python2.7 爬虫_爬取小说盗墓笔记章节及URL并导入MySQL数据库_20161201
1、爬取页面 http://www.quanshu.net/book/9/9055/
2、用到模块urllib(网页下载),re正则匹配取得title及titleurl,urlparse(拼接完整url),MySQLdb(导入MySQL) 数据库
3、for 循环遍历列表 取得盗墓笔记章节title 和 titleurl
4、try except 异常处理
5、python 代码
#-*-coding: utf-8 -*-
import urllib
import re
import urlparse
import MySQLdb
rooturl='http://www.quanshu.net/book/9/9055/'
#getlist返回包含title 和titleurl的列表
def getlist(url):
html=urllib.urlopen(url).read()
html=html.decode('gb2312').encode('utf-8')
reg=r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>'
return re.findall(reg,html)
try:
conn = MySQLdb.connect(host='localhost', user='root', passwd='Admin@', db='local_db', port=3306, charset='utf8')
with conn:
cursor = conn.cursor()
#如果存在daomubiji数据表先删除
drop_table_sql='DROP TABLE IF EXISTS daomubiji'
cursor.execute(drop_table_sql)
conn.commit()
#如果存在daomubiji数据表 先删除后接着创建daomubiji表
create_table_sql = '''
CREATE TABLE daomubiji (
ID INT(11),
title VARCHAR(255),
titleurl VARCHAR(255)
)ENGINE=INNODB DEFAULT CHARSET=utf8
'''
cursor.execute(create_table_sql)
conn.commit()
#下面调用getlist()函数获取rooturl下所有章节的titleurl 和title 组成的列表
urllist = getlist(rooturl)
#href属性取得的url不完整 仅取出了完整url的右半段 因此下面for循环变量名起名righturl
ID=0
#对列表进行遍历 取 titleurl 和title
for righturl in urllist:
title = righturl[1]
newurl = righturl[0]
#urlparse 模块的urlparse.urljoin方法将righturl 按照rooturl格式拼接成完整url
titleurl = urlparse.urljoin(rooturl, newurl)
ID+=1
print ID,title, titleurl
cursor.execute("INSERT INTO daomubiji values(%s,%s,%s)", (ID,title, titleurl))
conn.commit()
print "输入了"+ str(ID) +"条数据"
except MySQLdb.Error:
print "连接失败!"
代码执行情况:
6、MySQL数据库查询是否导入成功
SELECT * FROM daomubiji
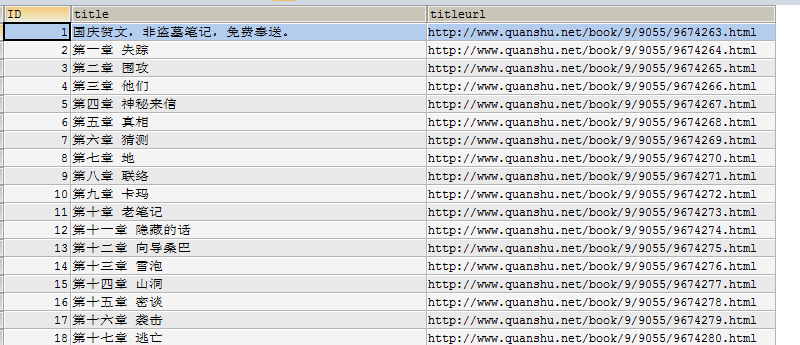
7、执行成功
python2.7 爬虫_爬取小说盗墓笔记章节及URL并导入MySQL数据库_20161201的更多相关文章
- python爬虫:爬取易迅网价格信息,并写入Mysql数据库
本程序涉及以下方面知识: 1.python链接mysql数据库:http://www.cnblogs.com/miranda-tang/p/5523431.html 2.爬取中文网站以及各种乱码处 ...
- Python实战项目网络爬虫 之 爬取小说吧小说正文
本次实战项目适合,有一定Python语法知识的小白学员.本人也是根据一些网上的资料,自己摸索编写的内容.有不明白的童鞋,欢迎提问. 目的:爬取百度小说吧中的原创小说<猎奇师>部分小说内容 ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- xpath爬虫实战-爬取小说斗罗大陆第四部
爬取思路 用到的第三方库文件 lxml,requests,fake_agent 用fake_agent里的UserAgent修饰爬虫 用requests进行基本的请求 用lxml进行html的分析 用 ...
- python爬虫26 | 把数据爬取下来之后就存储到你的MySQL数据库。
小帅b说过 在这几篇中会着重说说将爬取下来的数据进行存储 上次我们说了一种 csv 的存储方式 这次主要来说说怎么将爬取下来的数据保存到 MySQL 数据库 接下来就是 学习python的正确姿势 真 ...
- scrapy爬取小说盗墓笔记
# -*- coding: utf-8 -*- import scrapy from daomu.items import DaomuItem class DaomuspiderSpider(scra ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)
转载出处:药少敏 ,感谢原作者清晰的讲解思路! 下述代码是我通过自己互联网搜索和拜读完此篇文章之后写出的具有同样效果的爬虫代码: from bs4 import BeautifulSoup imp ...
随机推荐
- CI整合Smarty
1.到相应的站点下载smarty模板: 2.将源代码中的libs目录复制到项目的libraries目录下,改名为smarty3.0 3.在项目目录的libraries文件夹内新建文件ci_smarty ...
- block捕获自动变量和对象
一.捕获自动变量值 首先看一个经典block面试题: int val = 10; void (^blk)(void) = ^{printf("val=%d\n",val);}; v ...
- Qt资源下载、安装、配置
(一)资源下载: 硕士毕业论文要做一个仿真平台,在linux环境下利用Qt开发. 自己有一定的c/c++基础,Qt是零基础接触.所以,经过一番查找,发现youtube一个外国友人Bryan从零开始教Q ...
- request.getParameterMap()使用方法
我习惯于加密完 重定向 : Map<String,String[]> getMap = request.getParameterMap(); String[] a = getMap.get ...
- poj2369 Permutations ——置换群
link:http://poj.org/problem?id=2369 置换群,最简单的那种. 找所有数字循环节的最小公倍数. /* ID: zypz4571 LANG: C++ TASK: perm ...
- JS特殊函数(Function()构造函数、函数直接量)区别介绍
函数定义 函数是由这样的方式进行声明的:关键字 function.函数名.一组参数,以及置于括号中的待执行代码. 函数的构造语法有这三种: 1.function functionName(arg0, ...
- Stencil Buffer
刚在草稿箱里发现了这篇充满特色的好日志.发表之. ------------------吃货的分割线---------------------------------------- Stencil Bu ...
- bzoj4130: [PA2011]Kangaroos
Description 定义两个区间互相匹配表示这两个区间有交集. 给出长度为N的区间序列A,M次询问,每次询问序列A中最长的连续子序列,使得子序列中的每个区间都与[L,R]互相匹配 N<=50 ...
- LVS-DR工作原理图文详解
为了阐述方便,我根据官方原理图另外制作了一幅图,如下图所示:VS/DR的体系结构: 我将结合这幅原理图及具体的实例来讲解一下LVS-DR的原理,包括数据包.数据帧的走向和转换过程. 官方的原理说明:D ...
- ASP.NET MVC IOC 之AutoFac攻略
一.为什么使用AutoFac? 之前介绍了Unity和Ninject两个IOC容器,但是发现园子里用AutoFac的貌似更为普遍,于是捯饬了两天,发现这个东东确实是个高大上的IOC容器~ Autofa ...