python2.7 爬虫_爬取小说盗墓笔记章节及URL并导入MySQL数据库_20161201
1、爬取页面 http://www.quanshu.net/book/9/9055/
2、用到模块urllib(网页下载),re正则匹配取得title及titleurl,urlparse(拼接完整url),MySQLdb(导入MySQL) 数据库
3、for 循环遍历列表 取得盗墓笔记章节title 和 titleurl
4、try except 异常处理
5、python 代码
#-*-coding: utf-8 -*-
import urllib
import re
import urlparse
import MySQLdb
rooturl='http://www.quanshu.net/book/9/9055/'
#getlist返回包含title 和titleurl的列表
def getlist(url):
html=urllib.urlopen(url).read()
html=html.decode('gb2312').encode('utf-8')
reg=r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>'
return re.findall(reg,html)
try:
conn = MySQLdb.connect(host='localhost', user='root', passwd='Admin@', db='local_db', port=3306, charset='utf8')
with conn:
cursor = conn.cursor()
#如果存在daomubiji数据表先删除
drop_table_sql='DROP TABLE IF EXISTS daomubiji'
cursor.execute(drop_table_sql)
conn.commit()
#如果存在daomubiji数据表 先删除后接着创建daomubiji表
create_table_sql = '''
CREATE TABLE daomubiji (
ID INT(11),
title VARCHAR(255),
titleurl VARCHAR(255)
)ENGINE=INNODB DEFAULT CHARSET=utf8
'''
cursor.execute(create_table_sql)
conn.commit()
#下面调用getlist()函数获取rooturl下所有章节的titleurl 和title 组成的列表
urllist = getlist(rooturl)
#href属性取得的url不完整 仅取出了完整url的右半段 因此下面for循环变量名起名righturl
ID=0
#对列表进行遍历 取 titleurl 和title
for righturl in urllist:
title = righturl[1]
newurl = righturl[0]
#urlparse 模块的urlparse.urljoin方法将righturl 按照rooturl格式拼接成完整url
titleurl = urlparse.urljoin(rooturl, newurl)
ID+=1
print ID,title, titleurl
cursor.execute("INSERT INTO daomubiji values(%s,%s,%s)", (ID,title, titleurl))
conn.commit()
print "输入了"+ str(ID) +"条数据"
except MySQLdb.Error:
print "连接失败!"
代码执行情况:
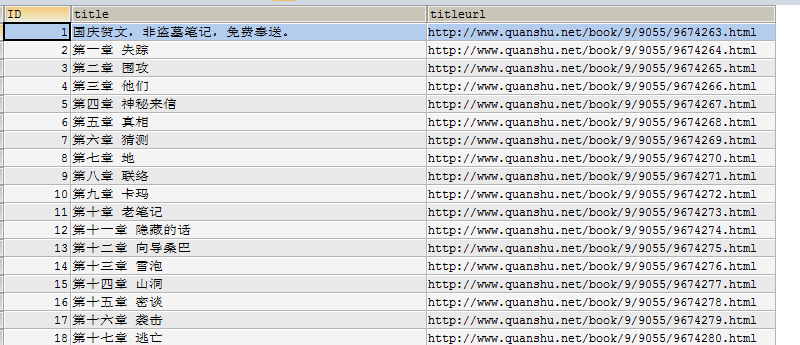
6、MySQL数据库查询是否导入成功
SELECT * FROM daomubiji
7、执行成功
python2.7 爬虫_爬取小说盗墓笔记章节及URL并导入MySQL数据库_20161201的更多相关文章
- python爬虫:爬取易迅网价格信息,并写入Mysql数据库
本程序涉及以下方面知识: 1.python链接mysql数据库:http://www.cnblogs.com/miranda-tang/p/5523431.html 2.爬取中文网站以及各种乱码处 ...
- Python实战项目网络爬虫 之 爬取小说吧小说正文
本次实战项目适合,有一定Python语法知识的小白学员.本人也是根据一些网上的资料,自己摸索编写的内容.有不明白的童鞋,欢迎提问. 目的:爬取百度小说吧中的原创小说<猎奇师>部分小说内容 ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- xpath爬虫实战-爬取小说斗罗大陆第四部
爬取思路 用到的第三方库文件 lxml,requests,fake_agent 用fake_agent里的UserAgent修饰爬虫 用requests进行基本的请求 用lxml进行html的分析 用 ...
- python爬虫26 | 把数据爬取下来之后就存储到你的MySQL数据库。
小帅b说过 在这几篇中会着重说说将爬取下来的数据进行存储 上次我们说了一种 csv 的存储方式 这次主要来说说怎么将爬取下来的数据保存到 MySQL 数据库 接下来就是 学习python的正确姿势 真 ...
- scrapy爬取小说盗墓笔记
# -*- coding: utf-8 -*- import scrapy from daomu.items import DaomuItem class DaomuspiderSpider(scra ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)
转载出处:药少敏 ,感谢原作者清晰的讲解思路! 下述代码是我通过自己互联网搜索和拜读完此篇文章之后写出的具有同样效果的爬虫代码: from bs4 import BeautifulSoup imp ...
随机推荐
- Erlang 104 OTP
笔记系列 Erlang环境和顺序编程Erlang并发编程Erlang分布式编程YawsErlang/OTP 日期 变更说明 2014-12-21 A Outline, 1 A ...
- 【转载】 postman使用教程
一 接口请求流程 二 postman使用 从流程图中我们可以看出,一个接口请求需要设置:请求URL,请求方法,请求头,请求参数.同样的,在postman中,我们也只需要设置这四项即可完成一 ...
- Altium Designer 画"差分线"
Altium Designer 画"差分线" 如何在 Altium Designer 中快速进行差分对走线1:在原理图中让一对网络前缀相同,后缀分别为_N 和_P,并且加上差分队对 ...
- 快速开发CSS的利器-LESS
快速开发CSS的利器-LESS? 天下功夫,唯快不破!效率,在项目开发上,这是极其重要的.要做到快.精.准,在人任何时候都不是一件轻松容易的事.但是如果借助一些相应的工具,那就另当别论了!那么要想快速 ...
- Streaming replication slots in PostgreSQL 9.4
Streaming replication slots are a pending feature in PostgreSQL 9.4, as part of the logical changese ...
- python百分比数比较大小
python是无法识别百分比的,估计你的百分比是string,所以需要转成int # !/usr/bin/python3.4 # -*- coding: utf-8 -*- # 百分数转为int de ...
- Django中csrf错误
CSRF(Cross-site request forgery)跨站请求伪造,也被称为“one click attack”或者session riding,通常缩写为CSRF或者XSRF,是一种对网站 ...
- 使用-MM生成include指令和依赖生成(make include directive and dependency generation with -MM)
I want a build rule to be triggered by an include directive if the target of the include is out of d ...
- 随机数生成器console
#include <stdio.h> #include <stdlib.h> #include <time.h> int main() { ]; ]; int i; ...
- svn 提交失败
刚刚使用SVN 提交代码时提示失败. svn: Commit failed (details follow):svn: Can't open file '/home/svn/project/db/tx ...