Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影)
ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互
对于ajax:
- 1.一定会有 url,请求方法(get, post),可能有数据
- 2.一般使用 json 格式
爬取豆瓣电影
- 网站分析:
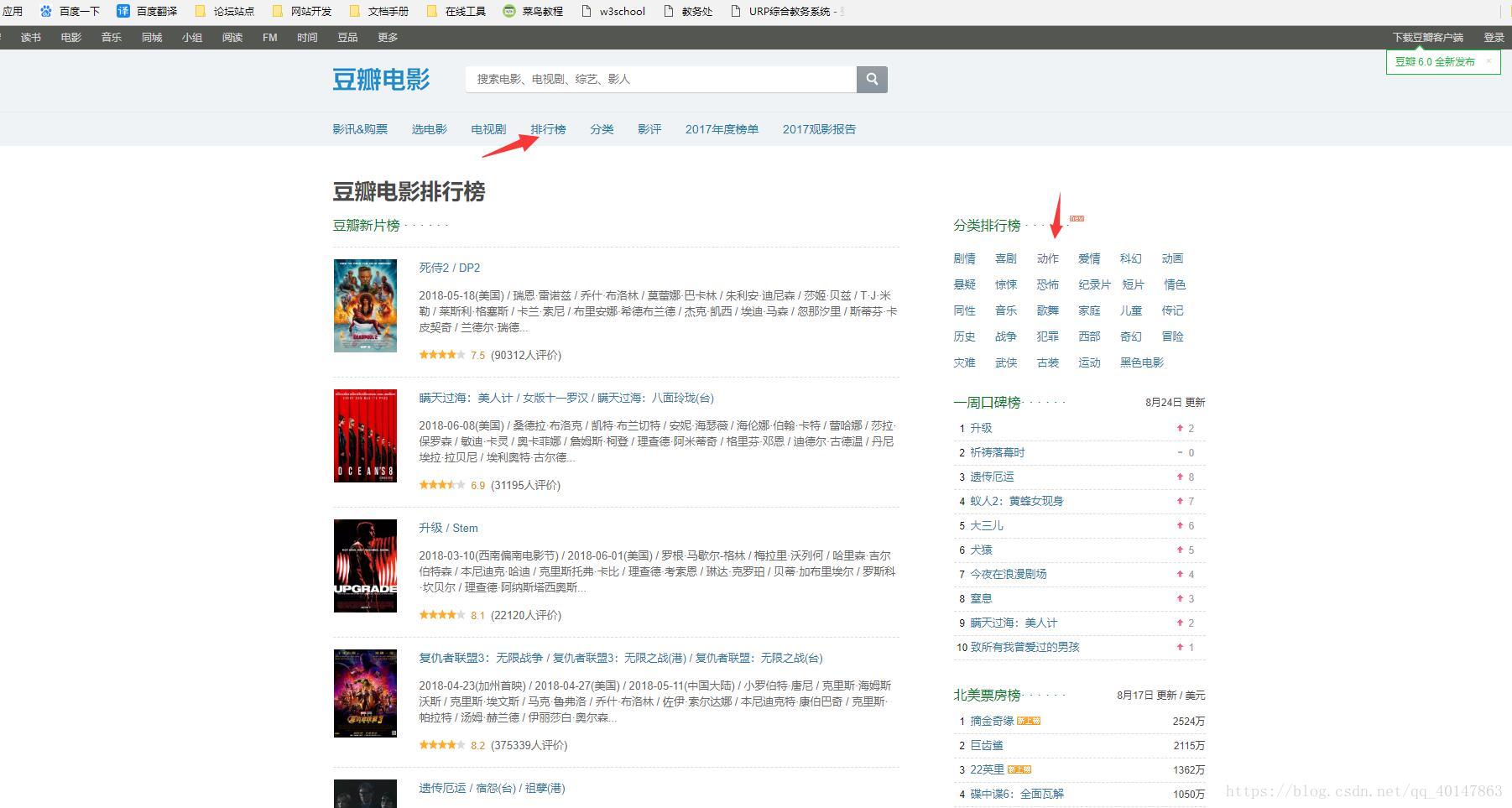
- 打开豆瓣电影网站:https://movie.douban.com/,选择【排行榜】,点击【动作】分类
- 一直往下滑,可以看到这样的效果:快到低的时候又有了新的内容,也就是往下没完
- 基本可以判定使用了 ajax 请求,进行异步的加载
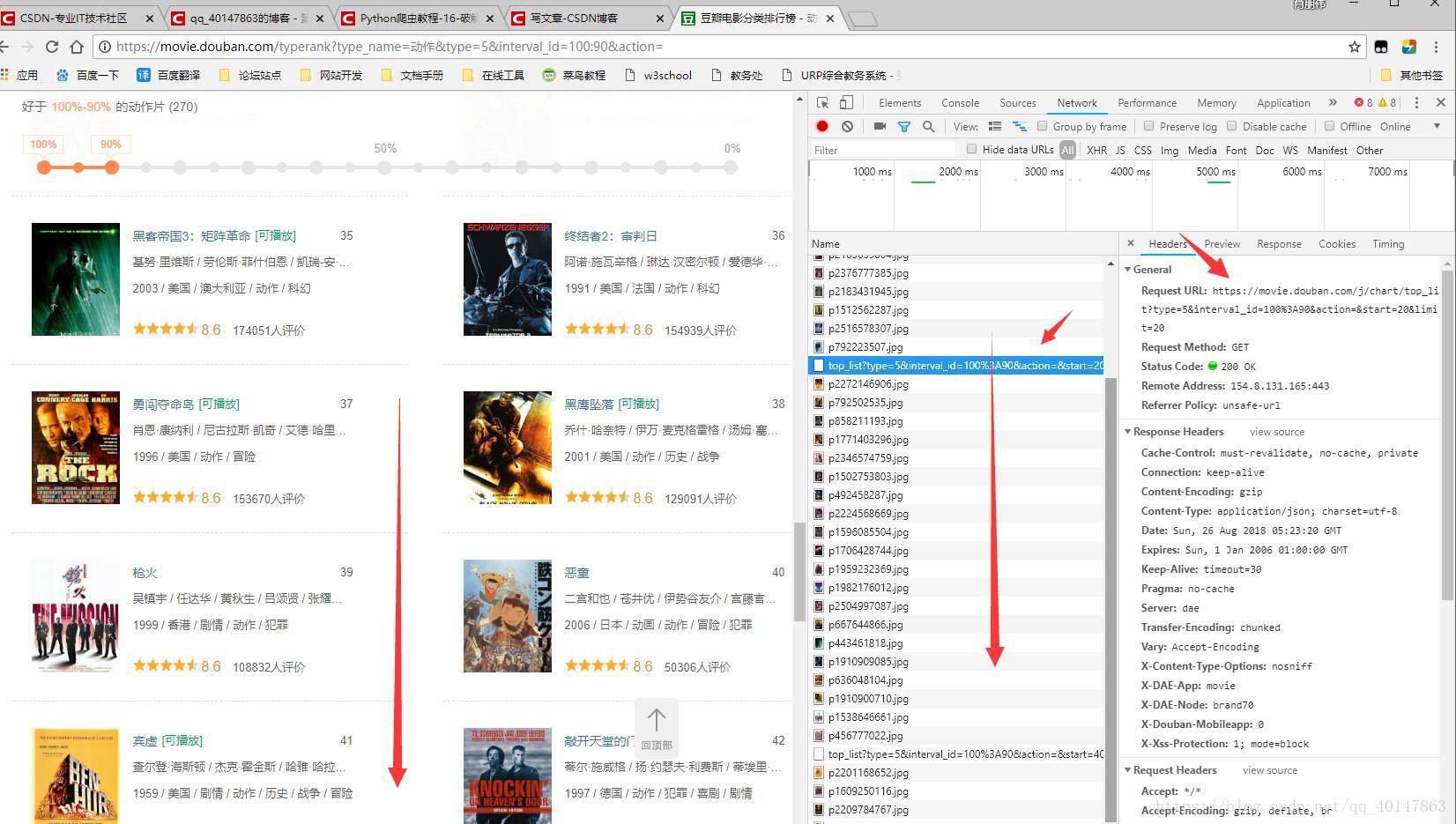
- 然后进去检查请求的信息:
- 1.右键【检查】>【Network】
- 2.向下滚动页面
- 3.可以看到请求在不断不更新,点击一个请求,就可以看到请求的信息
- 代码文件:https://xpwi.github.io/py/py爬虫/py19db.py
# 爬取豆瓣电影数据
# 了解ajax的爬取方式
# https://movie.douban.com/
from urllib import request
import json
# url信息:interval_id表示排名段(可自行修改),limit限制20个
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20"
rsp = request.urlopen(url)
data = rsp.read().decode()
data = json.loads(data)
print(data)
运行结果
可以看到结果在一行显示

修改输出格式
- 对于返回的json数据,我们选择想要的内容,想要的格式输出
- 代码文件:https://xpwi.github.io/py/py爬虫/py19db2.py
# 爬取豆瓣电影数据
# 了解ajax的爬取方式
# https://movie.douban.com/
from urllib import request
import json
# url信息:interval_id表示排名段(可自行修改),limit限制20个
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20"
rsp = request.urlopen(url)
data = rsp.read().decode()
data = json.loads(data)
# 遍历输出每个'k'和'v'的值
for item in data:
print("排名:", item['rank'], "\n",
"名称:", item['title'], "\n",
"类型:", item['types'], "\n",
"主演:", item['actors'], "\n",
"分数:", item['score'],"\n-------------",)
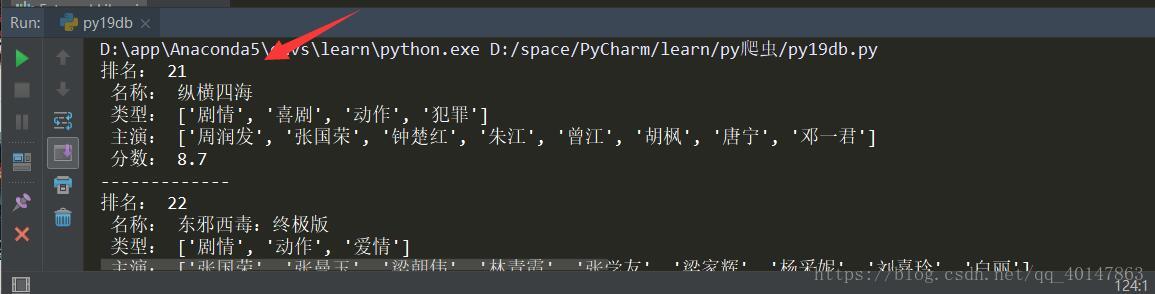
运行结果
这里结果就比较顺眼了,如果需要更改排名段,因为是get请求,修改需要在url参数即可
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-17-ajax爬取实例(豆瓣电影)的更多相关文章
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译) 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- 简单的python爬虫教程:批量爬取图片
python编程语言,可以说是新型语言,也是这两年来发展比较快的一种语言,而且不管是少儿还是成年人都可以学习这个新型编程语言,今天南京小码王python培训机构变为大家分享了一个python爬虫教程. ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
随机推荐
- LOJ6500. 「雅礼集训 2018 Day2」操作(哈希+差分)
题目链接 https://loj.ac/problem/6500 题解 区间取反 \(01\) 串的经典套路是差分.我们令 \(b_i = a_i\ {\rm xor}\ a_{i - 1}\)(\( ...
- yum的repo文件详解、以及epel简介、yum源的更换
一.什么是repo文件 repo文件是Fedora中yum源(软件仓库)的配置文件,通常一个repo文件定义了一个或者多个软件仓库的细节内容,例如我们将从哪里下载需要安装或者升级的软件包 ...
- unity+Helios制作360°全景VR视频
unity版本 unity2017.2.0 Helios版本:Helios 1.3.6 ffmpeg:ffmpeg-20180909-404d21f-win64-static(地址:https:// ...
- 12.2.0.1 restart环境执行root.sh 报 CLSRSC-400 错误
问题描述: 在LINUX 7.5 的环境上安装12.2.0.1 Restart Grid环境,执行root.sh 报 CLSRSC-400 错误 错误如下: 解决办法: 1. 参考(文档ID 136 ...
- Tomcat 9内存溢出:"http-apr-8080-Acceptor-0" java.lang.OutOfMemoryError: Direct buffer memory
Tomcat开启了APR模式,而APR模式会使用堆外内存,关于堆内存可从如下链接了解一下:http://blog.csdn.net/zhouhl_cn/article/details/6573213. ...
- JS实现OO机制
一.简单原型机制介绍 继承是OO语言的标配,基本所有的语言都有继承的功能,使用继承方便对象的一些属性和方法的共享,Javascript也从其他OO语言上借鉴了这种思想,当一个函数通过"new ...
- Robot Framework自动化测试四(分层思想)
谈到Robot Framework 分层的思想,就不得不提“关键字驱动”. 关键字驱动: 通过调用的关键字不同,从而引起测试结果的不同. 在上一节的selenium API 中所介绍的方法其实就是关 ...
- 读写锁--ReentrantReadWriteLock
读写锁,对于读操作来说是共享锁,对于写操作来说是排他锁,两种操作都可重入的一种锁.底层也是用AQS来实现的,我们来看一下它的结构跟代码: ------------------------------- ...
- ArrayList、Vector和LinkedList等的差别与用法(基础回顾)
ArrayList 和Vector是采取数组体式格式存储数据,此数组元素数大于实际存储的数据以便增长和插入元素,都容许直接序号索引元素,然则插入数据要设计到数组元素移动等内存操纵,所以索引数据快插入数 ...
- 关于定位和z-index的一些小经历
今天在工作过程中,遇到这么一个奇葩问题,搞了好一阵子才找到原因,遂总结了一下... 先上DEMO: <div style="width:800px; height:400px;&quo ...