Pytorch实战学习(八):基础RNN
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
Basic RNN
①用于处理序列数据:时间序列、文本、语音.....
②循环过程中权重共享机制
一、RNN原理
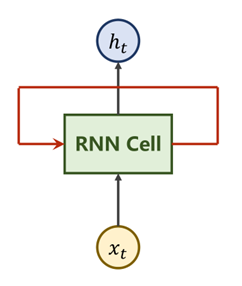
① Xt表示时刻t时输入的数据
② RNN Cell—本质是一个线性层
③ Ht表示时刻t时的输出(隐藏层)
RNN Cell为一个线性层Linear,在t时刻下的N维向量,经过Cell后即可变为一个M维的向量h_t,而与其他线性层不同,RNN Cell为一个共享的线性层,即重复利用,权重共享。
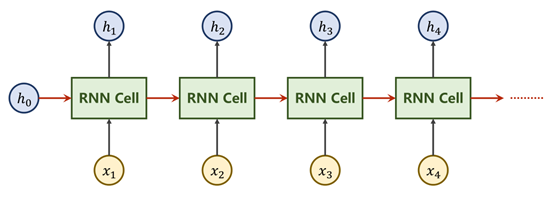
X1…Xn是一组序列数据,每个Xi都至少包含Xi-1的信息
比如h2里面包含了X1的信息
就是要把X1经过RNN Cell处理后的h1向下传递,和X2一起输入到第二个RNN Cell中
二、RNN 计算过程
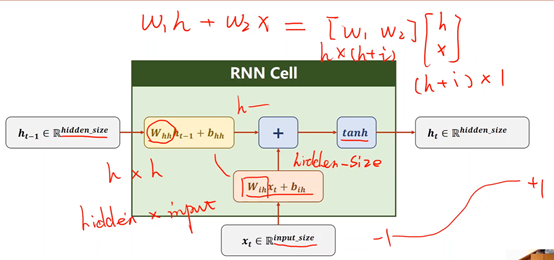
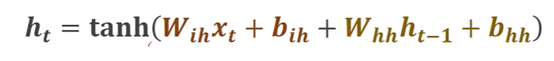
三、Pytorch实现
方法①
先创建RNN Cell(要确定好输入和输出的维度)
再写循环

BatchSize—批量大小
SeqLen—样本数量
InputSize—输入维度
HiddenSize—隐藏层(输出)维度

import torch #参数设置
batch_size = 1
seq_len = 3
input_size = 4
hidden_size =2 #构造RNN Cell
cell = torch.nn.RNNCell(input_size = input_size, hidden_size = hidden_size) #维度最重要(seq,batch,features)
dataset = torch.randn(seq_len,batch_size,input_size) #初始化时设为零向量
hidden = torch.zeros(batch_size, hidden_size) #训练的循环
for idx,input in enumerate(dataset):
print('=' * 20,idx,'=' * 20)
print('Input size:', input.shape) # 当前的输入和上一层的输出
hidden = cell(input, hidden) print('outputs size: ', hidden.shape)
print(hidden)

方法②
直接调用RNN

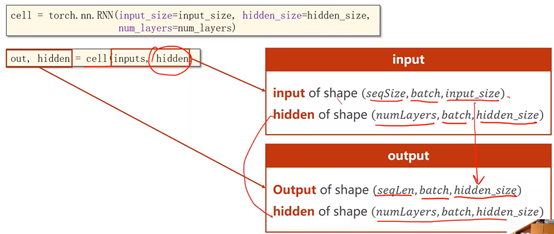
BatchSize—批量大小
SeqLen—样本数量
InputSize—输入维度
HiddenSize—隐藏层(输出)维度
NumLayers—RNN层数

多层RNN
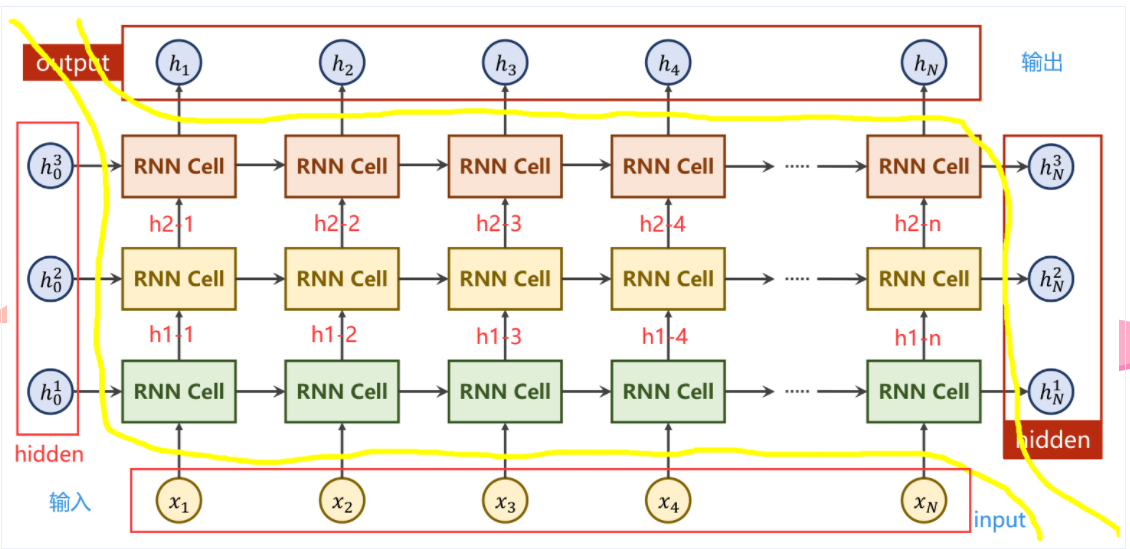
# 直接调用RNN
import torch batch_size = 1
seq_len = 5
input_size = 4
hidden_size =2
num_layers = 3 #其他参数
#batch_first=True 维度从(SeqLen*Batch*input_size)变为(Batch*SeqLen*input_size)
cell = torch.nn.RNN(input_size = input_size, hidden_size = hidden_size, num_layers = num_layers) inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size) out, hidden = cell(inputs, hidden) print("Output size: ", out.shape)
print("Output: ", out)
print("Hidden size: ", hidden.shape)
print("Hidden: ", hidden)

四、案例
一个序列到序列(seq→seq)的问题
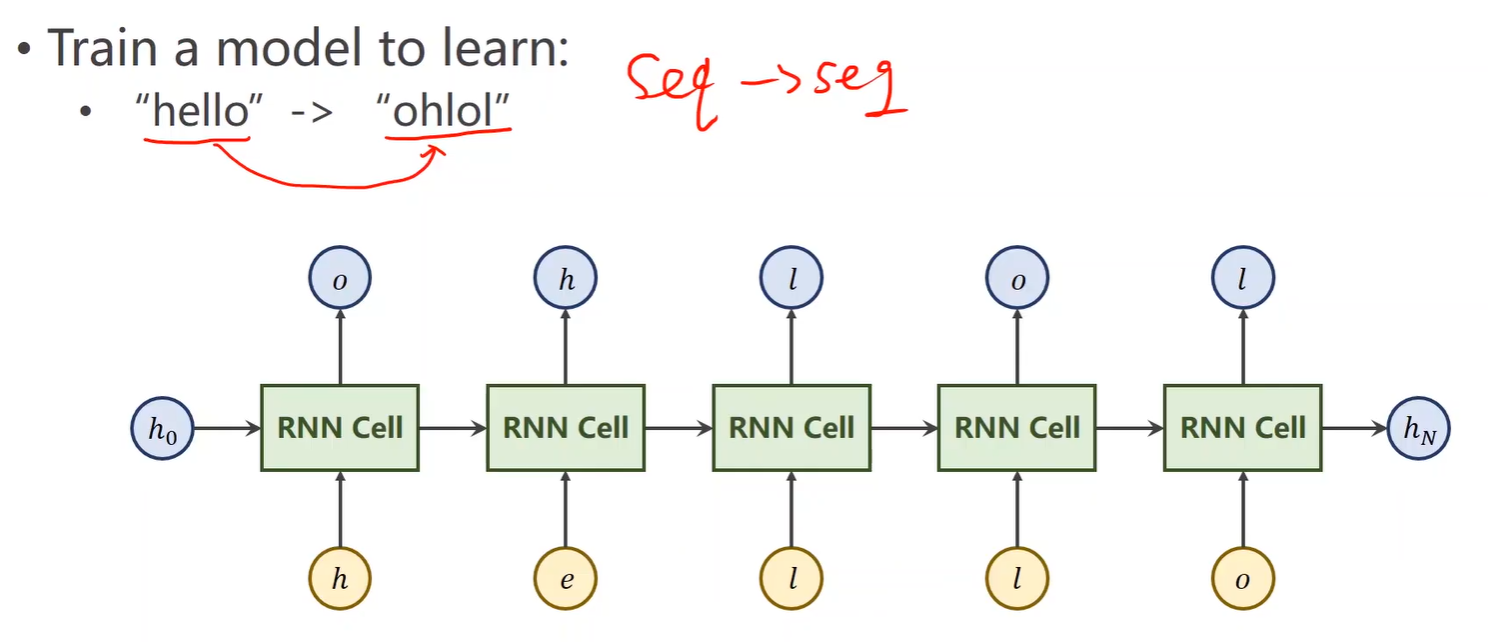
1、先将“Hello”转化成数值型向量
用 one-hot编码
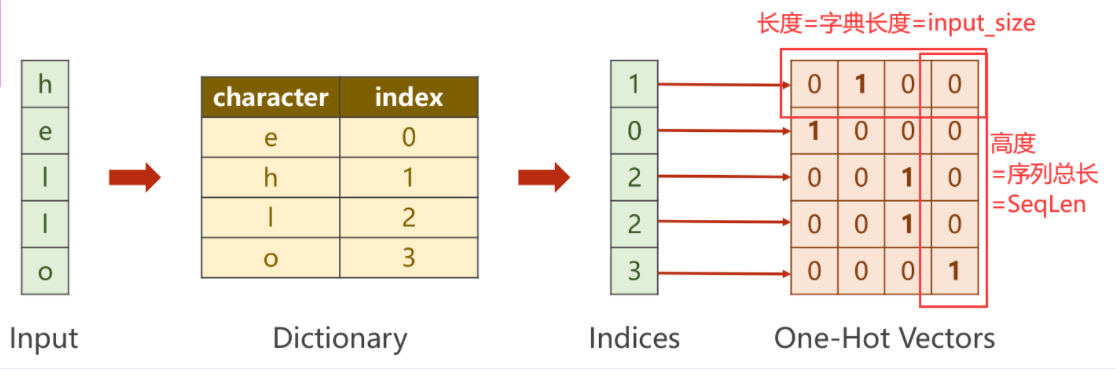
多分类问题(输出维度为4)经过Softmax求得映射之后的概率分别是多少,再利用输出对应的独热向量,计算NLLLoss
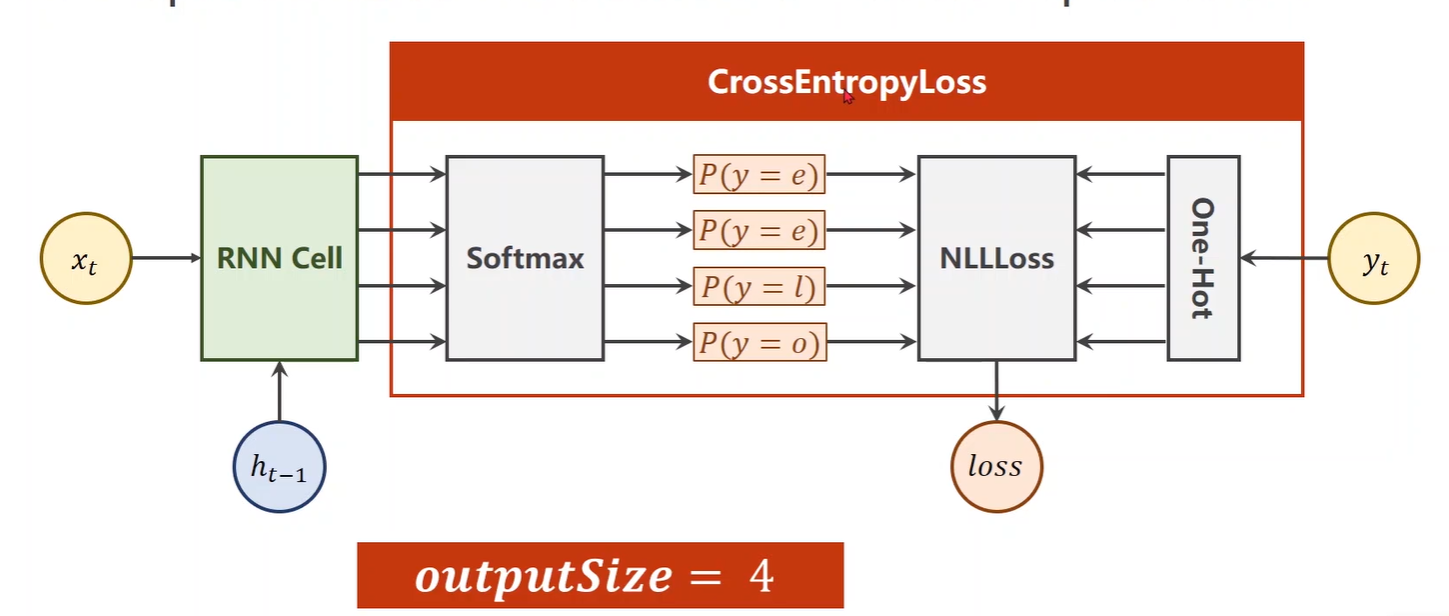
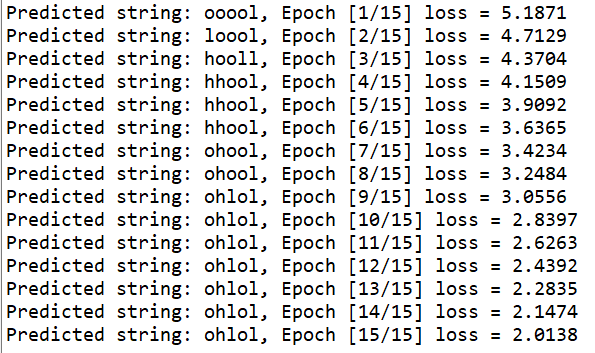
方法① RNN Cell
import torch input_size = 4
hidden_size = 3
batch_size = 1 #构建输入输出字典
idx2char_1 = ['e', 'h', 'l', 'o']
idx2char_2 = ['h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [2, 0, 1, 2, 1]
# y_data = [3, 1, 2, 2, 3]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
#构造独热向量,此时向量维度为(SeqLen*InputSize)
x_one_hot = [one_hot_lookup[x] for x in x_data]
#view(-1……)保留原始SeqLen,并添加batch_size,input_size两个维度
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
#将labels转换为(SeqLen*1)的维度
labels = torch.LongTensor(y_data).view(-1, 1) class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size self.rnncell = torch.nn.RNNCell(input_size = self.input_size,
hidden_size = self.hidden_size) def forward(self, input, hidden):
# RNNCell input = (batchsize*inputsize)
# RNNCell hidden = (batchsize*hiddensize)
# h_i = cell(x_i , h_i-1)
hidden = self.rnncell(input, hidden)
return hidden #初始化零向量作为h0,只有此处用到batch_size
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size) net = Model(input_size, hidden_size, batch_size) criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1) for epoch in range(15):
#损失及梯度置0,创建前置条件h0
loss = 0
optimizer.zero_grad()
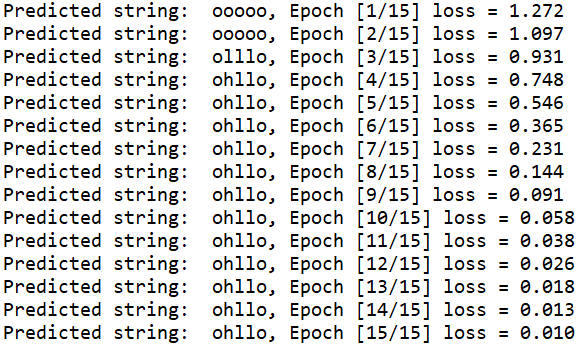
hidden = net.init_hidden() print("Predicted string: ",end="")
#inputs=(seqLen*batchsize*input_size) labels = (seqLen*1)
#input是按序列取的inputs元素(batchsize*inputsize)
#label是按序列去的labels元素(1)
for input, label in zip(inputs, labels):
hidden = net(input, hidden)
#序列的每一项损失都需要累加
loss += criterion(hidden, label)
#多分类取最大,找到四个类中概率最大的下标
_, idx = hidden.max(dim=1)
print(idx2char_2[idx.item()], end='') loss.backward()
optimizer.step() print(", Epoch [%d/15] loss = %.4f" % (epoch+1, loss.item()))
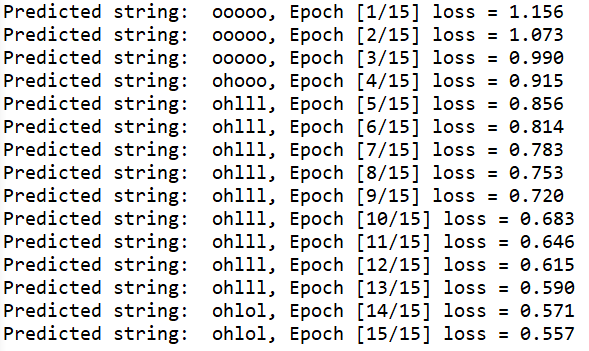
方法② RNN
import torch input_size = 4
hidden_size = 3
batch_size = 1
num_layers = 1
seq_len = 5
#构建输入输出字典
idx2char_1 = ['e', 'h', 'l', 'o']
idx2char_2 = ['h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [2, 0, 1, 2, 1]
# y_data = [3, 1, 2, 2, 3]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]] x_one_hot = [one_hot_lookup[x] for x in x_data] inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
#labels(seqLen*batchSize,1)为了之后进行矩阵运算,计算交叉熵
labels = torch.LongTensor(y_data) class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(Model, self).__init__()
self.batch_size = batch_size #构造H0
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = torch.nn.RNN(input_size = self.input_size,
hidden_size = self.hidden_size,
num_layers=num_layers) def forward(self, input):
hidden = torch.zeros(self.num_layers,
self.batch_size,
self.hidden_size)
out, _ = self.rnn(input, hidden)
#reshape成(SeqLen*batchsize,hiddensize)便于在进行交叉熵计算时可以以矩阵进行。
return out.view(-1, self.hidden_size) net = Model(input_size, hidden_size, batch_size, num_layers) criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05) #RNN中的输入(SeqLen*batchsize*inputsize)
#RNN中的输出(SeqLen*batchsize*hiddensize)
#labels维度 hiddensize*1
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step() _, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted string: ',''.join([idx2char_2[x] for x in idx]), end = '')
print(", Epoch [%d/15] loss = %.3f" % (epoch+1, loss.item()))
五、自然语言处理--词向量
独热编码在实际问题中容易引起很多问题:
- 独热编码向量维度过高,每增加一个不同的数据,就要增加一维
- 独热编码向量稀疏,每个向量是一个为1其余为0
- 独热编码是硬编码,编码情况与数据特征无关
综上所述,需要一种低维度的、稠密的、可学习数据的编码方式
1、词嵌入
(数据降维)将高维、稀疏的样本 映射到 低维、稠密的空间中

2、网络结构
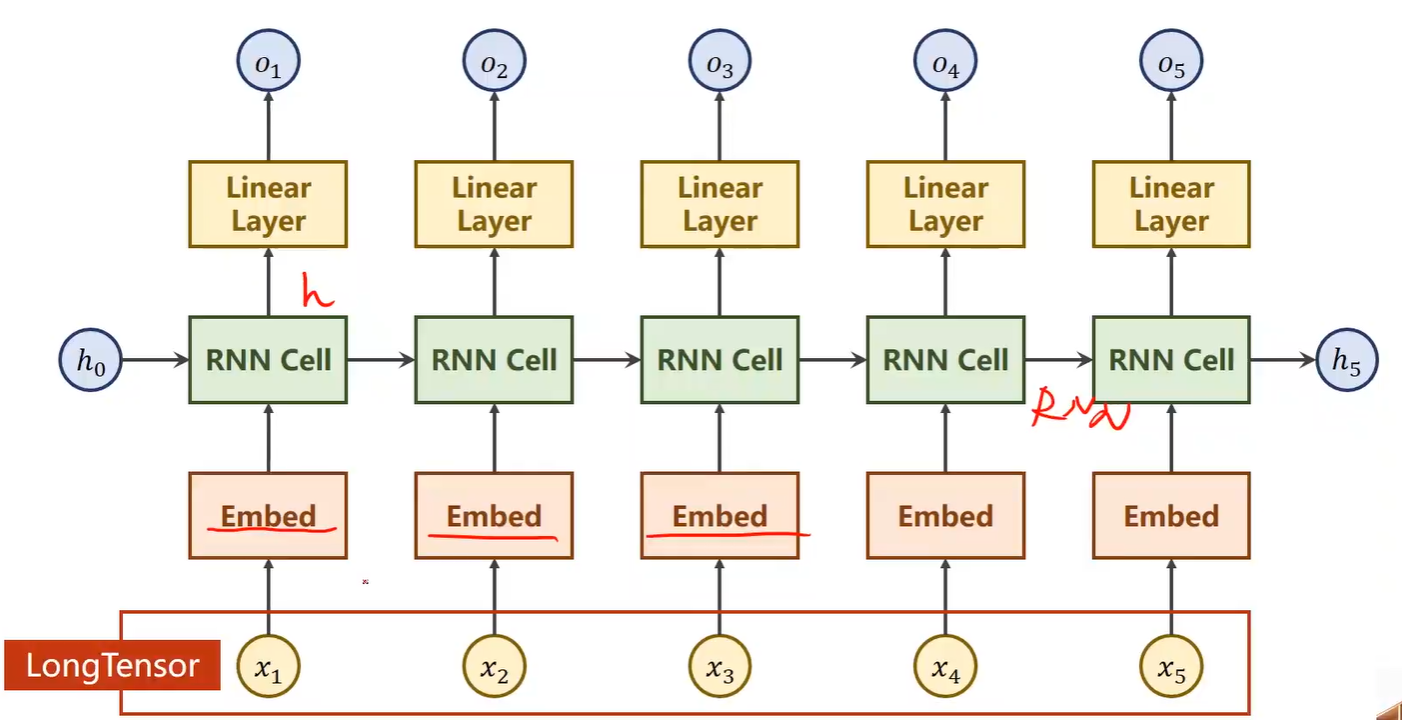
2.1 Embedding

Embedding参数说明
①num_embedding:输入的独热向量的维度
②embedding_dim:转换成词嵌入的维度
输入、输出
③输入必须是LongTensor类型
④输出时为为数据增加一个维度(embedding_dim)

2.2线性层 Linear

输入和输出的第一个维度(Batch)一直到倒数第二个维度都会保持不变。但会对最后一个维度(in_features)做出改变(out_features)

2.3交叉熵 CrossEntropyLoss

# 增加词嵌入
import torch input_size = 4
num_class = 4
hidden_size = 8
embedding_size =10
batch_size = 1
num_layers = 2
seq_len = 5 idx2char_1 = ['e', 'h', 'l', 'o']
idx2char_2 = ['h', 'l', 'o'] x_data = [[1, 0, 2, 2, 3]]
y_data = [3, 1, 2, 2, 3] #inputs 作为交叉熵中的Inputs,维度为(batchsize,seqLen)
inputs = torch.LongTensor(x_data)
#labels 作为交叉熵中的Target,维度为(batchsize*seqLen)
labels = torch.LongTensor(y_data) class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
#嵌入层
self .emb = torch.nn.Embedding(input_size, embedding_size) self.rnn = torch.nn.RNN(input_size = embedding_size,
hidden_size = hidden_size,
num_layers=num_layers,
batch_first = True) self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class) net = Model() criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05) for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs) loss = criterion(outputs, labels)
loss.backward()
optimizer.step() _, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted string: ',''.join([idx2char_1[x] for x in idx]), end = '')
print(", Epoch [%d/15] loss = %.3f" % (epoch+1, loss.item()))
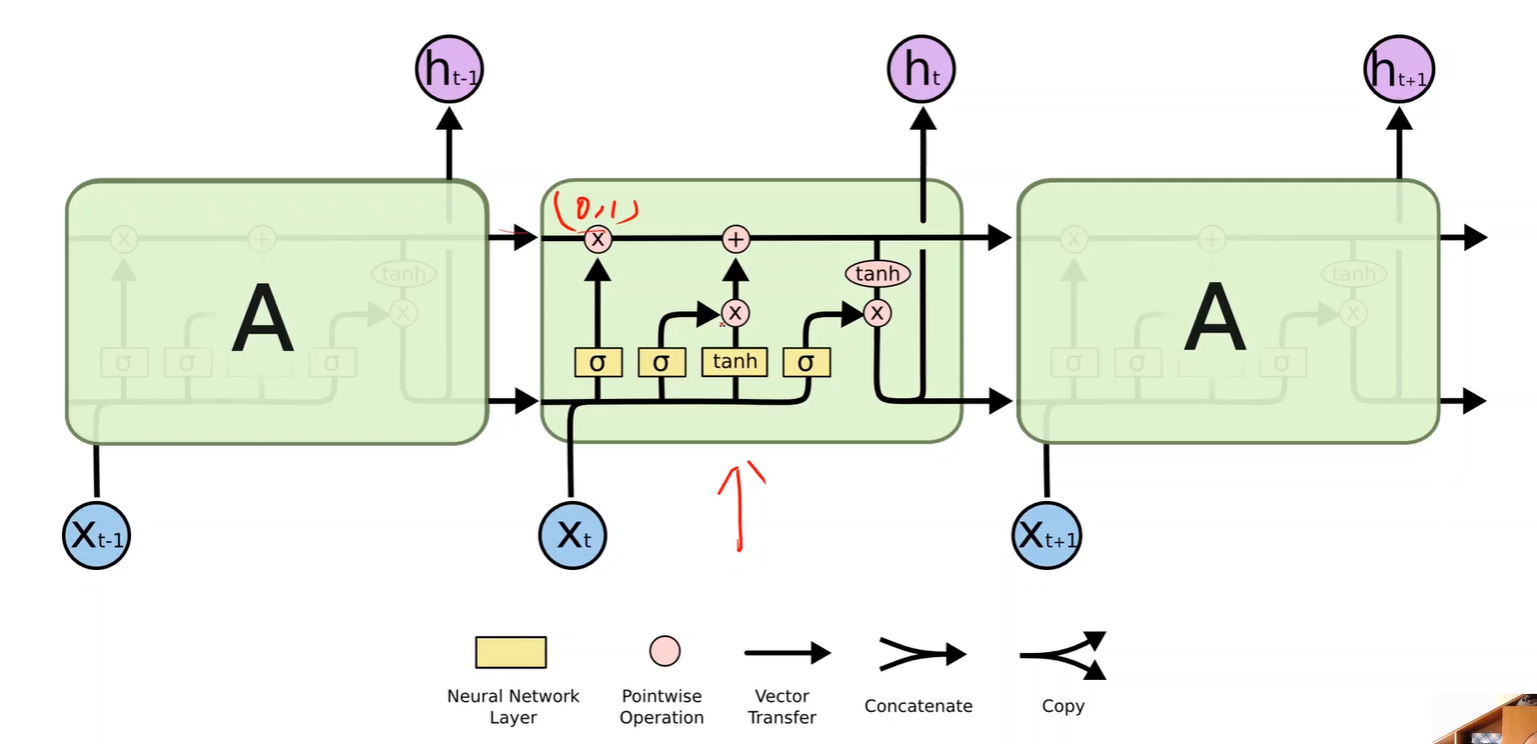
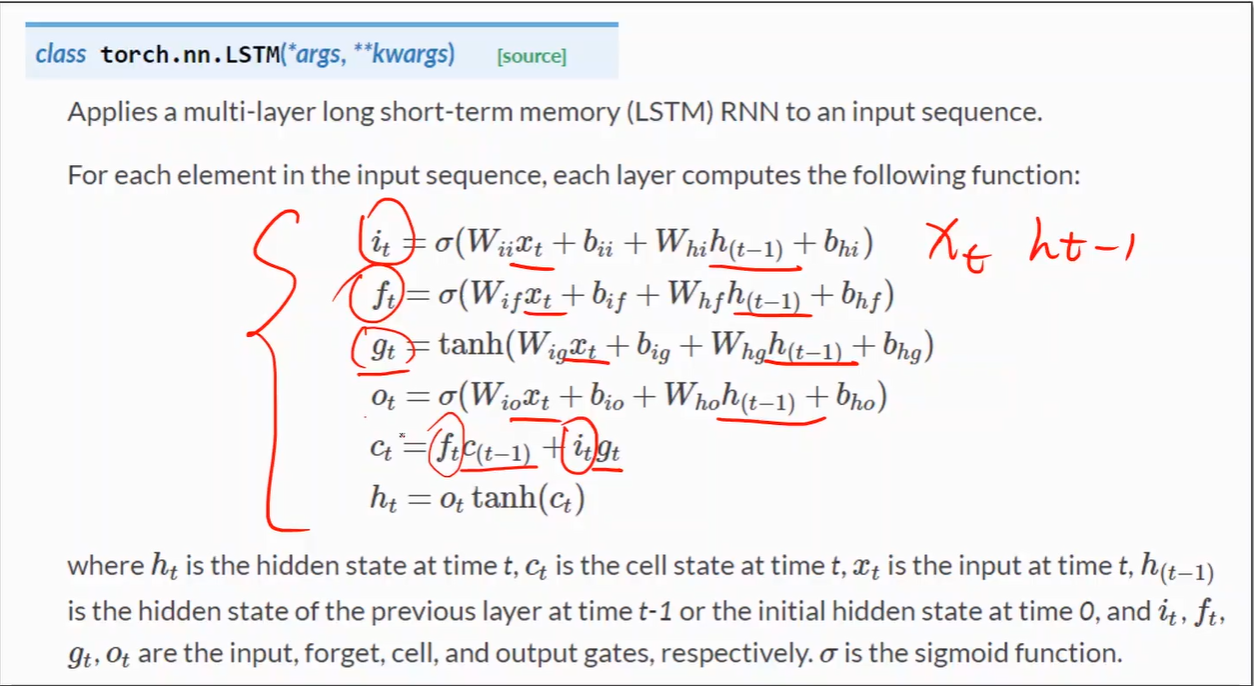
五、LSTM
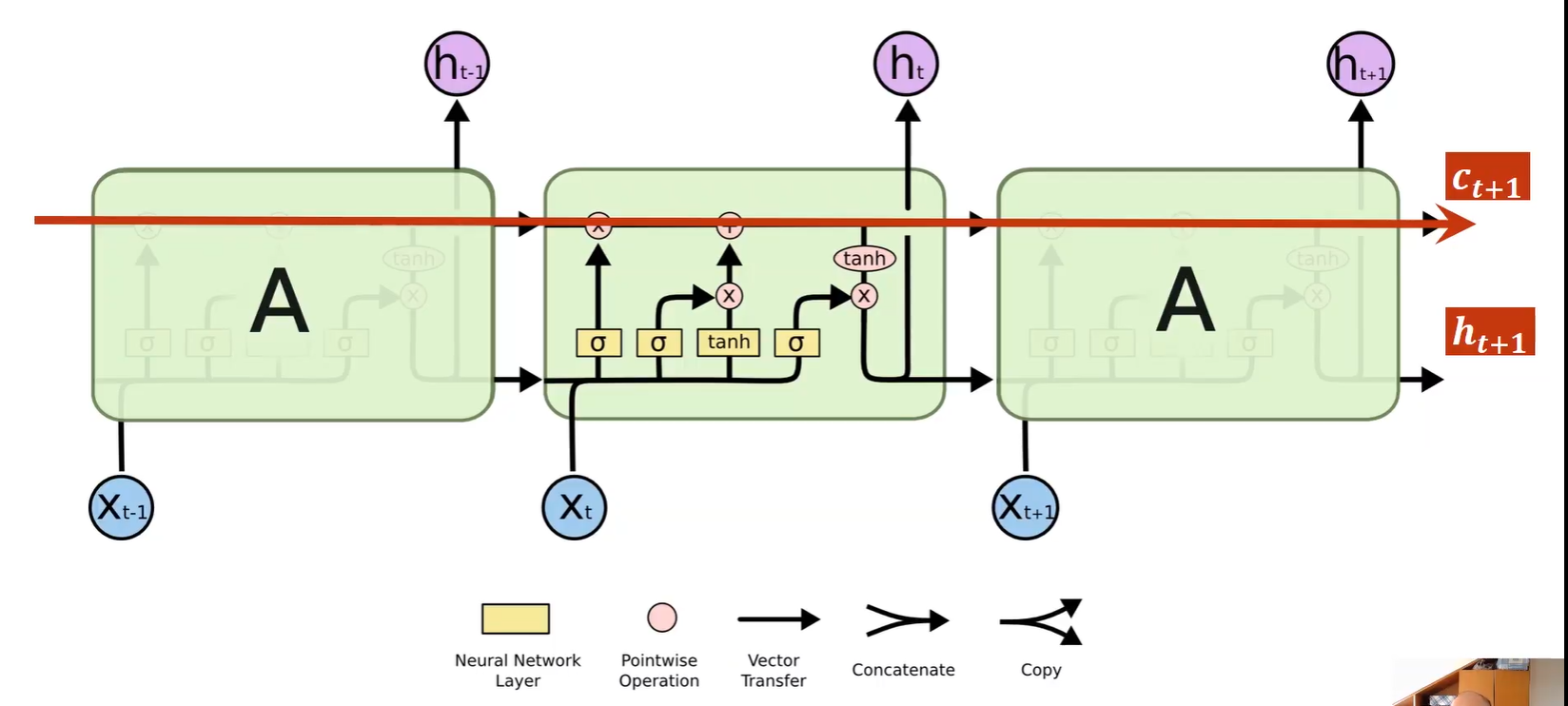
增加c_t+1的这条路径,在反向传播时,提供更快梯度下降的路径,减少梯度消失
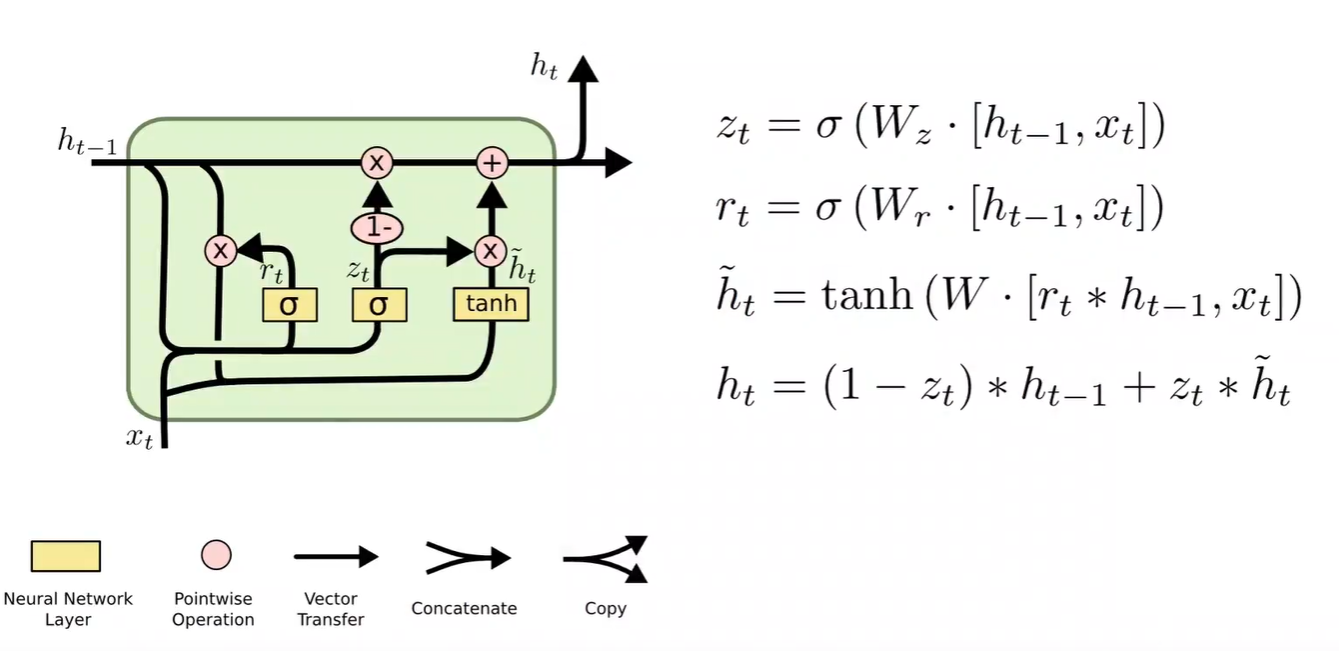
六、GRU
LSTM效果比RNN好得多,但由于计算复杂度上升,运算效率低,训练时间长
折中方法就可以选择 GRU
Pytorch实战学习(八):基础RNN的更多相关文章
- Java学习 (八)基础篇 运算符
目录 运算符 基本运算符 1.一元基础运算(重点) 一元运算符 (a++ / ++a) (a-- / --a) 2.二元基础运算 基础 计算返回值类型 关系运算 幂运算 3.三元运算符 4.逻辑运算符 ...
- 深度学习之PyTorch实战(1)——基础学习及搭建环境
最近在学习PyTorch框架,买了一本<深度学习之PyTorch实战计算机视觉>,从学习开始,小编会整理学习笔记,并博客记录,希望自己好好学完这本书,最后能熟练应用此框架. PyTorch ...
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 对比学习:《深度学习之Pytorch》《PyTorch深度学习实战》+代码
PyTorch是一个基于Python的深度学习平台,该平台简单易用上手快,从计算机视觉.自然语言处理再到强化学习,PyTorch的功能强大,支持PyTorch的工具包有用于自然语言处理的Allen N ...
- 参考《深度学习之PyTorch实战计算机视觉》PDF
计算机视觉.自然语言处理和语音识别是目前深度学习领域很热门的三大应用方向. 计算机视觉学习,推荐阅读<深度学习之PyTorch实战计算机视觉>.学到人工智能的基础概念及Python 编程技 ...
- 『深度应用』NLP机器翻译深度学习实战课程·壹(RNN base)
深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:(更新 ...
- 深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
上一篇博客先搭建了基础环境,并熟悉了基础知识,本节基于此,再进行深一步的学习. 接下来看看如何基于PyTorch深度学习框架用简单快捷的方式搭建出复杂的神经网络模型,同时让模型参数的优化方法趋于高效. ...
- Docker虚拟化实战学习——基础篇(转)
Docker虚拟化实战学习——基础篇 2018年05月26日 02:17:24 北纬34度停留 阅读数:773更多 个人分类: Docker Docker虚拟化实战和企业案例演练 深入剖析虚拟化技 ...
- Pytorch_第八篇_深度学习 (DeepLearning) 基础 [4]---欠拟合、过拟合与正则化
深度学习 (DeepLearning) 基础 [4]---欠拟合.过拟合与正则化 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [3]---梯度下降法" ...
- PyTorch 实战:计算 Wasserstein 距离
PyTorch 实战:计算 Wasserstein 距离 2019-09-23 18:42:56 This blog is copied from: https://mp.weixin.qq.com/ ...
随机推荐
- springboot集成ElasticApm
jvm参数方式: -javaagent:D:/codesoft/elastic-apm-agent-1.18.0.jar -Delastic.apm.service_name=my-applicati ...
- Grafana 系列文章(十三):如何用 Loki 收集查看 Kubernetes Events
前情提要 IoT 边缘集群基于 Kubernetes Events 的告警通知实现 IoT 边缘集群基于 Kubernetes Events 的告警通知实现(二):进一步配置 概述 在分析 K8S 集 ...
- 浅析 SeaweedFS 与 JuiceFS 架构异同
SeaweedFS 是一款高效的分布式文件存储系统,最早的设计原型参考了 Facebook 的 Haystack,具有快速读写小数据块的能力.本文将通过对比 SeaweedFS 与 JuiceFS 在 ...
- 力扣---511. 游戏玩法分析 I
活动表 Activity: +--------------+---------+| Column Name | Type |+--------------+---------+| player ...
- JAVA虚拟机-01-JAVA虚拟机家族简介
JAVA虚拟机家族简介 Classic VM JDK1.0发布,第一款商议的JAVA虚拟机.纯解释器方式来执行java代码的的JAVA虚拟机.如果要使用即时编译就需要外挂编译器.如果外挂了编译器,及时 ...
- 学习Java Day30
今天回顾了一下整章对象与类,对自己进行了查漏补缺,依旧存在许多知识点的掌握不充分,类的使用的不熟练,同志仍需努力,革命尚未成功.
- java2022.7.9
知识点
- 乌卡时代的云成本管理:从0到1了解FinOps
在上一篇文章中,我们介绍了企业云业务的成本构成以及目前面临的成本困境,以及当前企业逐步转向 FinOps 的行业趋势,这篇文章我们将详细聊聊 FinOps,包括概念.重要性以及成熟度评价指标. 随着对 ...
- 51nod 1675.序列变换
序列变换 题目描述 \(lyk\) 有两序列 \(a\) 和 \(b\). \(lyk\) 想知道存在多少对 \(x,y\),满足以下两个条件. \(1:\gcd(x,y)=1\). \(2:a_{b ...
- 解析关于Tomcat Servlet-request的获取请求参数及几种常用方法
摘要:本文主要讲解Tomcat之Servlet-request请求参数.Servlet转发机制.常用方法 本文分享自华为云社区<浅谈Tomcat之Servlet-request获取请求参数及常用 ...