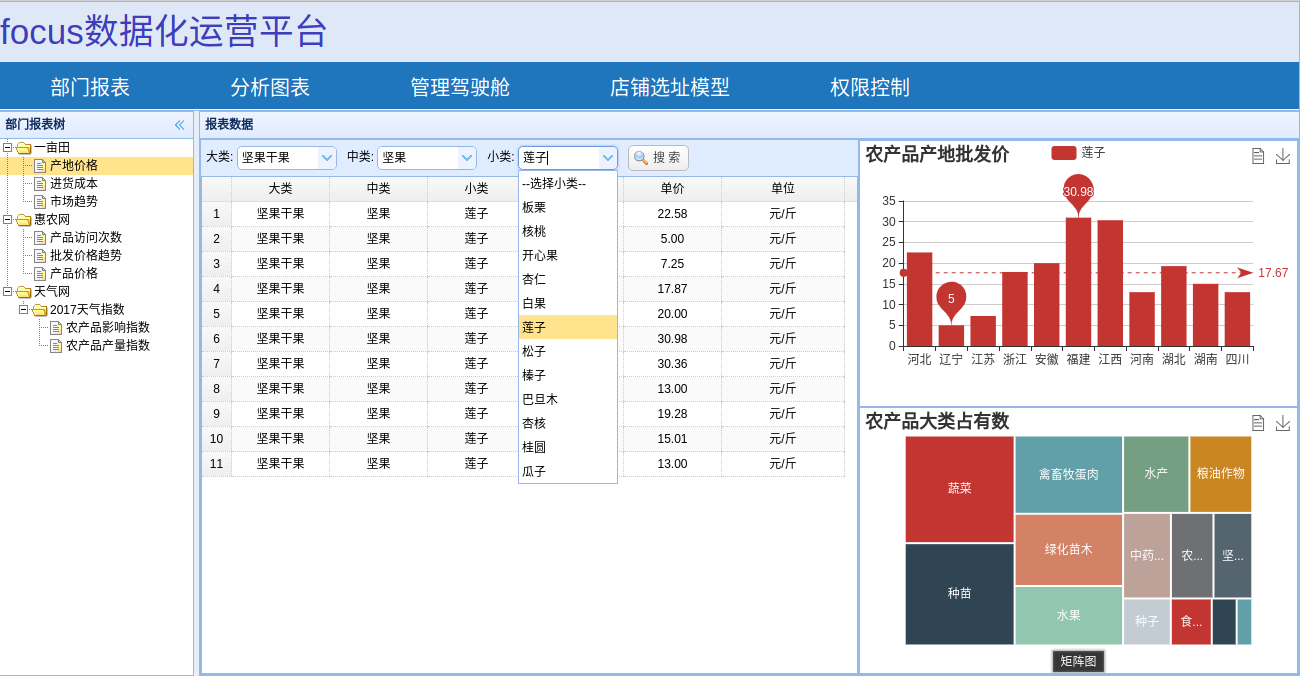
最后结果
出于个人兴趣,最后把爬取下来的农产品信息变成了一个WEB系统。
历史文章:
FocusBI: 使用Python爬虫为BI准备数据源(原创)
FocusBI关注者
FocusBI:SSAS体系结构(原创)
FocusBI:租房分析&星型模型
FocusBI:地产分析&雪花模型
FocusBI:MDX检索多维模型
FocusBI:租房分析可视化(网址体验)
FocusBI: 《DW/BI项目管理》之数据库表结构 (原创)
FocusBI: 使用Python爬虫为BI准备数据源(原创)的更多相关文章
- Python爬虫框架Scrapy学习笔记原创
字号 scrapy [TOC] 开始 scrapy安装 首先手动安装windows版本的Twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/#twi ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- python爬虫的一个常见简单js反爬
python爬虫的一个常见简单js反爬 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成coo ...
- 写博客没高质量配图?python爬虫教你绕过限制一键搜索下载图虫创意图片!
目录 前言 分析 理想状态 爬虫实现 其他注意 效果与总结 @(文章目录) 前言 在我们写文章(博客.公众号.自媒体)的时候,常常觉得自己的文章有些老土,这很大程度是因为配图没有选好. 笔者也是遇到相 ...
- 小白学 Python 爬虫(25):爬取股票信息
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
随机推荐
- Verilog MIPS32 CPU(四)-- RAM
Verilog MIPS32 CPU(一)-- PC寄存器 Verilog MIPS32 CPU(二)-- Regfiles Verilog MIPS32 CPU(三)-- ALU Verilog M ...
- 虚拟化 - Docker
Docker Desktop (for windows and mac) Docker Desktop 注意 安装时有可能卡主,可以关掉重新装 重启启动时,可能报错"VIRTUALIZATI ...
- 【08】循序渐进学 docker:docker compose
写在前面的话 在之前的操作中,即使是单个容器每次都需要敲很长的命令,当需要多个容器组合着用的时候更加麻烦,此时我们急需找到一种一次配置,随便运行的方法. 这就是这一节重点,单机容器编排工具:docke ...
- Rabbitmq消息服务器通讯异常: name must not be blank
前人挖坑,后人填! 倒霉的遇到一个破项目,该 项目使用了 RabbitMQ 消息队列向服务器发送消息, 但在发送中老是报 RabbitMQ 服务器异常! 呃,查看了服务器,服务器好好的,日志中却是这样 ...
- Spring boot整合Mongodb
最近的项目用了Mongodb,网上的用法大多都是七零八落的没有一个统一性,自己大概整理了下,项目中的相关配置就不叙述了,由于spring boot的快捷开发方式,所以spring boot项目中要使用 ...
- codis__数据迁移和伸缩容
数据迁移命令 注意点:是迁移到某个 redis-group 而不是某个redis-servers 实例 伸缩容用法 redis 内存等不够用时 增容 : 增加redis-group, 然后迁移使用上 ...
- [redis] 数据特性简单实验
位图 由bit位组成的数组,实际的底层数组类型是字符串,而字符串的本质是二进制大对象,所以将其视作位图,位图存储的是boolean指,一定程度上可以减少存储空间. -- 设置位图指定偏移量的比特位的值 ...
- 2016级算法第五次上机-E.AlvinZH的学霸养成记IV
1039 AlvinZH的学霸养成记IV 思路 难题,最大二分图匹配. 难点在于如何转化问题,n对n,一个只能攻击一个,判断是否存在一种攻击方案我方不死团灭对方.可以想到把所有随从看作点,对于可攻击的 ...
- C#使用Redis的基本操作
一,引入dll 1.ServiceStack.Common.dll 2.ServiceStack.Interfaces.dll 3.ServiceStack.Redis.dll 4.ServiceSt ...
- ListView-电影列表
import React, { Component } from 'react';import { Platform, StyleSheet, Text, View, ListView } from ...