异常检测算法的Octave仿真
在基于高斯分布的异常检测算法一文中,详细给出了异常检测算法的原理及其公式,本文为该算法的Octave仿真。实例为,根据训练样例(一组网络服务器)的吞吐量(Throughput)和延迟时间(Latency)数据,标记出异常的服务器。
可视化的数据集如下:
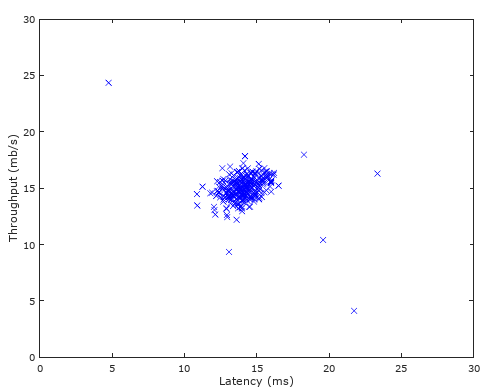
我们根据数据集X,计算其二维高斯分布的数学期望mu与方差sigma2:
function [mu sigma2] = estimateGaussian(X)
%ESTIMATEGAUSSIAN This function estimates the parameters of a
%Gaussian distribution using the data in X
% [mu sigma2] = estimateGaussian(X),
% The input X is the dataset with each n-dimensional data point in one row
% The output is an n-dimensional vector mu, the mean of the data set
% and the variances sigma^2, an n x 1 vector
% % Useful variables
[m, n] = size(X); mu = zeros(n, 1);
sigma2 = zeros(n, 1); mu = sum(X,1)'/m;
%note:mu and sigma are both n-demension.
for(i=1:m)
e=(X(i,:)'-mu);
sigma2 += e.^2;
endfor sigma2 = sigma2/m end
计算概率密度:
function p = multivariateGaussian(X, mu, Sigma2)
%MULTIVARIATEGAUSSIAN Computes the probability density function of the
%multivariate gaussian distribution.
% p = MULTIVARIATEGAUSSIAN(X, mu, Sigma2) Computes the probability
% density function of the examples X under the multivariate gaussian
% distribution with parameters mu and Sigma2. If Sigma2 is a matrix, it is
% treated as the covariance matrix. If Sigma2 is a vector, it is treated
% as the \sigma^2 values of the variances in each dimension (a diagonal
% covariance matrix)
% k = length(mu); if (size(Sigma2, 2) == 1) || (size(Sigma2, 1) == 1)
Sigma2 = diag(Sigma2);
end X = bsxfun(@minus, X, mu(:)');
p = (2 * pi) ^ (- k / 2) * det(Sigma2) ^ (-0.5) * ...
exp(-0.5 * sum(bsxfun(@times, X * pinv(Sigma2), X), 2)); end
可视化后:

根据预留的一部分已知是否异常的训练样例(CV集),来选择阈值:
function [bestEpsilon bestF1] = selectThreshold(yval, pval)
%SELECTTHRESHOLD Find the best threshold (epsilon) to use for selecting
%outliers
% [bestEpsilon bestF1] = SELECTTHRESHOLD(yval, pval) finds the best
% threshold to use for selecting outliers based on the results from a
% validation set (pval) and the ground truth (yval).
% bestEpsilon = 0;
bestF1 = 0;
F1 = 0; stepsize = (max(pval) - min(pval)) / 1000;
for epsilon = min(pval):stepsize:max(pval) pred = (pval<epsilon); p_e_1 = (pred==1);
y_e_1 = (yval==1);
p1 = 0;
m = size(p_e_1,1);
for(i=1:m)
if((p_e_1(i)==1)&&(p_e_1(i)==y_e_1(i)))
p1++;
endif
endfor
p_12 = sum(pred);
p_13 = sum(y_e_1); p=p1/p_12;
r=p1/p_13; F1 = 2*p*r/(p+r); if F1 > bestF1
bestF1 = F1;
bestEpsilon = epsilon;
end
end end
最终的标记结果:

异常检测算法的Octave仿真的更多相关文章
- 如何开发一个异常检测系统:使用什么特征变量(features)来构建异常检测算法
如何构建与选择异常检测算法中的features 如果我的feature像图1所示的那样的正态分布图的话,我们可以很高兴地将它送入异常检测系统中去构建算法. 如果我的feature像图2那样不是正态分布 ...
- 异常检测算法--Isolation Forest
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结. iTree 提到森林 ...
- 机器学习:异常检测算法Seasonal Hybrid ESD及R语言实现
Twritters的异常检测算法(Anomaly Detection)做的比较好,Seasonal Hybrid ESD算法是先用STL把序列分解,考察残差项.假定这一项符合正态分布,然后就可以用Ge ...
- 异常检测算法:Isolation Forest
iForest (Isolation Forest)是由Liu et al. [1] 提出来的基于二叉树的ensemble异常检测算法,具有效果好.训练快(线性复杂度)等特点. 1. 前言 iFore ...
- 【机器学习】异常检测算法(I)
在给定的数据集,我们假设数据是正常的 ,现在需要知道新给的数据Xtest中不属于该组数据的几率p(X). 异常检测主要用来识别欺骗,例如通过之前的数据来识别新一次的数据是否存在异常,比如根据一个用户以 ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- 异常检测(Anomaly detection): 异常检测算法(应用高斯分布)
估计P(x)的分布--密度估计 我们有m个样本,每个样本有n个特征值,每个特征都分别服从不同的高斯分布,上图中的公式是在假设每个特征都独立的情况下,实际无论每个特征是否独立,这个公式的效果都不错.连乘 ...
- 异常检测算法Robust Random Cut Forest(RRCF)关键定理引理证明
摘要:RRCF是亚马逊发表的一篇异常检测算法,是对周志华孤立森林的改进.但是相比孤立森林,具有更为扎实的理论基础.文章的理论论证相对较为晦涩,且没给出详细的证明过程.本文不对该算法进行详尽的描述,仅对 ...
- 时间序列异常检测算法S-H-ESD
1. 基于统计的异常检测 Grubbs' Test Grubbs' Test为一种假设检验的方法,常被用来检验服从正太分布的单变量数据集(univariate data set)\(Y\) 中的单个异 ...
随机推荐
- opencv中画圆circle函数和椭圆ellipse函数
1. void ellipse(InputOutputArray img, Point center, Size axes, double angle, double startAngle, ...
- 关于 Python 程序的运行方面,有什么手段能提升性能?
1.使用多进程,充分利用机器的多核性能2.对于性能影响较大的部分代码,可以使用 C 或 C++编写3.对于 IO 阻塞造成的性能影响,可以使用 IO 多路复用来解决4.尽量使用 Python 的内建函 ...
- C# 中File和FileStream的用法
原文:https://blog.csdn.net/qq_41209575/article/details/89178020 1.首先先介绍File类和FileStream文件流 1.1 File类, ...
- 提升JAVA代码的好“味道”
让代码性能更高 需要 Map 的主键和取值时,应该迭代 entrySet() 当循环中只需要 Map 的主键时,迭代 keySet() 是正确的.但是,当需要主键和取值时,迭代 entrySet() ...
- ssh: Could not resolve hostname github.com: Name or service not known
问题描述 今天早上在自己的虚拟机上用git pull命令更新github上的版本库时提示下面的错误 [root@localhost ~] git clone git@github.com:sdscbr ...
- unity2017 光照与渲染(一)
光照&渲染(基于unity2017.2.0) Custom Skybox 天空盒 最丰富的环境光 a. TextureShape 改成 Cube. b. 把图片直接丢给天空,就会自动生成材质. ...
- Linux用户都应该了解的命令行省时技巧
每个Linux用户都应该了解的命令行省时技巧 有网友在问答网站Quora上提问:“有哪些省时小技巧,是每个Linux用户都应该知道的?” Joshua Levy 平常就在 Linux 平台工作,并且他 ...
- .iml文件恢复
基于maven的java工程 执行 mvn idea:module可恢复.iml文件
- git 操作遇到的问题与解决方法
一.使用git在本地创建一个项目的过程,Git 上传本地文件到github $ makdir ~/hello-world //创建一个项目hello-world $ cd ~/hello-world ...
- 重置Jenkins的构建历史
1.重置单个JOB的构建历史item = Jenkins.instance.getItemByFullName("your-job-name-here") //THIS WILL ...