Python爬虫教程-29-验证码识别-Tesseract-OCR
本篇是关于验证码识别问题,也是Python爬虫笔记的一个结尾,使用 Tesseract
Python爬虫教程-29-验证码识别-Tesseract-OCR
- 常见反爬虫手段:
- 验证码
- 1.简单图片,扭曲数字验证码
- 2.中文顺序点击
- 3.动态验证码
- 4.滑动验证:滑动小方块到缺口
- 5.语音验证
- 6.极验验证:官网:http://www.geetest.com/
根据鼠标轨迹,判定是机器人还是用户,很强大的验证机制
- 验证码
- 对于极验是很厉害的拦截机器人手段,好像是使用人工智能机器学习,当然自己想做验证的话建议使用。对于验证有反爬虫,就有可能有反反爬虫
爬虫-验证码识别
- 通用方法:
- 1.下载网页和验证码,或截图
- 2.然后手动输入验证码
- 对于简单图片
- 1.使用图像识别软件或者文字识别软件
- 2.可以使用第三方图像验证码破解网站
- 比如:超级鹰:http://www.chaojiying.com/
- 对于极验,官网:http://www.geetest.com/
- 可以模拟鼠标移动,具体的方法我还不清楚
通用方法案例
- 能力有限,这里就介绍通用方法,先下载得到验证图片,然后手动输入
- Tesseract
- 机器视觉领域的基础软件
- OCR:OpticalChracterRecognition,光学文字识别
- Tesseract:是一个 OCR 库,由 Google 赞助
Tesseract-Windows的安装
- Tesseract Windows安装包下载:https://digi.bib.uni-mannheim.de/tesseract/
- 上面链接看着头疼就下我的网盘里的:
- 安装的话就默认安装就好,如果选中那个在线安装包,会很慢,耐心等下
- 路径最好不要更改,除非熟练掌握环境变量
Tesseract-macOS的安装
- 我也没有 MacBook,老师顺口一说,记下了
- brew install tesseract
Tesseract-Linux的安装
- 我这里是 Ubuntu 18 其他 Linux 版本不确定,进入管理员用户
- apt-get install tesseract-ocr
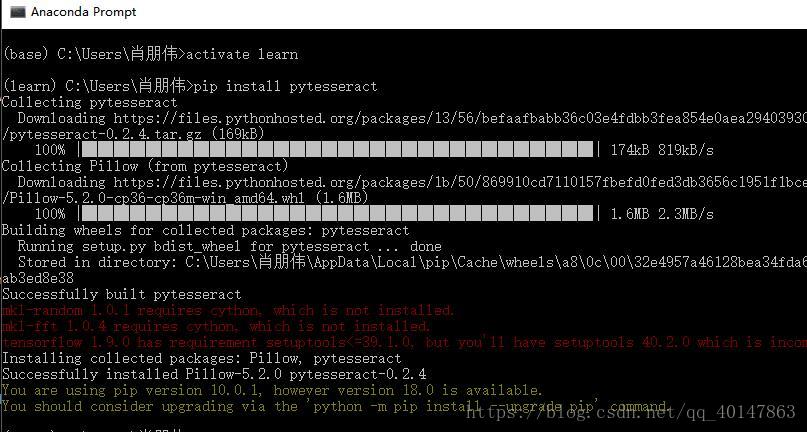
python使用tesseract的工具 pytesseract 的安装
- 如果使用的是 Anaconda 环境:
- 进入当前环境:(我的环境名为learn,如果只有一个base环境,忽略此步)
activate learn
- 安装 pytesseract
pip install pytesseract
- 操作截图
- 首先说一下,conda 是没有这个包的,也就不能使用 conda install,也不能直接在 Pycharm 里找到,只有使用 pip 安装,然后需要注意的就是,要使用你在 Pycharm 使用的那个环境进行安装
识别验证码案例
- 注意:此代码路径是,在图片和代码在同一目录
- 图片截图:
- 代码 py30pytess.py 文件:

import pytesseract as pt
from PIL import Image
# 生成图片实例
image = Image.open('timg.jpg')
# 调用 pytesseract 识别图片文字
text = pt.image_to_string(image)
print(text)
运行结果
- 这里是错了一个字符,因为需要用很多数据去训练,才能得到更高的准确率
- 如果想看训练的部分,点击:Tesseract-OCR-02-使用 jTessBoxEditor 提高文字识别准确率

更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-29-验证码识别-Tesseract-OCR的更多相关文章
- Python爬虫教程:验证码的爬取和识别详解
今天要给大家介绍的是验证码的爬取和识别,不过只涉及到最简单的图形验证码,也是现在比较常见的一种类型. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
Python爬虫教程-12-爬虫使用cookie(上) 爬虫关于cookie和session,由于http协议无记忆性,比如说登录淘宝网站的浏览记录,下次打开是不能直接记忆下来的,后来就有了cooki ...
- 简单的python爬虫教程:批量爬取图片
python编程语言,可以说是新型语言,也是这两年来发展比较快的一种语言,而且不管是少儿还是成年人都可以学习这个新型编程语言,今天南京小码王python培训机构变为大家分享了一个python爬虫教程. ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块 今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error URLError URLError ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
随机推荐
- 解析XMl文档和字符串
//解析xml字符串 txt="<bookstore><book>"; txt=txt+"<title>Everyday Italia ...
- 关于如何爬虫妹子图网的源码分析 c#实现
网上也出现一些抓取妹子图的python 代码,今天我们用c#实现爬虫过程. 请看我的网站: www.di81.com private void www_94xmn_Com(string url, st ...
- 2018牛客多校2 - J farm 随机乱搞/二进制分组
题意:给定n*m的格子,每个格子有不同的种类,q次操作,每次操作使[x1,y1]到[x2,y2]的格子除了k类型的以外都删除,最后单次询问所有格子被删了几个 官方题解提到了两种有意思的做法,随机和二进 ...
- (转)Go语言核心36讲之Go语言入门基础知识
- oracle client 低于 oracle server 端,导致报错ORA-01882
https://forums.toadworld.com/t/ora-01882-when-i-want-to-view-records-con-dba-scheduler-jobs-toad-10- ...
- springboot 头像上传 文件流保存 文件流返回浏览器查看 区分操作系统 windows 7 or linux
//我的会员中心 头像上传接口 /*windows 调试*/ @Value("${appImg.location}") private String winPathPic; /*l ...
- SpringBoot + Quartz定时任务示例
程序文件结构,如下图,后面详细列出各文件的代码: 1. maven的pom.xml文件如下: <project xmlns="http://maven.apache.org/POM/4 ...
- Python中socket经ssl加密后server开多线程
前几天手撸Python socket代码,撸完之后经过ssl加密,确保数据的安全,外加server端开启多线程保证一个客户端连接有一个线程来服务客户端,走了不少的弯路,网上的信息啥的要 ...
- Vim常用插件——前端开发工具系列
作为一名开发者,应该对编辑器之神Vim与神之编辑器Emacs有所耳闻吧.编辑器之战的具体细节有兴趣的童鞋可以google之. Vim最大的特点是打开速度快,功能强大,一旦掌握了其中的命令,编程过程双手 ...
- xmanager连接redhat(centos)
1.以连接Centos6.5为例,先关闭防火墙 service iptables stop chkconfig --level 345 iptables off 2.安装XDM,通过 XDMCP 支持 ...