Batch Normalization 笔记
原理
输入层可以归一化,那么其他层也应该可以归一化。但是有个重要的问题,为什么要引入beta和gamma。
为什么要引入beta和gamma
- 不总是要标准正态分布,否则会损失表达能力,作者以sigmoid函数为例进行说明。可以看到,标准正态分布(正负三倍标准差)正好落在sigmoid函数的线性部分。其他激活函数(ReLU系列)更有可能需要不同的分布。
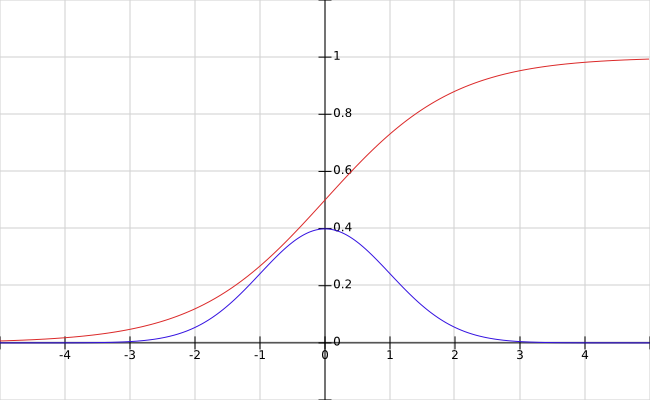
- 恒等映射
如果beta和gamma正好是均值和标准差,那么变换之后得到的是该特征原来的分布。 - 可以不要bias,因为会减均值
测试过程
- 测试时,归一化过程往往针对一个输入,因此均值和方差需要在训练时学习。例如:
# training
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
# testing
output = gamma * (x-running_mean)/sqrt(running_var+epsilon) + beta
参数数量
- 当前层的每个特征有各自的分布,因此BN是针对各个特征的
- 对于CNN来说,n个激活图的层有4n个参数,beta,gamma以及running mean和running variance
BN的效果
- 改善了网络中的梯度流
- 可以使用更大的学习率
- 降低了对权重初始化的要求
- 提供一定程度的正则化
Why BN works?
covariate shift
数据的分布是变化的,已经学习到的映射(权重)在新的数据上需要重新训练。在隐藏层之间,称为internal covariate shift。
- 当实际的映射(ground truth mapping)有shift时(网络没有训练好时)问题更严重
BN的作用
- 使各层的输入数据具有相似的分布(正态分布)
- 减小了internal covariate shift
- 限制了当前层分布的变化,因此减小了对下一层的影响
- 当前层可以改变数据的分布,因此减小了之前层的影响
Batch Normalization 笔记的更多相关文章
- 深度学习中batch normalization
目录 1 Batch Normalization笔记 1.1 引包 1.2 构建模型: 1.3 构建训练函数 1.4 结论 Batch Normalization笔记 我们将会用MNIST数 ...
- 论文笔记:Batch Normalization
在神经网络的训练过程中,总会遇到一个很蛋疼的问题:梯度消失/爆炸.关于这个问题的根源,我在上一篇文章的读书笔记里也稍微提了一下.原因之一在于我们的输入数据(网络中任意层的输入)分布在激活函数收敛的区域 ...
- batch normalization学习理解笔记
batch normalization学习理解笔记 最近在Andrew Ng课程中学到了Batch Normalization相关内容,通过查阅资料和原始paper,基本上弄懂了一些算法的细节部分,现 ...
- 深度学习(二十九)Batch Normalization 学习笔记
Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce 一.背景意义 ...
- Batch normalization:accelerating deep network training by reducing internal covariate shift的笔记
说实话,这篇paper看了很久,,到现在对里面的一些东西还不是很好的理解. 下面是我的理解,当同行看到的话,留言交流交流啊!!!!! 这篇文章的中心点:围绕着如何降低 internal covari ...
- Batch Normalization 学习笔记
原文:http://blog.csdn.net/happynear/article/details/44238541 今年过年之前,MSRA和Google相继在ImagenNet图像识别数据集上报告他 ...
- 神经网络Batch Normalization——学习笔记
训练神经网络的过程,就是在求未知参数(权重).让网络搭建起来,得到理想的结果. 分类-监督学习. 反向传播求权重:每一层在算偏导数.局部梯度,链式法则. 激活函数: sigmoid仅中间段趋势良好 对 ...
- 从Bayesian角度浅析Batch Normalization
前置阅读:http://blog.csdn.net/happynear/article/details/44238541——Batch Norm阅读笔记与实现 前置阅读:http://www.zhih ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
随机推荐
- VR内容是如何制作的!
VR全景视频作为一种新型的视频方式,其震撼效果是毋庸置疑的.目前市场上的VR全景视频也不在少数,越来越多的人能够欣赏到精彩的内容. 首先呢, VR内容场景的呈现分为两种情况: 1.实景拍摄 2.3D建 ...
- Python机器学习库sklearn的安装
Python机器学习库sklearn的安装 scikit-learn是Python的一个开源机器学习模块,它建立在NumPy,SciPy和matplotlib模块之上能够为用户提供各种机器学习算法接口 ...
- 【c++】常识易混提示
1. struct 和 class 唯一的区别:默认的成员保护级别和默认的派生保护级别不同(前者为public,后者为private). 2. int *p = new int[23]; de ...
- java.net.SocketException四大异常解决方案---转
java.net.SocketException如何才能更好的使用呢?这个就需要我们先要了解有关这个语言的相关问题.希望大家有所帮助.那么我们就来看看有关java.net.SocketExceptio ...
- 不能修改列 "。。",因为它是计算列,或者是 UNION 运算符的结果。
修改Mapping this.Property(t => t...).HasDatabaseGeneratedOption(System.ComponentModel.DataAnnotatio ...
- K2.ActivityInstanceDestination.User is NULL
his one caught me by surprise! I needed to build up a CSV list of email addresses for all previous t ...
- bash的常用功能呢
一.tab键可以自动补齐命令 二.命令历史 1.history 查看之前敲过的所有命令 2.!历史命令编号 调用历史的某一个命令 三.命令别名 1.设置别名 alias 别名=‘命令’ 2.移除 ...
- Spring相关概念的理解理解
spring 框架的优点是一个轻量级比较简单易学的框架,实际使用中的有点优点有哪些呢!1.降低了组件之间的耦合性 ,实现了软件各层之间的解耦 2.可以使用容易提供的众多服务,如事务管理,消息服务等 3 ...
- Linux 安装 EPEL YUM源
原文:https://blog.csdn.net/harbor1981/article/details/51135623 我们用yum安装软件时,经常发现我们的yum源里面没有该软件,需要自己去wge ...
- Eclipse添加JBOSS支持
Eclipse安装Drools插件(Drools and jBPM tools)时无法安装JBoss Runtime Drools Detector,需要给eclipse安装JBOSS的基础环境,具体 ...