Scrapy爬虫框架快速入门
安装scrapy
pip install scrapy -i https://pypi.douban.com/simple/
安装过程可能遇到的问题
- 版本问题导致一些辅助库没有安装好,需要手动下载并安装一个辅助库Twisted
- 运行时候:ModuleNotFoundError: No module named 'attrs'
pip install attrs --upgrade - 运行时候:Loading "scrapy.core.downloader.handlers.http.HTTPDownload Handler" for scheme "https"
pip install pywin32
创建项目
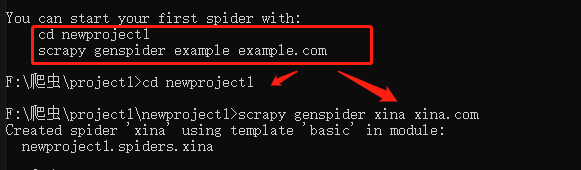
CMD进入需要创建项目的目录下,输入命令
scrapy startproject ×××

命令基本不需要死记硬背,正如下图所示,会告诉你接下来需要输入的命令
设置实体文件(建立要获取的字段)
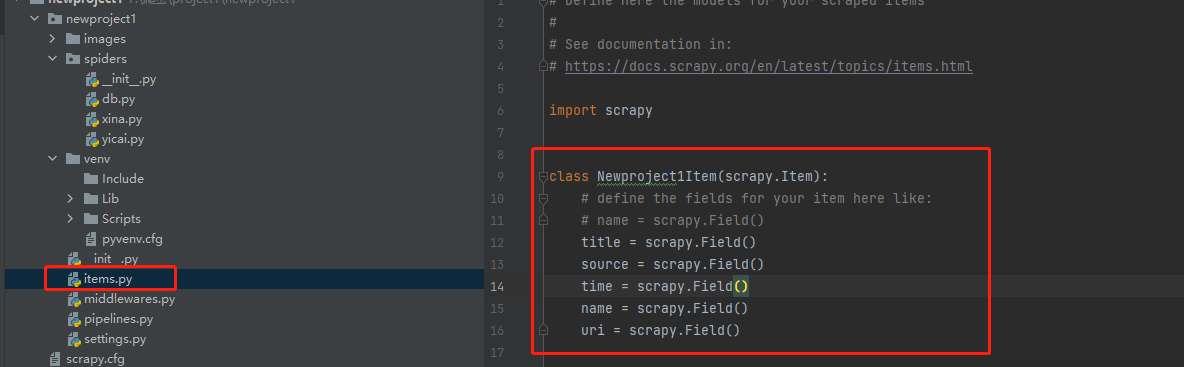
这个文件内会写入后续需要爬取的字段,scrapy.Field()就是变量存储区域,通过“spiders”里的爬虫文件获取的内容都会存储在此处设置的区域里。
然后以实体文件作为中转站,将这些变量传输到其他文件中,例如,传输到管道文件中进行数据存储等处理。设置完实体文件,就可以在实战中应用刚才创建的变量了。
修改设置文件(设置Robots协议和User-Agent,激活管道文件)
运行爬取文件可能会遇到DEBUG:Forbidden by robots txt 说明百度的Robots协议禁止Scrapy框架直接爬取。
解决这个问题可以通过设置文件20行左右的位置把OBEY置为False

设置User-Agent同样在设置文件40行左右位置,添加一行User-Agent

要进行数据的爬后处理,即将数据写入数据库或文件等后续操作。所以先要激活管道
后面的数字只是排序的顺序,越小越靠前
如果管道文件有新增类名,就需要在这里添加

在文件夹“spiders”中编写爬虫逻辑(核心爬虫代码)
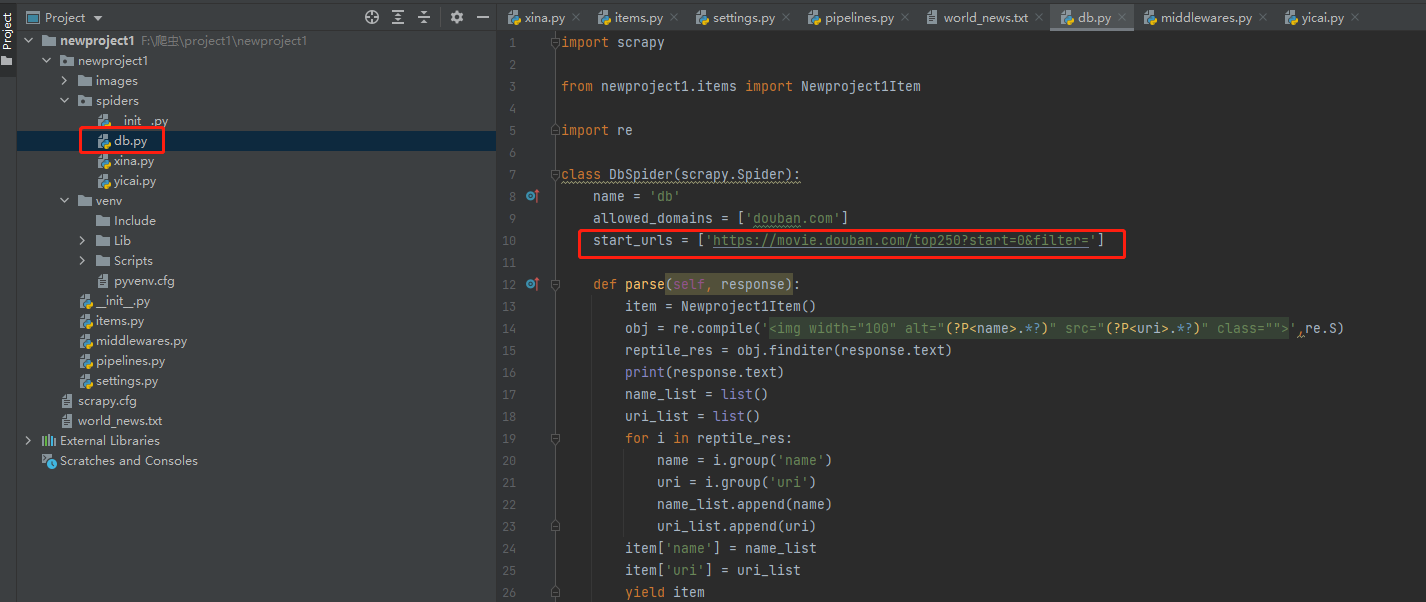
第10 行start_urls是一个列表存放需要爬取的url,如果需要爬取多个地址(例如存在ajex动态页面爬取),可以往这个start_urls列表中append多个地址
爬虫代码基本都在parse中
第13行实例化items,就是实例化需要提取的字段
后面几行都是基本的爬虫代码这里就解释了,需要说一下的是response.text才是网页源代码
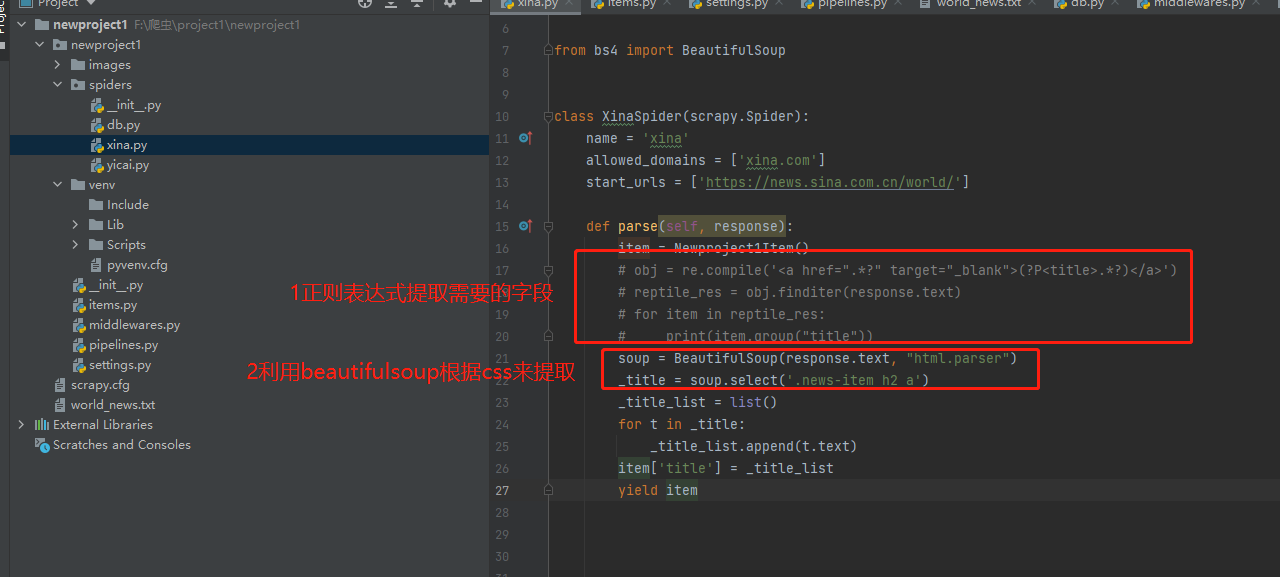
注:除了常见的用正则表达式提取,还有一个库比较常见就是Beautifulsoup
设置管道文件(爬后处理)
爬取后需要存入文件或者下载文件
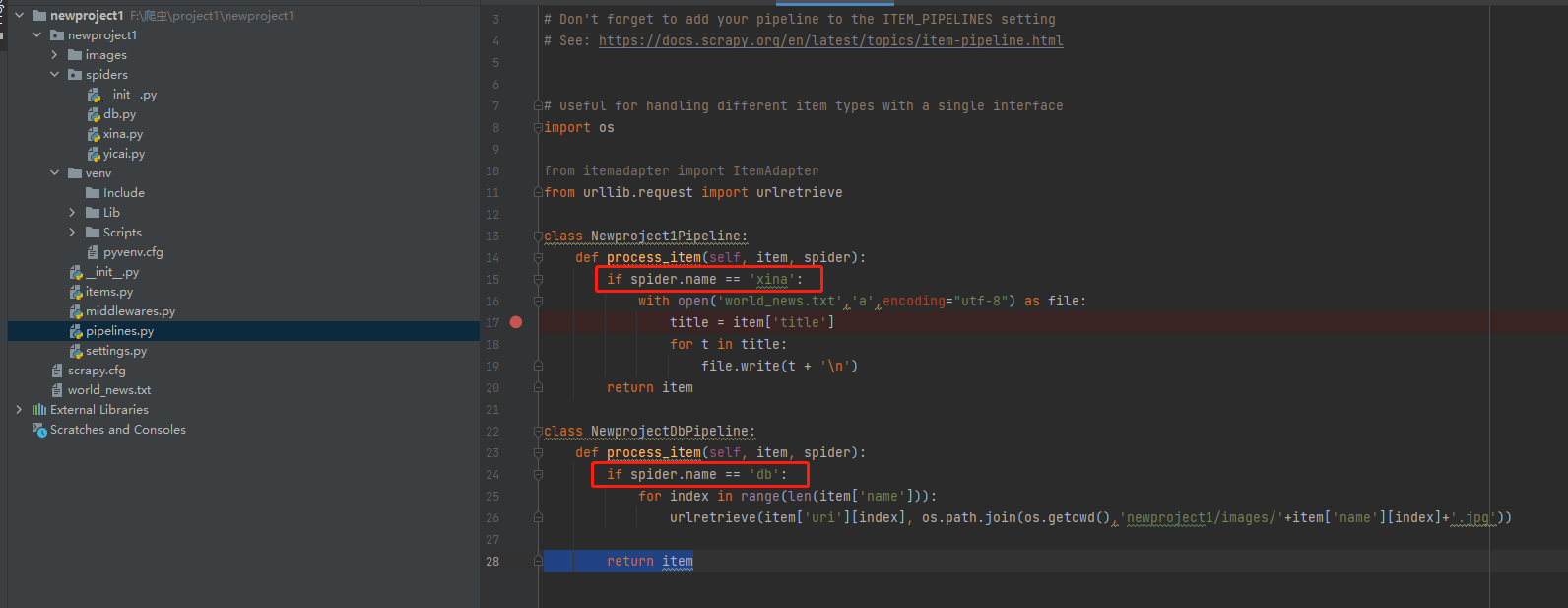
这里需要说一下,第15行和第24行去判断spider.name是为了在运行的时候进行区分。
当然写管道的时候,可以把所有处理方式写在一个类中,通过spider.name去进行区分,也可以像下图一样用不同的类去写。但如果是不同的类就需要到设置文件中把新增类添加到设置中去。
第26行urlretrieve()函数是用来下载图片
最后运行
最后在命令行输入
scrapy crawl ****
Scrapy爬虫框架快速入门的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
随机推荐
- Debian安装 WineHQ 安装包
https://wiki.winehq.org/Debian_zhcn WineHQ 源仓库的密钥于 2018-12-19 改变过.如果您在此之前下载添加过该密钥,您需要重新下载和添加新的密钥并运行 ...
- LoadRunner11脚本小技能之添加请求头+定义变量+响应内容乱码转换打印+事务拆分
一.添加请求头 存在一些接口,发送请求时需要进行权限验证.登录验证(不加请求头时运行脚本,接口可能会报401等等),所以需要在脚本中给对应请求添加请求头.注意:请求头需在请求前添加,包含url类.su ...
- ubuntu20.04修改静态ip不生效问题
一.前言 最近从头开始配置hadoop的时候,由于想切换到NAT模式下配置hadoop,但在修改ip的时候发现设置了静态ip,但ip不生效,查了很多资料,发现由于配置信息写错了. 二.解决问题 ifc ...
- 2022极端高温!机器学习如何预测森林火灾?⛵ 万物AI
作者:ShowMeAI编辑部 声明:版权所有,转载请联系平台与作者并注明出处 收藏ShowMeAI查看更多精彩内容 今年夏天,重庆北碚区山火一路向国家级自然保护区缙云山方向蔓延.为守护家园,数万名重庆 ...
- HDLBits答案——Verification: Reading Simulations
1 Finding bugs in code 1.1 Bugs mux2 module top_module ( input sel, input [7:0] a, input [7:0] b, ou ...
- AArch32/AArch64应用程序级内存模型(五)
本文主要为了记录在学习armv8的过程中的一些感悟.由于原文部分章节晦涩难懂,作者参考了网上很多优秀博主的部分章节(可能是直接摘录)并结合自己的理解重新整理了当前这个版本.文中不免有部分章节讲解很浅, ...
- Guess Next Session
打开又是一个输入框的界面,点一下下面的看源码 很简短的一个源码 大概意思是如果password等于session[password]就输出flag 直接搜了下session函数的漏洞,发现sessio ...
- uni 结合vuex 编写动态全局配置变量 this.baseurl
在日常开发过程,相信大家有遇到过各种需求,而我,在这段事件便遇到了一个,需要通过用户界面配置动态接口,同时,因为是app小程序开发,所以接口中涉及到了http以及websocket两个类型的接口. 同 ...
- 【消息队列面试】15-17:高性能和高吞吐、pull和push、各种MQ的区别
十五.kafka高性能.高吞吐的原因 1.应用 日志收集(高频率.数据量大) 2.如何保证 (1)磁盘的顺序读写-pagecache关联 rabbitmq基于内存读写,而kafka基于磁盘读写,但却拥 ...
- python装饰器初级
global与nonlocal 1.global的作用: 可以在局部空间里直接就该全局名称工具中的数据 代码展示: name = 'moon' #设置了一个全局变量 def fucn(): name ...