7、 正则化(Regularization)
7.1 过拟合的问题
到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fitting)的问题,可能会导致它们效果很差。
在这段视频中,我将为你解释什么是过度拟合问题,并且在此之后接下来的几个视频中,我们将谈论一种称为正则化(regularization)的技术,它可以改善或者减少过度拟合问题。
如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集(代价函数可能几乎为0),但是可能会不能推广到新的数据。
下图是一个回归问题的例子:
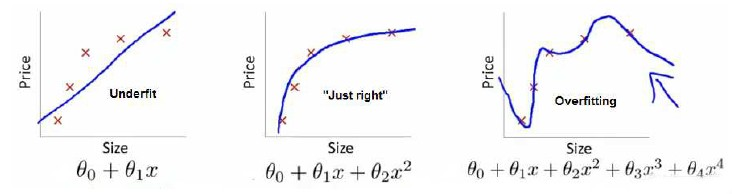
第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
分类问题中也存在这样的问题:
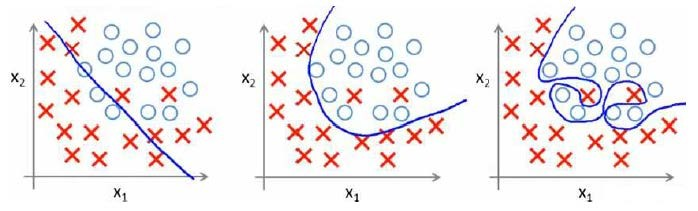
就以多项式理解,x$的次数越高,拟合的越好,但相应的预测的能力就可能变差。
问题是,如果我们发现了过拟合问题,应该如何处理?
丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)
正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
7.2 代价函数
上面的回归问题中如果我们的模型是:
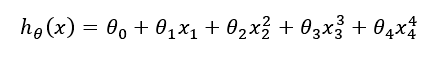
我们可以从之前的事例中看出,正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于0的话,我们就能很好的拟合了。
所以我们要做的就是在一定程度上减小这些参数θ 的值,这就是正则化的基本方法。我们决定要减少θ3和θ4的大小,我们要做的便是修改代价函数,在其中θ3和θ4设置一点惩罚。这样做的话,我们在尝试最小化代价时也需要将这个惩罚纳入考虑中,并最终导致选择较小一些的θ3和θ4。 修改后的代价函数如下:
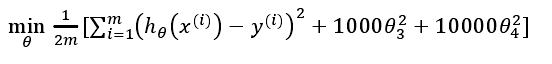
通过这样的代价函数选择出的θ3和θ4 对预测结果的影响就比之前要小许多。假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度。这样的结果是得到了一个较为简单的能防止过拟合问题的假设:
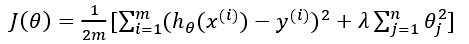
其中
7、 正则化(Regularization)的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- zzL1和L2正则化regularization
最优化方法:L1和L2正则化regularization http://blog.csdn.net/pipisorry/article/details/52108040 机器学习和深度学习常用的规则化 ...
- 斯坦福第七课:正则化(Regularization)
7.1 过拟合的问题 7.2 代价函数 7.3 正则化线性回归 7.4 正则化的逻辑回归模型 7.1 过拟合的问题 如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集( ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [笔记]机器学习(Machine Learning) - 03.正则化(Regularization)
欠拟合(Underfitting)与过拟合(Overfitting) 上面两张图分别是回归问题和分类问题的欠拟合和过度拟合的例子.可以看到,如果使用直线(两组图的第一张)来拟合训,并不能很好地适应我们 ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [C3] 正则化(Regularization)
正则化(Regularization - Solving the Problem of Overfitting) 欠拟合(高偏差) VS 过度拟合(高方差) Underfitting, or high ...
- 1.4 正则化 regularization
如果你怀疑神经网络过度拟合的数据,即存在高方差的问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,但是你可能无法时时准备足够多的训练数据,或者获取更多数据的代价很高.但正则 ...
- 机器学习(五)--------正则化(Regularization)
过拟合(over-fitting) 欠拟合 正好 过拟合 怎么解决 1.丢弃一些不能帮助我们正确预测的特征.可以是手工选择保留哪些特征,或者使用一 些模型选择的算法来帮忙(例如 PCA) 2.正则化. ...
随机推荐
- SpringBoot框架(1)--入门篇
什么是SpringBoot? Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程. 特征 创建独立的Spring应用程序 直接嵌 ...
- Java语言Lang包下常用的工具类介绍_java - JAVA
文章来源:嗨学网 敏而好学论坛www.piaodoo.com 欢迎大家相互学习 无论你在开发哪中 Java 应用程序,都免不了要写很多工具类/工具函数.你可知道,有很多现成的工具类可用,并且代码质量都 ...
- LeetCode--142--环形链表II(python)
给定一个链表,返回链表开始入环的第一个节点. 如果链表无环,则返回 null. 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始). 如果 pos 是 - ...
- SQL把a表字段数据存到b表字段 update,,insert
update SYS_Navigation set SYS_Navigation.PARENT_XH = SYS_Power_menu.parent_id,SYS_Navigation.web_tit ...
- Ubuntu redis 实战 持久化策略 主从复制 以及 故障恢复
推荐文章 redis数据结构学习 redis持久化 redis主从复制 redis哨兵
- 【CF10D】LCIS(LCIS)
题意:求两个序列的LCIS n,m<=300,a[i]<=1e9 题意:O(n^2) O(n^3)的话设dp[i,j]为A终点为a[1..i]且B终点为b[j]的最大长度,分a[i]==b ...
- 【CF1252K】Addition Robot(线段树,矩阵乘法)
题意: 思路:因为线段树上每一段的矩阵之积只有两种,预处理一下,翻转的时候下传tag然后把另一种可能性换上来就好 #include<bits/stdc++.h> using namespa ...
- MapServer教程3
Compiling on Unix Compiling on Win32 PHP MapScript Installation .NET MapScript Compilation IIS Setup ...
- 手写CSS+js实现radio单选按钮
有的时候我们需要用长得漂亮一点的单选按钮,那么,就要抛弃原有的自己来写,下面就是我实现的 <div class="radio"><span class=" ...
- Redis分布式锁服务
阅读目录: 概述 分布式锁 多实例分布式锁 总结 概述 在多线程环境下,通常会使用锁来保证有且只有一个线程来操作共享资源.比如: object obj = new object(); lock (ob ...