hive的实践部分
一.hive的事务
(1)什么是事务
要知道hive的事务,首先要知道什么是transaction(事务)?事务就是一组单元化操作,这些操作要么都执行,要么都不执行,是一个不可分割的工作单位。
事务有四大特性:A、C、I、D (原子性、一致性、隔离性、持久性)
Atomicity: 不可再分割的工作单位,事务中的所有操作要么都发,要么都不发。
Consistency: 事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。这是说数据库事务不能破坏关系数据的完整性以及业务逻辑上的 一致性。
Isolation: 多个事务并发访问,事务之间是隔离的
Durability: 意味着在事务完成以后,该事务锁对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
(2)hive事务的特点与局限性
从hive的0.14版本开始支持低等级的事务
支持事务的增删改查,从hive的2.2版本开始,开始支持merge
不支持事务的begin、commit以及rollback(事务的回滚)
不支持使用update更新分桶列和分区列
想使用事务的话,文件格式必须是ORC
表必须是分桶表
需要压缩工作,需要时间,资源和空间
支持S(共享锁)和X(排它锁)
不允许从一个非ACID连接写入/读取ACID表
(3)hive的事务开启
hive的事务开启有三种方式:a.通过Ambari UI-Hive Config
b.通过hive-xml 的配置文件添加如下内容
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
c.通过命令行,在beeline这种交互式环境下:
set hive.support.concurrency = true;
set hive.enforce.bucketing = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on = true;
set hive.compactor.worker.threads = 1;
(4)hive的merge
merge的语法:
MERGE INTO <target table> AS T USING <source expression/table> AS S ON <boolean expression1>
WHEN MATCHED [AND <boolean expression2>] THEN UPDATE SET <set clause list>
WHEN MATCHED [AND <boolean expression3>] THEN DELETE
WHEN NOT MATCHED [AND <boolean expression4>] THEN INSERT VALUES<value list>
merge的局限性:
最多三条when语句,只支持update/delete/insert。when not matched 必须在when语句的最后面。
如果出现update和delete的时候 ,两个条件是分开的,而且必须在条件前面加上AND.像 [AND <boolean expression>]
(5)例子
a.创建两个事务表
CREATE TABLE IF NOT EXISTS employee (
emp_id int,
emp_name string,
dept_name string,
work_loc string )
PARTITIONED BY (start_date string)
CLUSTERED BY (emp_id) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES('transactional'='true'); create table employee_state(
emp_id int,
emp_name string,
dept_name string,
work_loc string,
start_date string,
state string
)
STORED AS ORC;
b.开启事务(见上面的开启事务的c,一般有些默认的设置是开的,我这里就只开了自动分区和分桶)
c.插入数据
INSERT INTO table employee PARTITION (start_date) VALUES (1,'Will','IT','Toronto','20100701'),
(2,'Wyne','IT','Toronto','20100701'),
(3,'Judy','HR','Beijing','20100701'),
(4,'Lili','HR','Beijing','20101201'),
(5,'Mike','Sales','Beijing','20101201'), (6,'Bang','Sales','Toronto','20101201'), (7,'Wendy','Finance','Beijing','20101201'); insert into table employee_state values
(2,’Wyne’,’IT’,’Beijing’,’20100701’,’update’),
(4,’Lili’,’HR’,’Beijing’,’20101201’,’quit’),
(8,’James’,’IT’,’Toronto’,’20170101’,’new’)
d.检验数据是否被插入
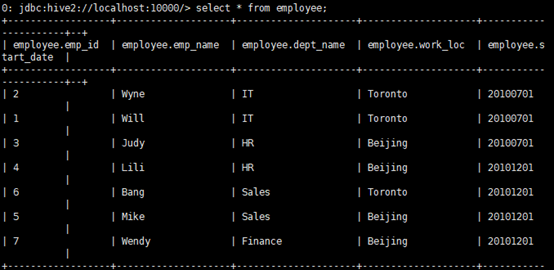

e.这里通过merge操作,完成更新、删除、插入操作。
employe字段解释:id为2的员工之前的工作地在Toronto,现在在Beijing,state的状态为update。所以需要更新表employee中员工2的信息
id为4的员工的state状态为quit,说明目前员工已经离职,所以需要在employee表中删除关于id为4的员工的信息。
id为8的员工的state状态为new,说明是新员工,所以需要插入empoyee中。
MERGE INTO employee AS T
USING employee_state AS S
ON T.emp_id = S.emp_id and T.start_date = S.start_date
WHEN MATCHED AND S.state = 'update' THEN UPDATE SET dept_name = S.dept_name,work_loc = S.work_loc
WHEN MATCHED AND S.state = 'quit' THEN DELETE
WHEN NOT MATCHED THEN INSERT VALUES(S.emp_id,S.emp_name,S.dept_name,S.work_loc,S.start_date);
--这里目标表为employee,源表为employee_state
--这里新员工是属于第三中情况,未在目标表中匹配到,所以直接插入到目标表中。

二.hive的udf
(1)什么是hive的udf?
User-defined function (UDF): 这提供了一种使用外部函数(在Java中)扩展功能的方法,可以在HQL中进行评估
(2)hive的udf分类
hive的udf一般分为三种:
a.UDF:用户定义的简单函数,按行操作并为一行输出一个结果,例如大多数内置数学和字符串函数
b.UDAF: 用户定义的聚合函数,按行或按组操作,并为每个组输出一行或一行,例如MAX和COUNT内置函数。
c.UDTF:用户定义的表生成函数也按行运行,但结果会生成多行/表,例如EXPLODE函数。 UDTF可以在SELECT之后或在LATERAL VIEW语句之后使用。
(3)hive的udf使用举例
a.对于hive的udf,这里我写了一个把字符串的大写全部换成小写和一个判断字符串是否在一个array数组里面的函数
--将字符串的所有大写改成小写
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text; public final class StringLower extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
--判断当前字符串是否在数组里面
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde.serdeConstants;
import org.apache.hadoop.hive.serde2.objectinspector.ListObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorUtils;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.BooleanWritable; @Description(name = "Arraycontains",
value="_FUNC_(array, value) - Returns TRUE if the array contains value.",
extended="Example:\n"
+ " > SELECT _FUNC_(array(1, 2, 3), 2) FROM src LIMIT 1;\n"
+ " true") public class ArrayContains extends GenericUDF {
private static final int ARRAY_IDX = 0;
private static final int VALUE_IDX = 1;
private static final int ARG_COUNT = 2;//这个udf函数需要参数的个数
private static final String FUNC_NAME = "ARRAYCONTAINS";//外部名字 private transient ObjectInspector valueOI;
private transient ListObjectInspector arrayOI;
private transient ObjectInspector arrayElementOI;
private BooleanWritable result;
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
//检查是否传入了两个参数
if (arguments.length != ARG_COUNT) {
throw new UDFArgumentException("the function" + FUNC_NAME + "accepts"
+ ARG_COUNT + "arguments");
}
//检查参数是否是属于LIST类型
if (!arguments[ARRAY_IDX].getCategory().equals(ObjectInspector.Category.LIST)) {
throw new UDFArgumentTypeException(ARRAY_IDX, "\"" + serdeConstants.LIST_TYPE_NAME + "\""
+ "expected at function ARRAY_CONTAINS,but"
+ "\"" + arguments[ARRAY_IDX].getTypeName() + "\""
+ "is found"); } arrayOI = (ListObjectInspector) arguments[ARRAY_IDX];
arrayElementOI = arrayOI.getListElementObjectInspector(); valueOI = arguments[VALUE_IDX]; //检查list的元素和传入的值是否属于同一个类型
if (!ObjectInspectorUtils.compareTypes(arrayElementOI, valueOI)) {
throw new UDFArgumentTypeException(VALUE_IDX, "\"" + arrayElementOI.getTypeName() + "\""
+ "expectd at function ARRAY_CONTAINS,but"
+ "\"" + valueOI.getTypeName() + "\""
+ "is found");
} //检查此类型是否支持比较
if (!ObjectInspectorUtils.compareSupported(valueOI)){
throw new UDFArgumentException("this function" + FUNC_NAME
+"does not support comparison for"
+"\"" + valueOI.getTypeName() + "\""
+ "types"); }
result = new BooleanWritable(false);
return PrimitiveObjectInspectorFactory.writableBooleanObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
result.set(false);
Object array = arguments[ARRAY_IDX].get();
Object value = arguments[VALUE_IDX].get(); int arrayLength = arrayOI.getListLength(array); //检查数组是否null还是空value是否为null
if (value == null || arrayLength <= 0)//判断value是否为空,若真则不判断右边,不然为假继续判断右边
{
return result;//满足条件直接返回result初始状态值
} //将值与数组的每个元素进行比较,直到找到匹配项
for (int i=0;i<arrayLength;i++){
Object listElement = arrayOI.getListElement(array,i);
if(listElement != null){
if (ObjectInspectorUtils.compare(value,valueOI,listElement,arrayElementOI) == 0){
result.set(true);//找到匹配,直接将result置于真
break;
}
}
} return result;//返回真值result
} @Override
public String getDisplayString(String[] childeren) {
assert (childeren.length == ARG_COUNT);
return "array_contains(" + childeren[ARRAY_IDX] + ","
+ childeren[VALUE_IDX] + ")";
}
}
b.然后通过编译器打包到hdfs文件系统上,通过执行hive命令构造函数
DROP FUNCTION IF EXISTS str_lower;
DROP FUNCTION IF EXISTS Array_contains;
CREATE FUNCTION str_lower AS 'com.data.hiveudf.udf.StringLower'
USING JAR 'hdfs:////apps/hive/functions/df-hiveudf-1.0-SNAPSHOT.jar';
CREATE FUNCTION Array_contains AS 'com.data.hiveudf.gudf.ArrayContains'
USING JAR 'hdfs:////apps/hive/functions/df-hiveudf-1.0-SNAPSHOT.jar';
c.使用自定义函数
这里使用了另一库里的一张employee表,里面使用了string类型、array类型...。表描述与内容如下:
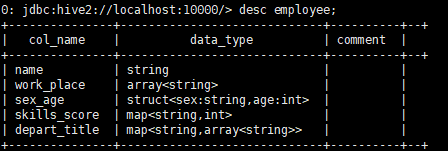
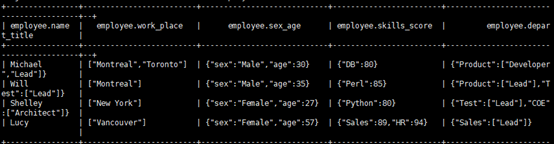
然后使用str_lower的函数:

使用Array_contains函数

hive的实践部分的更多相关文章
- 大数据(2):基于sogou.500w.utf8数据hive的实践
一.环境的搭建 1.安装配置mysql rpm –ivh MySQL-server-5.6.14.rpm rpm –ivh MySQL-client-5.6.14.rpm 启动mysql 创建hive ...
- 《细细品味Hive》系列课程
Hi,博友: 我是解耀伟,笔名是虾皮,最近我在极客学院录制Hive系列教程,也是督促自己学习一种方式,可以把自己的学习积累有方向,星期天也能做点有意义的事情.在做每一期的过程中,需要找资料,总结,先自 ...
- hbase+hive应用场景
一.Hive应用场景本文主要讲述使用 Hive 的实践,业务不是关键,简要介绍业务场景,本次的任务是对搜索日志数据进行统计分析.集团搜索刚上线不久,日志量并不大 .这些日志分布在 5 台前端机,按小时 ...
- DataPipeline在大数据平台的数据流实践
文 | 吕鹏 DataPipeline架构师 进入大数据时代,实时作业有着越来越重要的地位.本文将从以下几个部分进行讲解DataPipeline在大数据平台的实时数据流实践. 一.企业级数据面临的主要 ...
- Hive原理总结(完整版)
目录 课程大纲(HIVE增强) 3 1. Hive基本概念 4 1.1 Hive简介 4 1.1.1 什么是Hive 4 1.1.2 为什么使用Hive 4 1.1.3 Hive的特点 4 1.2 H ...
- 基于hive的日志分析系统
转自 http://www.cppblog.com/koson/archive/2010/07/19/120773.html hive 简介 hive 是一个基于 ...
- hive数据仓库入门到实战及面试
第一章.hive入门 一.hive入门手册 1.什么是数据仓库 1.1数据仓库概念 对历史数据变化的统计,从而支撑企业的决策.比如:某个商品最近一个月的销量,预判下个月应该销售多少,从而补充多少货源. ...
- DataPipeline联合Confluent Kafka Meetup上海站
Confluent作为国际数据“流”处理技术领先者,提供实时数据处理解决方案,在市场上拥有大量企业客户,帮助企业轻松访问各类数据.DataPipeline作为国内首家原生支持Kafka解决方案的“iP ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
随机推荐
- sql 脚本 oracle scott 用户的四张表导入 mysql 中
/* 要先删除emp表,不能先删除dept表,因为dept有一个外键关联emp表*/drop TABLE emp;drop TABLE dept; drop TABLE salgrade;drop T ...
- redis mysql验证 redis_mysql_check.py
# coding:utf-8 import pymysql import redis import sys def con_mysql(sql): db = pymysql.connect(host= ...
- 事件驱动模型 IO多路复用 阻塞IO与非阻塞IO select epool
一.事件驱动 1.要理解事件驱动和程序,就需要与非事件驱动的程序进行比较.实际上,现代的程序大多是事件驱动的,比如多线程的程序,肯定是事件驱动的.早期则存在许多非事件驱动的程序,这样的程序,在需要等待 ...
- 五、vue常用UI组件
下面简单的总结下vue常用的一些UI 组件,有一些我也没怎么用过,这里先罗列出来,便于自己后面使用的时候查找方便,大家有更好的可以给我推荐哦~ vuex: vux github ui demo:htt ...
- SQL Server ->> 使用CROSS APPLY语句是遇到聚合函数中包含外部引用列时报错
本次遇到的问题是CROSS APPLY的内部查询语句中的聚合函数包含CASE WHEN判断,且同时又内部语句的表的列和外部引用的表的列,此时会报下列的错误. 消息 8124,级别 16,状态 1,第 ...
- 用Spider引擎解决数据库垂直和水平拆分的问题
作者介绍 张秀云,网名飞鸿无痕,现任职于腾讯,负责腾讯金融数据库的运维和优化工作.2007年开始从事运维方面的工作,经历过网络管理员.Linux运维工程师.DBA.分布式存储运维等多个IT职位.对Li ...
- iOS中block类型大全
iOS中block类型大全 typedef的block 作为属性的block 作为变量的block 作为方法变量入参的block 作为方法参数的block 无名block 内联函数的block 递归调 ...
- Linux 环境部署记录(二) - NFS文件共享
NFS文件共享服务 假设现有两台服务器IP地址分别为 192.168.0.2 和 192.168.0.3,192.168.0.2作为Server,192.168.0.3为Client,则: 两台机器都 ...
- apt-spy来获得适合自己的源,适用于UBUNTU/Debian
使用ubuntu和debian等使用APT源的系统,有些时候是不是会不知道哪里有源,哪里的源比较快让自己的宽带完全利用,我们可以用apt-spy来自动找到 apt-spy -d unstable -a ...
- Linux上安装ZooKeeper并设置开机启动(CentOS7+ZooKeeper3.4.10)
1下载Zookeeper 2安装启动测试 2.1上载压缩文件并解压 2.2新建 zookeeper配置文件 2.3安装JDK 2.4启动zookeeper 2.5查看zookeeper的状态 3将Zo ...