Python爬虫教程-29-验证码识别-Tesseract-OCR
本篇是关于验证码识别问题,也是Python爬虫笔记的一个结尾,使用 Tesseract
Python爬虫教程-29-验证码识别-Tesseract-OCR
- 常见反爬虫手段:
- 验证码
- 1.简单图片,扭曲数字验证码
- 2.中文顺序点击
- 3.动态验证码
- 4.滑动验证:滑动小方块到缺口
- 5.语音验证
- 6.极验验证:官网:http://www.geetest.com/
根据鼠标轨迹,判定是机器人还是用户,很强大的验证机制
- 验证码
- 对于极验是很厉害的拦截机器人手段,好像是使用人工智能机器学习,当然自己想做验证的话建议使用。对于验证有反爬虫,就有可能有反反爬虫
爬虫-验证码识别
- 通用方法:
- 1.下载网页和验证码,或截图
- 2.然后手动输入验证码
- 对于简单图片
- 1.使用图像识别软件或者文字识别软件
- 2.可以使用第三方图像验证码破解网站
- 比如:超级鹰:http://www.chaojiying.com/
- 对于极验,官网:http://www.geetest.com/
- 可以模拟鼠标移动,具体的方法我还不清楚
通用方法案例
- 能力有限,这里就介绍通用方法,先下载得到验证图片,然后手动输入
- Tesseract
- 机器视觉领域的基础软件
- OCR:OpticalChracterRecognition,光学文字识别
- Tesseract:是一个 OCR 库,由 Google 赞助
Tesseract-Windows的安装
- Tesseract Windows安装包下载:https://digi.bib.uni-mannheim.de/tesseract/
- 上面链接看着头疼就下我的网盘里的:
- 安装的话就默认安装就好,如果选中那个在线安装包,会很慢,耐心等下
- 路径最好不要更改,除非熟练掌握环境变量
Tesseract-macOS的安装
- 我也没有 MacBook,老师顺口一说,记下了
- brew install tesseract
Tesseract-Linux的安装
- 我这里是 Ubuntu 18 其他 Linux 版本不确定,进入管理员用户
- apt-get install tesseract-ocr
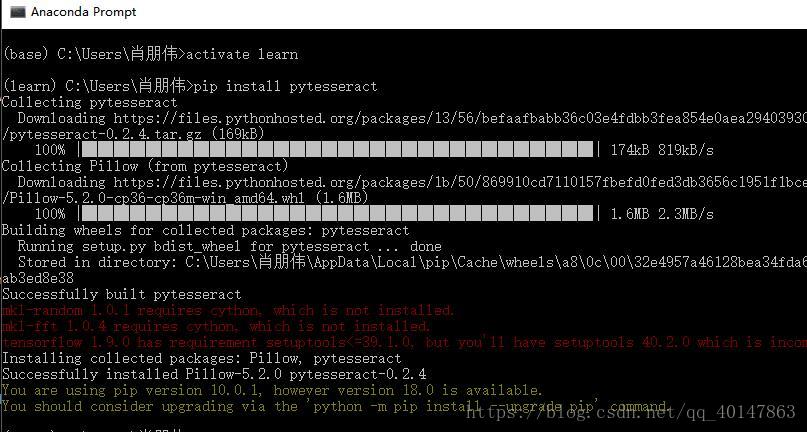
python使用tesseract的工具 pytesseract 的安装
- 如果使用的是 Anaconda 环境:
- 进入当前环境:(我的环境名为learn,如果只有一个base环境,忽略此步)
activate learn
- 安装 pytesseract
pip install pytesseract
- 操作截图
- 首先说一下,conda 是没有这个包的,也就不能使用 conda install,也不能直接在 Pycharm 里找到,只有使用 pip 安装,然后需要注意的就是,要使用你在 Pycharm 使用的那个环境进行安装
识别验证码案例
- 注意:此代码路径是,在图片和代码在同一目录
- 图片截图:
- 代码 py30pytess.py 文件:

import pytesseract as pt
from PIL import Image
# 生成图片实例
image = Image.open('timg.jpg')
# 调用 pytesseract 识别图片文字
text = pt.image_to_string(image)
print(text)
运行结果
- 这里是错了一个字符,因为需要用很多数据去训练,才能得到更高的准确率
- 如果想看训练的部分,点击:Tesseract-OCR-02-使用 jTessBoxEditor 提高文字识别准确率

更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-29-验证码识别-Tesseract-OCR的更多相关文章
- Python爬虫教程:验证码的爬取和识别详解
今天要给大家介绍的是验证码的爬取和识别,不过只涉及到最简单的图形验证码,也是现在比较常见的一种类型. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
Python爬虫教程-12-爬虫使用cookie(上) 爬虫关于cookie和session,由于http协议无记忆性,比如说登录淘宝网站的浏览记录,下次打开是不能直接记忆下来的,后来就有了cooki ...
- 简单的python爬虫教程:批量爬取图片
python编程语言,可以说是新型语言,也是这两年来发展比较快的一种语言,而且不管是少儿还是成年人都可以学习这个新型编程语言,今天南京小码王python培训机构变为大家分享了一个python爬虫教程. ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块 今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error URLError URLError ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
随机推荐
- Go语言fmt包详解
格式化输出函数 fmt包含有格式化I/O函数,类似于C语言的printf和scanf.格式字符串的规则来源于C,但更简单一些 1.print和println方法 print输出给定的字符串,如果是数值 ...
- Q481 神奇字符串
神奇的字符串 S 只包含 '1' 和 '2',并遵守以下规则: 字符串 S 是神奇的,因为串联字符 '1' 和 '2' 的连续出现次数会生成字符串 S 本身. 字符串 S 的前几个元素如下:S = & ...
- python四则运算2.0
github项目地址: https://github.com/kongkalong/python PSP 预估耗时(分钟) Planning .Estimate 48*60 Development . ...
- 20190430-screen、client、offset、scroll等JS中各种宽度距离
参考文献: JavaScript概念之screen/client/offset/scroll/inner/avail的width/left
- 移动工程后,打开ROM核无配置信息
问题: 从他人处下载的ISE工程,打开dw51的ROM IP核,无配置信息,为block memory generator的初始配置,并显示无法找到coe文件 原因:ROM配置过程中的部分内容丢失导致 ...
- C# 实现IP视频监控(摄像头)画面推送(简单的不能再简单的DEMO)
最近继续在家休息,在完成上一个Python抓取某音乐网站爬虫后,琢磨着实现一个基于HTTP推送的 IP视频监控,比如外出的时候,在家里 开启一个监控端(摄像头+服务端),可以看到实时画面,如果再加上自 ...
- 改修jquery支持cmd规范的seajs
手动包装jquery1.10.2,firebug说$没有定义 define(function (require, exports, module) {//jquery源码module.exports= ...
- H5页面JS调试
页面调试 常用的调试方法 开发时候的调试基本是在chrome的控制台Emulation完成 现有的一些手机端调试方案: Remote debugging with Opera Dragonfly 需要 ...
- PHP根据ASCII码返回具体的字符
根据ASCII码返回具体的字符,在php中可以使用函数 chr(); 如:大写字母A的 ASCII码是 65, 所以: <?php echo chr(65);//结果是大写字母 A ?> ...
- log4j DailyRollingFileAppender, DatePattern 配置
在DailyRollingFileAppender中可以指定monthly(每月). weekly(每周).daily(每天).half-daily(每半天).hourly(每小时)和minutely ...