岭回归、lasso
参考:https://blog.csdn.net/Byron309/article/details/77716127 ---- https://blog.csdn.net/xbinworld/article/details/44276389
参考:https://blog.csdn.net/bitcarmanlee/article/details/51589143
1、首先介绍线性回归模型(多元)原理,模型可以表示为:
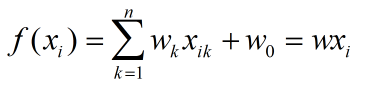
损失函数可以表示为:

这里的 1/2m 主要还是出于方便计算的考虑,在求解最小二乘的时并不考虑在内;
最小二乘法可得到最优解:
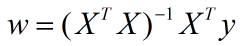
监督学习有2大基本策略,经验风险最小化和结构风险最小化;
经验风险最小化策略为求解最优化问题,线性回归中的求解损失函数最小化问题即经验风险最小化,经验风险最小化定义:
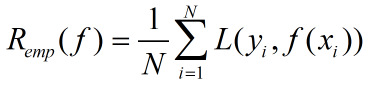
求解最优化问题可以转化为:
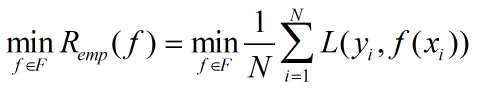
结构化风险最小化是为了防止过拟合现象提出的策略;结构风险最小化等价于正则化,在经验风险上加上表示模型复杂度的正则化项,定义如下:

这里讨论的岭回归和Lasso,也就是结构风险最小化的思想,在线性回归的基础上,加上模型复杂度的约束。
其中几种范数(norm)的定义如下:
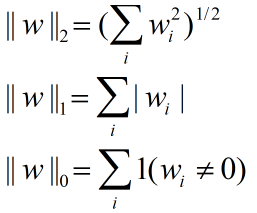
岭回归的损失函数表示:
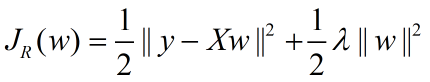
观察这条式子很容易的可以联想到正则化项为L2范数,也即L2范数+损失函数其实也可以称为岭回归;
最小二乘求解参数:
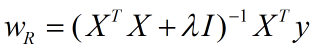
Lasso的损失函数表示:
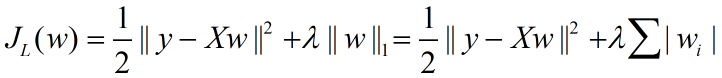
由于Lasso损失函数的导数在0点不可导,因此不能直接利用梯度下降求解;引入subgradient的概念,考虑简单函数,即x只有1维的情况下,即简单函数表示:
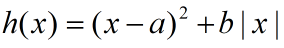
首先定义|x|在0点的梯度,即subgradient,

函数在某一点的导数可以看成函数在这一点上的切线。那么在原点,可以在实线下方找到无数条切线,形成曲线族;我们把这些切线斜率的范围定义为这点的subgradient;也即|x|在0点的导数是在-1到1范围内的任意值;
所以可以得到h(x)的导数:

在x=0的时候,按照上面的subgradient可以得到,x=0时斜率的区间在x>0和x<0之间;当-b<2a<b时,在x=0时,f'(x)能取到值0;也就是f(x)到达极值点,这也可以解释lasso下的解会稀疏的原因:在b的取值在一定范围内时,只要x为0,f'(x)就恒为0; (这句话本人不是特别理解)(先存疑),
有关subgradient的解释:https://blog.csdn.net/lansatiankongxxc/article/details/46386341
当x拓展到多维向量时,导数方向的变化范围更大,问题更为复杂;常见解决方法如下:
1、贪心算法;每次先找到与目标最相关的feature,固定其他系数,优化这个feature的系数,具体求导也用到subgradient;代表算法有LARS,feature-sign search等;
2、逐一优化;每次固定其他的维度,选择一个维度进行优化;因为只有一个方向有变化,所以转化为简单的subgradient问题,反复迭代所有维度,达到收敛;代表算法有coordinate descent,block coordinate descent等;
Lasso和ridge的几何意义如下图:

红色椭圆和蓝色的区域的切点就是目标函数的最优解;可以看到,如果是圆,很容易切到圆周的任意一点,但是很难切到坐标轴上。则在该纬度上取值不为0,因此没有系数;如果是菱形或多边形,则很容易切到坐标轴上,使部分维度特征权重为0,因此很容易产生稀疏的结果;
岭回归、lasso的更多相关文章
- 岭回归&Lasso回归
转自:https://blog.csdn.net/dang_boy/article/details/78504258 https://www.cnblogs.com/Belter/p/8536939. ...
- 线性回归——lasso回归和岭回归(ridge regression)
目录 线性回归--最小二乘 Lasso回归和岭回归 为什么 lasso 更容易使部分权重变为 0 而 ridge 不行? References 线性回归很简单,用线性函数拟合数据,用 mean squ ...
- 多重共线性的解决方法之——岭回归与LASSO
多元线性回归模型 的最小二乘估计结果为 如果存在较强的共线性,即 中各列向量之间存在较强的相关性,会导致的从而引起对角线上的 值很大 并且不一样的样本也会导致参数估计值变化非常大.即参数估 ...
- 多元线性回归模型的特征压缩:岭回归和Lasso回归
多元线性回归模型中,如果所有特征一起上,容易造成过拟合使测试数据误差方差过大:因此减少不必要的特征,简化模型是减小方差的一个重要步骤.除了直接对特征筛选,来也可以进行特征压缩,减少某些不重要的特征系数 ...
- 【机器学习】正则化的线性回归 —— 岭回归与Lasso回归
注:正则化是用来防止过拟合的方法.在最开始学习机器学习的课程时,只是觉得这个方法就像某种魔法一样非常神奇的改变了模型的参数.但是一直也无法对其基本原理有一个透彻.直观的理解.直到最近再次接触到这个概念 ...
- 机器学习--Lasso回归和岭回归
之前我们介绍了多元线性回归的原理, 又通过一个案例对多元线性回归模型进一步了解, 其中谈到自变量之间存在高度相关, 容易产生多重共线性问题, 对于多重共线性问题的解决方法有: 删除自变量, 改变数据形 ...
- 通俗易懂--岭回归(L2)、lasso回归(L1)、ElasticNet讲解(算法+案例)
1.L2正则化(岭回归) 1.1问题 想要理解什么是正则化,首先我们先来了解上图的方程式.当训练的特征和数据很少时,往往会造成欠拟合的情况,对应的是左边的坐标:而我们想要达到的目的往往是中间的坐标,适 ...
- 岭回归和Lasso回归以及norm1和norm2
norm代表的是距离,两个向量的距离:下图代表的就是p-norm,其实是对向量里面元素的一种运算: 最简单的距离计算(规范)是欧式距离(Euclidean distance),两点间距离是如下来算的, ...
- 吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import mod ...
- 岭回归和lasso回归(转)
回归和分类是机器学习算法所要解决的两个主要问题.分类大家都知道,模型的输出值是离散值,对应着相应的类别,通常的简单分类问题模型输出值是二值的,也就是二分类问题.但是回归就稍微复杂一些,回归模型的输出值 ...
随机推荐
- windows 把ps/2 鼠标当成ps/2键盘了
真坑口阿 https://zhidao.baidu.com/question/425134865713508932.html 电脑的PS/2鼠标接口认成键盘了 电脑主板技嘉,只有一个PS/2接口.开始 ...
- Babel编译:类
编译前 class Fruit{ static nutrition = "vitamin" static plant(){ console.log('种果树'); } name; ...
- python+selenium下载文件——firefox
修改Firefox的相关配置. 1.profile.set_preference('browser.download.folderList',2) 设置成0代表桌面,1代表下载到浏览器默认下载路径:2 ...
- js中 json对象的转化 JSON.parse()
JSON.parse() 方法用来解析JSON字符串,json.parse()将字符串转成json对象.构造由字符串描述的JavaScript值或对象.提供可选的reviver函数用以在返回之前对所得 ...
- 惠普IPMI登陆不上
[问题描述] IPMI登陆不上(HP),点击无反应. 浏览器使用IE,java版本使用32位1.7版本. [问题原因] 保护此网站的证书使用弱加密,即 SHA1.此网站应该在 SHA1 被禁用之前将该 ...
- CentOS7配置NFS网络文件系统
NFS,是Network File System的简写,即网络文件系统.网络文件系统是FreeBSD支持的文件系统中的一种,也被称为NFS. NFS允许一个系统在网络上与他人共享目录和文件.通过使用N ...
- Tomcat进程、SFTP服务器
查看Tomcat是否以关闭 ps -ef|grep tomcat port sftp -oPort=60001 root@192.168.0.254
- [Git] 017 加一条分支,享双倍快乐
0. 回顾 [Git] 009 逆转未来 中的 "2.2" 讲过 git checkout -- <file> 这回的 git checkout <branch_ ...
- CSP-J&S 2019游记
$Day -???$ 和爱国爱党的$LQX$书记打了个赌,谁$TG$分低请另一个京味斋. $Day 0$ 机房同学去聚餐,美其名曰"散伙饭",可能又有几个进队的... 我没有去,因 ...
- 奇葩的狐火浏览器border属性
今天接到一个bug任务,客户反映火狐浏览器访问时某个商品楼层不显示商品.我立即打开我的火狐浏览器发现没有复现这个bug,后来经过一番折腾,才发现火狐浏览器缩放到90%时,商品楼层果然就消失了,而且每台 ...