deep learning loss总结
在深度学习中会遇到各种各样的任务,我们期望通过优化最终的loss使网络模型达到期望的效果,因此loss的选择是十分重要的。
cross entropy loss
cross entropy loss和log loss,logistic loss是同一种loss。常用于分类问题,一般是配合softmax使用的,通过softmax操作得到每个类别的概率值,然后计算loss。
softmax函数为:
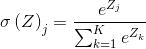 ,
,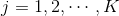 ,
,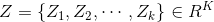
除了e,还可以使用另一个底数b,b>0,选择一个较大的b值,将创建一个概率分布,该分布更集中于输入值最大的位置。 或
或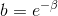 ,因此,softmax函数又可以写作
,因此,softmax函数又可以写作
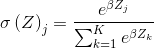 或
或 ,
,
softmax函数的输出是一个概率分布,概率和为1。
cross entropy loss为:

cross entropy loss用来度量模型预测分布和真实分布之间的距离,是平方误差(MSE)的一种广泛应用的替代方法。一般用于当输出特征为概率分布时,输出特征的每个值代表估计为对应类别的概率。
hingle loss
hingle loss是机器学习模型中用于训练分类器的loss,用于“最大间隔”分类。对于二分类,ground truth t= 1,预测结果为y,则hingle loss为
1,预测结果为y,则hingle loss为
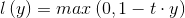
注意y是分类器决策函数的原始输出,而不是经过处理德奥的预测类别。
Mean Squre Error (MSE/L2 loss)
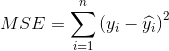 ,
,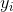 表示ground truth,
表示ground truth, 表示预测结果。
表示预测结果。
Mean Absolute Error (MAE/ L1 loss)
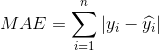 ,表示ground truth,表示预测结果。
,表示ground truth,表示预测结果。
L1 loss和L2 loss的区别:
L2 loss对异常值比较敏感,L1 loss比起L2 loss不易受异常值的影响,更加鲁棒,但在0处不可导。L2 loss有稳定的唯一的解决方案,而L1 loss的解决方案则不一定唯一。
L2 loss优化能力较L1 loss更强一些。在训练神经网络时,L1 loss更新的梯度始终相同,也就是说,即使对于很小的损失值,梯度也很大。这样不利于模型的学习。为了解决这个缺陷,我们可以使用变化的学习率,在损失接近最小值时降低学习率。而L2 loss在这种情况下的表现就很好,即便使用固定的学习率也可以有效收敛。L2 loss的梯度随损失增大而增大,而损失趋于0时则会减小。这使得在训练结束时,使用L2 loss的模型的结果会更精确。
如果异常值代表在商业中很重要的异常情况,并且需要被检测出来,则应选用L2 loss。相反,如果只把异常值当作受损数据,则应选用L1 loss。
Huber loss (smooth L1 loss)
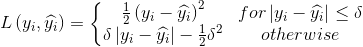 ,
,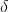 是一个可调参数。
是一个可调参数。
Huber loss相对于L2 loss,对异常值不敏感,而且在0处可导。Huber loss可以看作是L1 loss和L2 loss的结合体,在误差较大时,Huber loss等效于L1 loss,在误差较小时,Huber loss等效于L2 loss。
Log-cos loss
log-cos是另一种应用于回归问题中的,且比L2更平滑的损失函数。它的计算方式是预测误差的双曲余弦的对数。
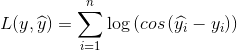
优点:对于较小的x,log(cos(x))近似等于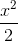 ,对于较大的x,近似等于abs(x)-log2。这意味着log-cos基本类似于均方误差,但不易受到异常点的影响。它具有Huber loss的所有优点,但不同于Huber loss的是,log-cos二阶处处可微。
,对于较大的x,近似等于abs(x)-log2。这意味着log-cos基本类似于均方误差,但不易受到异常点的影响。它具有Huber loss的所有优点,但不同于Huber loss的是,log-cos二阶处处可微。
为什么需要二阶导数?许多机器学习模型如XGBoost,即使采用牛顿法来寻找最优点。而牛顿法就需要求解二阶导数(Hessian)。因此对于诸如XGBoost这类机器学习框架,损失函数的二阶可微是很有必要的。
deep learning loss总结的更多相关文章
- Deep learning:五十一(CNN的反向求导及练习)
前言: CNN作为DL中最成功的模型之一,有必要对其更进一步研究它.虽然在前面的博文Stacked CNN简单介绍中有大概介绍过CNN的使用,不过那是有个前提的:CNN中的参数必须已提前学习好.而本文 ...
- #Deep Learning回顾#之2006年的Science Paper
大家都清楚神经网络在上个世纪七八十年代是着实火过一回的,尤其是后向传播BP算法出来之后,但90年代后被SVM之类抢了风头,再后来大家更熟悉的是SVM.AdaBoost.随机森林.GBDT.LR.FTR ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- Deep learning:四十九(RNN-RBM简单理解)
前言: 本文主要是bengio的deep learning tutorial教程主页中最后一个sample:rnn-rbm in polyphonic music. 即用RNN-RBM来model复调 ...
- Deep Learning 9_深度学习UFLDL教程:linear decoder_exercise(斯坦福大学深度学习教程)
前言 实验内容:Exercise:Learning color features with Sparse Autoencoders.即:利用线性解码器,从100000张8*8的RGB图像块中提取颜色特 ...
- Deep Learning 5_深度学习UFLDL教程:PCA and Whitening_Exercise(斯坦福大学深度学习教程)
前言 本文是基于Exercise:PCA and Whitening的练习. 理论知识见:UFLDL教程. 实验内容:从10张512*512自然图像中随机选取10000个12*12的图像块(patch ...
- (转)分布式深度学习系统构建 简介 Distributed Deep Learning
HOME ABOUT CONTACT SUBSCRIBE VIA RSS DEEP LEARNING FOR ENTERPRISE Distributed Deep Learning, Part ...
- (转)Deep Learning Research Review Week 1: Generative Adversarial Nets
Adit Deshpande CS Undergrad at UCLA ('19) Blog About Resume Deep Learning Research Review Week 1: Ge ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
随机推荐
- --provider=docker时出现的问题
Vagrantfile类似: Vagrant.configure(") do |config| config.vm.box = "hashicorp/precise64" ...
- Android利用fidller进行网络抓包
http://www.oschina.net/question/221817_129716?fromerr=z7ZX9oZR http://www.trinea.cn/android/android- ...
- Zookeeper入门(一)之概述
今天主要讲这么几个方面? 1.分布式应用: 2.什么是Zookeeper: 3.使用Zookkeeper有什么好处: ZooKeeper是一种分布式协调服务,用于管理大型主机.在分布式环境中协调和管理 ...
- 总结js基础方法
//判断对象上是否有个这个属性 hasProreturn obj != null && hasOwnProperty.call(obj, key); //判断是不是布尔值 isBool ...
- 关于Android
1:Handle与多线程 Handle是什么?官方说明:handle是Android给我们提供用来更新UI的一套机制,也是一套消息处理的机制.可以看出handle主要就是两个功能,一个是更新UI,另一 ...
- css笔记--用户界面样式
1.系统字体,系统颜色.根据关键字设置为系统某方面相同的字体和颜色 2.光标:鼠标移入时光标的不同显示方法,有十字键,手型:cursor:pointer;cursor:hand;要按顺序,cursor ...
- 美团热修复Robust-源码篇
上一篇主要分析了Robust的使用方法,这一篇就来总结一下Robust的源码分析. 我个人倾向于将Robust框架分为两个部分,自动插入代码和动态加载Patch. 一.Robust源码分析 目前我的分 ...
- 用java数组模拟购物商城功能与实现
实体类1(商品): package mall.model; public class goods { private int shoppingID; // 商品编号 private String sh ...
- python执行时遇到 KeyError: b'somevar' 时需要想到的
虽然这个问题很小,但我觉得很有必要单独拿出来强调一下. 这样在遇到类似错误的时候可以很快反应过来,进而节约了时间. 这里我拿 shelve 模块举例(shelve的作用大致就是把python变量存放到 ...
- Node.js 从入门到茫然系列——入门篇
在创建服务的时候,我们一般代码就是: var http = require("http"); var server = http.createServer(function(req ...