Tensorflow的采样方法:candidate sampling(zhuan)
zhuanzi:https://blog.csdn.net/u010223750/article/details/69948463
采样介绍
假如我们有一个多分类任务或者多标签分类任务,给定训练集(xi,Ti)(xi,Ti),其中xixi表示上下文,TiTi表示目标类别(可能有多个).可以用word2vec中的negtive sampling方法来举例,使用cbow方法,也就是使用上下文xixi来预测中心词(单个targetTiTi),或者使用skip-gram方法,也就是使用中心词xixi来预测上下文(多个target(TiTi)).
我们想学习到一个通用函数F(x,y)F(x,y)来表征上下文xx和目标类yy的关系,如Word2vec里面,使用上下文预测下个单词的概率。
完整的训练方法,如使用softmax或者Logistic回归需要对每个训练数据计算所有类y∈Ly∈L的概率F(x,y)F(x,y),当|L||L|非常大的时候,训练将非常耗时。
“candidate sampling”训练方法包括为每一个训练数据(xi,Ti)(xi,Ti)构造一个训练任务,使得我们只需要使用一个较小的候选集合Ci∈LCi∈L,就能评估F(x,y)F(x,y),典型的,candidate set CiCi包含目标类别TiTi和一些随机采样的类别Si∈LSi∈L:
,SiSi的选择可能依赖xixi和TiTi,也可能不依赖。
F(x,y)F(x,y)可以使用神经网络计算来表征(也就是TensorFlow里面常用的logits)
TensorFlow中各种采样
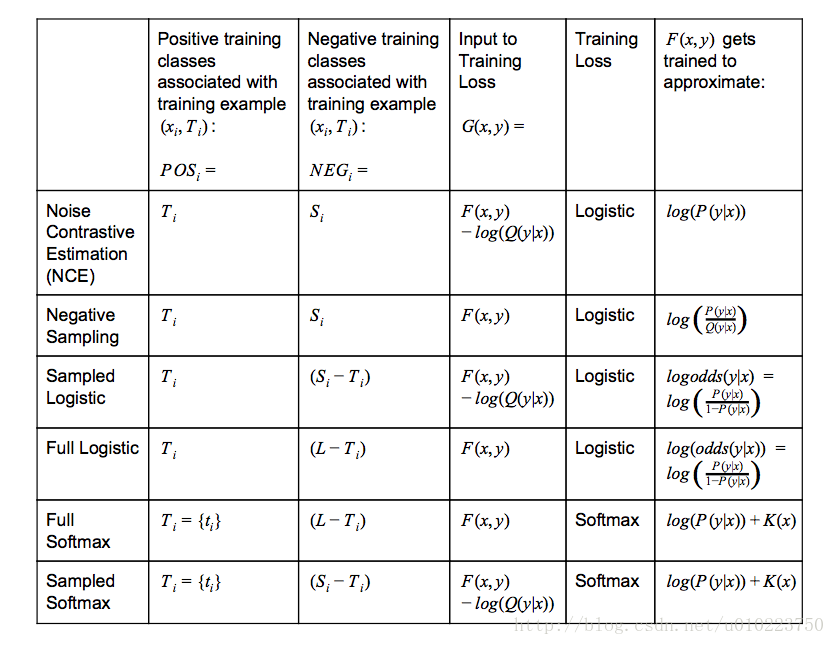
其中:
- Q(y|x)Q(y|x)表示的是给定contextxixi采样到yy的概率
- K(x)K(x)表示任意不以来候选集的函数
- logistic−training−loss=∑i(∑y∈POSilog(1+exp(−G(xi,y)))+∑y∈NEGilog(1+exp(G(xi,y))))(1)logistic−training−loss=∑i(∑y∈POSilog(1+exp(−G(xi,y)))+∑y∈NEGilog(1+exp(G(xi,y))))(1)
- softmax−training−loss=∑i(−log(exp(G(xi,ti))∑y∈POSi∪NEGiexp(G(xi,y))))softmax−training−loss=∑i(−log(exp(G(xi,ti))∑y∈POSi∪NEGiexp(G(xi,y))))
softmax vs. logistic
在使用tensoflow的时候,我们有时候会纠结选择什么样的损失函数比较好,softmax和logistic在表达形式上是有点区别的,但是也不是很大,而且对于普通的softmax_cross_entropy_with_logits和sigmoid_cross_entropy_with_logits也都能够进行多分类任务,那么他们之间的区别是什么的?
就我个人所想到的,使用sigmoid_cross_entropy_with_logits和softmax_cross_entropy_with_logits的最大的区别是类别的排他性,在分类任务中,使用softmax_cross_entropy_with_logits我们一般是选择单个标签的分类,因为其具有排他性,说白了,softmax_cross_entropy_with_logits需要的是一个类别概率分布,其分布应该服从多项分布(也就是多项logistic regression),我们训练是让结果尽量靠近这种概率分布,不是说softmax_cross_entropy_with_logits不能进行多分,事实上,softmax_cross_entropy_with_logits是支持多个类别的,其参数labels也没有限制只使用一个类别,当使用softmax_cross_entropy_with_logits进行多分类时候,以二类为例,我们可以设置真实类别的对应labels上的位置是0.5,0.5,训练使得这个文本尽量倾向这种分布,在test阶段,可以选择两个计算概率最大的类作为类别标签,从这种角度说,使用softmax_cross_entropy_with_logits进行多分,实际上类似于计算文本的主题分布。
但是对于sigmoid_cross_entropy_with_logits,公式(1)(1)可以看出,sigmoid_cross_entropy_with_logits其实是训练出了多个分类器,对于有nn个标签 的分类问题,其实质是分成了nn个二分类问题,这点和softmax_cross_entropy_with_logits有着本质的区别。
tensorflow提供了下面两种candidate sample方法
- tf.nn.nce_loss
- tf.nn.sampled_softmax_loss
对比与之前讨论的,从最上面的图中的training loss采用的方法可以知道, tf.nn.nce_loss使用的是logistic 而tf.nn.sampled_softmax_loss采用的是softmax loss,其实这两者的区别也主要在这儿,采用logistic loss的本质上还是训练nn个分类器,而使用softmax loss的其实只是训练了一个主题分类器,tf.nn.nce_loss主要思路也是判断给定context CiCi和训练数据xixi,判断每一个yiyi是不是target label,而 tf.nn.sampled_softmax_loss则是使得在target label上的分布概率最大化。
个人看法,对于多标签多类别的分类任务使用Logistic比较好,对于多标签单类别的分类任务使用softmax比较好,采样中,采用tf.nn.sampled_softmax_loss训练cbow模型比较好,而 tf.nn.nce_loss训练skip-gram比较好。
---------------------
本文来自 luchi007 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/u010223750/article/details/69948463?utm_source=copy
Tensorflow的采样方法:candidate sampling(zhuan)的更多相关文章
- On Using Very Large Target Vocabulary for Neural Machine Translation Candidate Sampling Sampled Softmax
[softmax分类器的加速器] https://www.tensorflow.org/api_docs/python/tf/nn/sampled_softmax_loss This is a fas ...
- 随机模拟的基本思想和常用采样方法(sampling)
转自:http://blog.csdn.net/xianlingmao/article/details/7768833 引入 我们会遇到很多问题无法用分析的方法来求得精确解,例如由于式子特别,真的解不 ...
- NCE损失(Noise-Constrastive Estimation Loss)
1.算法概述 假设X是从真实的数据(或语料库)中抽取的样本,其服从一个相对可参考的概率密度函数P(d),噪音样本Y服从概率密度函数为P(n),噪音对比估计(NCE)就是通过学习一个分类器把这两类样本区 ...
- TensorFlow 常用函数汇总
本文介绍了tensorflow的常用函数,源自网上整理. TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU 或 GPU.一般你不需要显式指定使用 CPU ...
- TensorFlow 常用函数与方法
摘要:本文主要对tf的一些常用概念与方法进行描述. tf函数 TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU 或 GPU.一般你不需要显式指定使用 CP ...
- Tensorflow一些常用基本概念与函数
1.tensorflow的基本运作 为了快速的熟悉TensorFlow编程,下面从一段简单的代码开始: import tensorflow as tf #定义‘符号’变量,也称为占位符 a = tf. ...
- Tensorflow一些常用基本概念与函数(1)
为了快速的熟悉TensorFlow编程,下面从一段简单的代码开始: import tensorflow as tf #定义‘符号’变量,也称为占位符 a = tf.placeholder(" ...
- 『TensorFlow』函数查询列表_神经网络相关
tf.Graph 操作 描述 class tf.Graph tensorflow中的计算以图数据流的方式表示一个图包含一系列表示计算单元的操作对象以及在图中流动的数据单元以tensor对象表现 tf. ...
- TensorFlow学习之四
Tensorflow一些常用基本概念与函数(1) 摘要:本文主要对tf的一些常用概念与方法进行描述. 1.tensorflow的基本运作 为了快速的熟悉TensorFlow编程,下面从一段简单的代码开 ...
随机推荐
- 无网络环境用pip安装python类包
1.现在有网络的电脑安装相应的包 pip install django 2.安装完成后 打包 1)新建一个文件夹(package),用来存放包: 2)执行 pip list #查看安装的包 pip f ...
- java基础(7)--方法
方法 Math.sqrt() 取平方 Math.pow(2,3) 2的3次方 方法(Method),就是数学函数(Function). 业务方面: 是功能,是动作,一般采用动词命名. 数据层面:是利用 ...
- java 在Excel中插入图片 POI实现
一.POI简介 Jakarta POI 是apache的子项目,目标是处理ole2对象.它提供了一组操纵Windows文档的Java API 目前比较成熟的是HSSF接口,处理MS Excel(97- ...
- 【spark】文件读写和JSON数据解析
1.读文件 通过 sc.textFile(“file://") 方法来读取文件到rdd中. val lines = sc.textFile("file://")//文件地 ...
- 漂亮的Html5网站
http://www.mrdoob.com/projects/chromeexperiments/ball-pool/
- dateTimePicker编辑状态下,取值不正确的问题
当对dateTimePicker进行编辑,回车,调用函数处理dateTimePicker的value值时,其取值结果是你编辑之前的值,而不是你编辑后的值,虽然dateTimePicker.text的值 ...
- L134
这种成功和后来的研究(表明记忆本身并不是先天决定的)使爱立信总结到,记忆的行为与其说是一种习得的行为不如说是一种先天的行为. 这点我们不清楚-构思物体和找出数字模型的能力,回答问题(最好的诗人和哲学家 ...
- 如何在eclipse中安装ADT
打开Eclipse,点击 Help -> Install New Software: 点击Add: 然后点击Archive,添加对应的上面的ADT-21.0.1.zip: OK后,再写上一个名字 ...
- S2SH框架中的无刷新验证码功能实现
暑假期间在实验室做使用S2SH框架的项目,其中登录和注册需要验证码,实现了一个没有实现刷新验证码功能的简单版本,代码如下: 1 package com.sem.action; 2 3 import j ...
- 专业工具软件AutoCAD复习资料
专业工具软件AutoCAD复习资料 下载地址:http://download.csdn.net/detail/zhangrelay/9849503 这里给出了一些dwg格式的CAD资料,用于课后学习和 ...