编写python爬虫采集彩票网站数据,将数据写入mongodb数据库
1.准备工作:
1.1安装requests: cmd >> pip install requests
1.2 安装lxml: cmd >> pip install lxml
1.3安装wheel: cmd >> pip install wheel
1.4 安装xlwt: cmd >> pip install xlwt
1.5 安装pymongo: cmd >> pip install pymongo 完整代码
import requests
from lxml import etree
import xlwt
from pymongo import MongoClient #设置浏览器的请求头,告诉服务器我们是从浏览器来的,作用是阻止被网站反爬
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Connection': 'keep-alive'
} # 创建数据库
client = MongoClient()
database = client['Chapter6']
collection = database['webdata'] for i in range(1, 21):
url = "http://kaijiang.zhcw.com/zhcw/html/3d/list_{}.html".format(i)
#发送请求 得到数据
response = requests.get(url=url,headers=headers)
#print(response.text) #将数据改成xpath结构
res_xpath = etree.HTML(response.text)
trs = res_xpath.xpath('/html/body/table//tr') # 将数据写入MongoDB数据库
for tr in trs[2:-1]:
data = {
'开奖日期': tr.xpath("./td[1]/text()")[0],
'期号': tr.xpath("./td[2]/text()")[0],
'中奖号码1': tr.xpath("./td[3]/em[1]/text()")[0],
'中奖号码2': tr.xpath("./td[3]/em[2]/text()")[0],
'中奖号码3': tr.xpath("./td[3]/em[3]/text()")[0],
'销售额(元)': tr.xpath("./td[4]/text()")[0],
'返奖比例': tr.xpath("./td[5]/text()")[0]
}
collection.insert_one(data);
实现效果
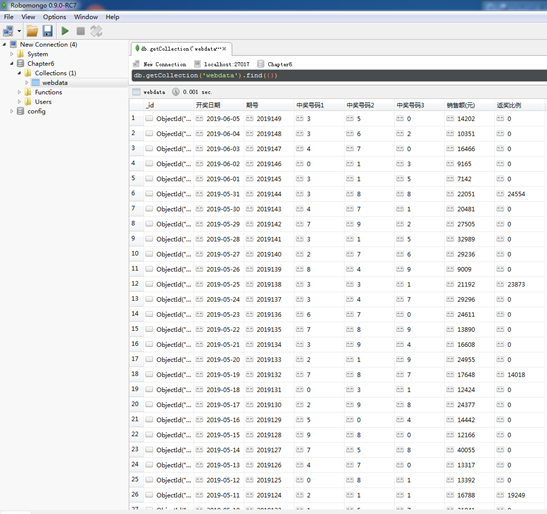
编写python爬虫采集彩票网站数据,将数据写入mongodb数据库的更多相关文章
- python爬虫采集
python爬虫采集 最近有个项目需要采集一些网站网页,以前都是用php来做,但现在十分流行用python做采集,研究了一些做一下记录. 采集数据的根本是要获取一个网页的内容,再根据内容筛选出需要的数 ...
- python爬虫之天气预报网站--查看最近(15天)的天气信息(正则表达式)
python爬虫之天气预报网站--查看最近(15天)的天气信息(正则表达式) 思路: 1.首先找到一个自己想要查看天气预报的网站,选择自己想查看的地方,查看天气(例:http://www.tianqi ...
- python爬虫之12306网站--火车票信息查询
python爬虫之12306网站--火车票信息查询 思路: 1.火车票信息查询是基于车站信息查询,先完成车站信息查询,然后根据车站信息查询生成的url地址去查询当前已知出发站和目的站的所有车次车票信息 ...
- python爬虫之小说网站--下载小说(正则表达式)
python爬虫之小说网站--下载小说(正则表达式) 思路: 1.找到要下载的小说首页,打开网页源代码进行分析(例:https://www.kanunu8.com/files/old/2011/244 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- 一个月入门Python爬虫,轻松爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得 ...
- Python爬虫某招聘网站的岗位信息
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:阿尔法游戏 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬虫(九)_非结构化数据与结构化数据
爬虫的一个重要步骤就是页面解析与数据提取.更多内容请参考:Python学习指南 页面解析与数据提取 实际上爬虫一共就四个主要步骤: 定(要知道你准备在哪个范围或者网站去搜索) 爬(将所有的网站的内容全 ...
- Python爬虫:用BeautifulSoup进行NBA数据爬取
爬虫主要就是要过滤掉网页中没用的信息.抓取网页中实用的信息 一般的爬虫架构为: 在python爬虫之前先要对网页的结构知识有一定的了解.如网页的标签,网页的语言等知识,推荐去W3School: W3s ...
随机推荐
- jmxtrans + OpenTSDB + granafa 监控套件使用手册
需求说明 编写背景 此手册的基础在于对<jmxtrans + influxdb + granafa 监控套件使用手册>的熟悉和使用.本手册仅介绍以下几项: OpenTSDB 的配置安装 对 ...
- python学习之路(21)
偏函数 Python的functools模块提供了很多有用的功能,其中一个就是偏函数(Partial function).要注意,这里的偏函数和数学意义上的偏函数不一样. 在介绍函数参数的时候,我们讲 ...
- pip & conda 换源
conda换源方法具体参考清华大学镜像站Anaconda 镜像使用帮助 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn ...
- Vue学习日记(二)——Vue核心思想
前言 Vue.js是一个提供MVVM数据双向绑定的库,其核心思想无非就是: 数据驱动 组件系统 数据驱动 Vue.js 的核心是一个响应的数据绑定系统,它让数据与DOM保持同步非常简单.在使用 jQu ...
- Scala学习(三)——集合
基本数据结构 Scala提供了一些不错的集合. 数组 Array 数组是有序的,可以包含重复项,并且可变. val numbers = Array(1, 2, 3, 4, 5, 1, 2, 3, 4, ...
- synchronized 读写同步
synchronized 读写同步 这是一道面试题,很多人也遇到了. 要求:1.读-读 不用线程同步.2.读-写 要求线程同步,写的时候不能读.3.写-写同步.写的时候不能写. java lock读写 ...
- vue组件化初体验 全局组件和局部组件
vue组件化初体验 全局组件和局部组件 vue组件化 全局组件 局部组件 关于vue入门案例请参阅 https://www.cnblogs.com/singledogpro/p/11938222.h ...
- Windows UI Library - Roadmap Win UI3.0
https://github.com/microsoft/microsoft-ui-xaml/blob/master/docs/roadmap.md 微软更新太快了.是不是要把开发人员折磨死.... ...
- WPF 打字效果
看到有篇是用关键字动画来做的,感觉性能不是很好,万一字太多,比如几百上千个字那会加几百上千个关键帧... 下面是我自己写的: public MainWindow() { InitializeCompo ...
- leetcode 11盛水最多的容器
class Solution { public: int maxArea(vector<int>& height) { //双指针法:从最宽的容器开始计算,当更窄的容器盛水量要大于 ...