Scrapy爬虫框架快速入门
安装scrapy
pip install scrapy -i https://pypi.douban.com/simple/
安装过程可能遇到的问题
- 版本问题导致一些辅助库没有安装好,需要手动下载并安装一个辅助库Twisted
- 运行时候:ModuleNotFoundError: No module named 'attrs'
pip install attrs --upgrade - 运行时候:Loading "scrapy.core.downloader.handlers.http.HTTPDownload Handler" for scheme "https"
pip install pywin32
创建项目
CMD进入需要创建项目的目录下,输入命令
scrapy startproject ×××

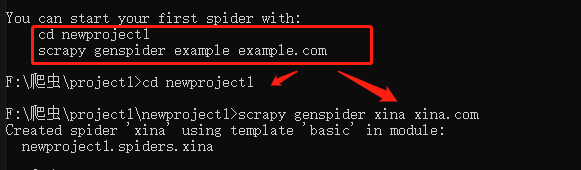
命令基本不需要死记硬背,正如下图所示,会告诉你接下来需要输入的命令
设置实体文件(建立要获取的字段)
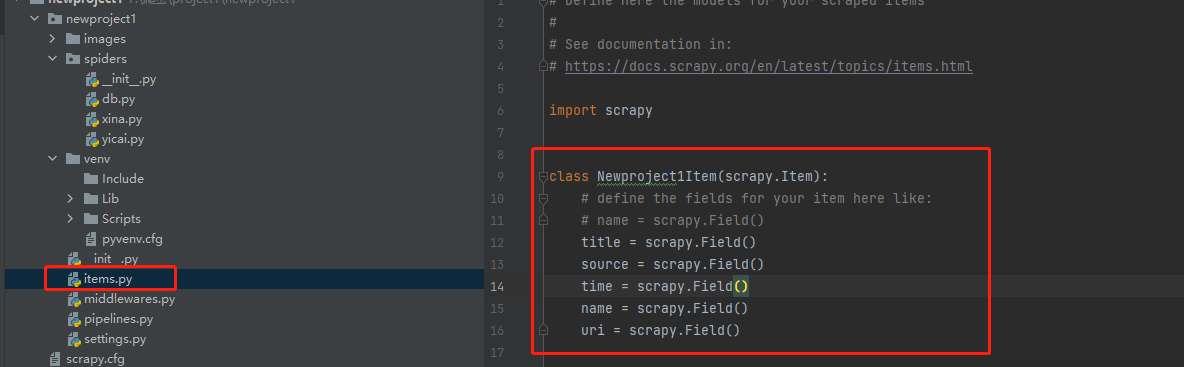
这个文件内会写入后续需要爬取的字段,scrapy.Field()就是变量存储区域,通过“spiders”里的爬虫文件获取的内容都会存储在此处设置的区域里。
然后以实体文件作为中转站,将这些变量传输到其他文件中,例如,传输到管道文件中进行数据存储等处理。设置完实体文件,就可以在实战中应用刚才创建的变量了。
修改设置文件(设置Robots协议和User-Agent,激活管道文件)
运行爬取文件可能会遇到DEBUG:Forbidden by robots txt 说明百度的Robots协议禁止Scrapy框架直接爬取。
解决这个问题可以通过设置文件20行左右的位置把OBEY置为False

设置User-Agent同样在设置文件40行左右位置,添加一行User-Agent

要进行数据的爬后处理,即将数据写入数据库或文件等后续操作。所以先要激活管道
后面的数字只是排序的顺序,越小越靠前
如果管道文件有新增类名,就需要在这里添加

在文件夹“spiders”中编写爬虫逻辑(核心爬虫代码)
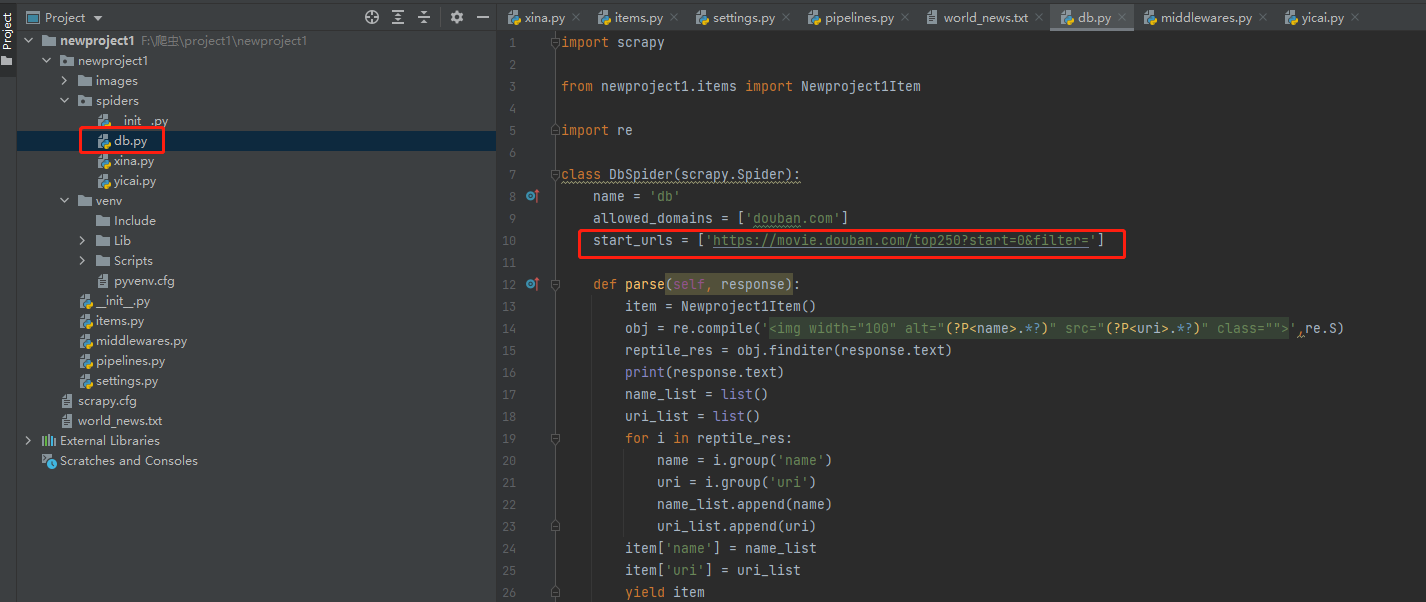
第10 行start_urls是一个列表存放需要爬取的url,如果需要爬取多个地址(例如存在ajex动态页面爬取),可以往这个start_urls列表中append多个地址
爬虫代码基本都在parse中
第13行实例化items,就是实例化需要提取的字段
后面几行都是基本的爬虫代码这里就解释了,需要说一下的是response.text才是网页源代码
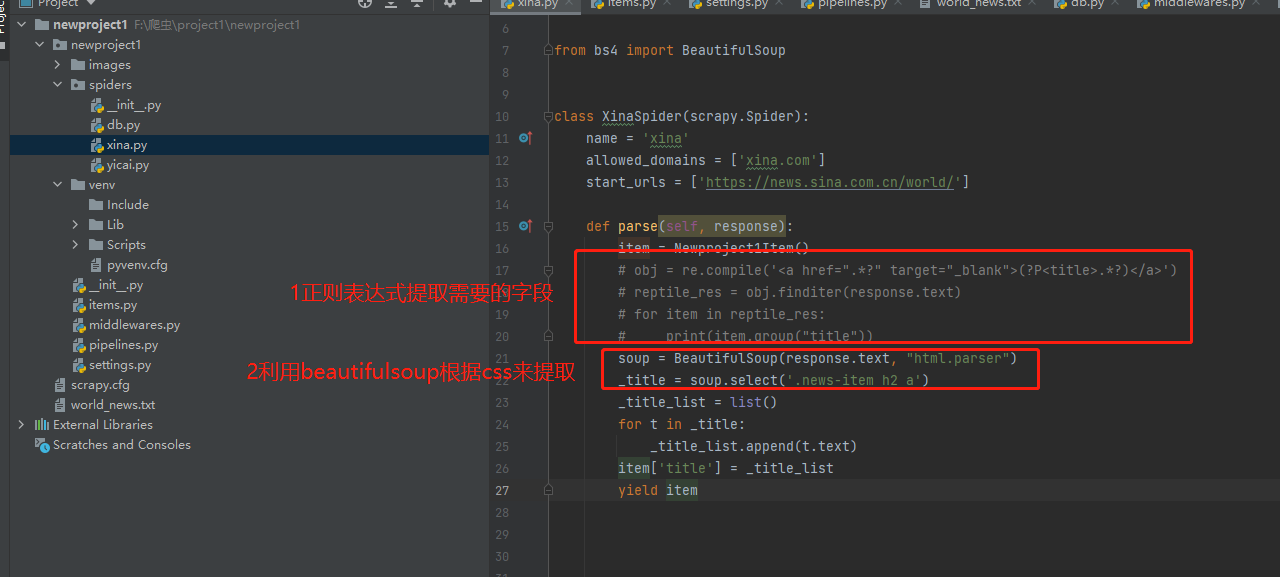
注:除了常见的用正则表达式提取,还有一个库比较常见就是Beautifulsoup
设置管道文件(爬后处理)
爬取后需要存入文件或者下载文件
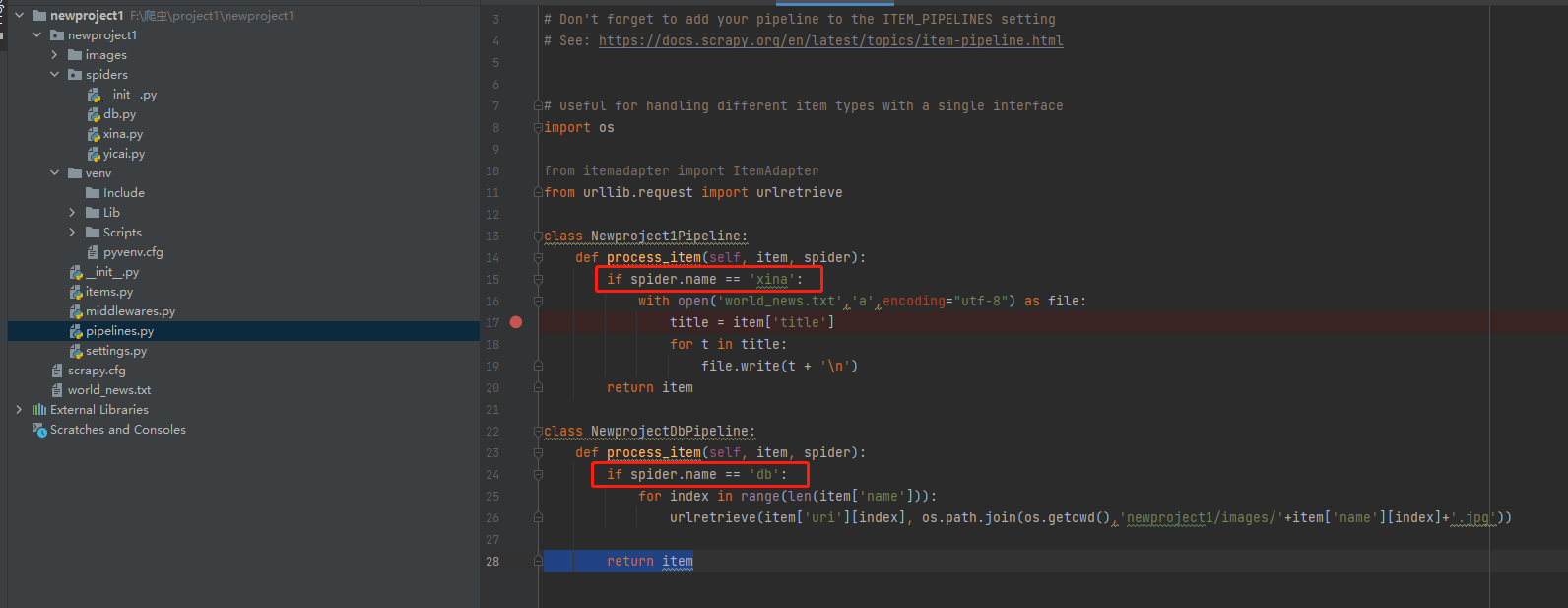
这里需要说一下,第15行和第24行去判断spider.name是为了在运行的时候进行区分。
当然写管道的时候,可以把所有处理方式写在一个类中,通过spider.name去进行区分,也可以像下图一样用不同的类去写。但如果是不同的类就需要到设置文件中把新增类添加到设置中去。
第26行urlretrieve()函数是用来下载图片
最后运行
最后在命令行输入
scrapy crawl ****
Scrapy爬虫框架快速入门的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
随机推荐
- win10本地python第三方库安装成功,但是pycharm项目无法使用解决方案
一.背景win10本地python第三方库安装成功,但是pycharm项目无法使用解决方案如本地安装的python中的request库,在pycharm项目中居然无法使用,比较郁闷 pip list ...
- faker
faker是一个生成伪造数据的Python第三方库,可以伪造城市,姓名,文班等各自信息,而且支持中文 安装 pip3 install faker 使用 # 导包 from faker impo ...
- 25.自定义mixin和基类
很多时候业务需求并不是几个简单的mixin就可以满足,需要我们自定义mixin # get_object源码中字段查询源代码 filter_kwargs = {self.lookup_field: s ...
- VMware Fusion配置NAT静态IP
前言 本主机 CentOS8.2 Mac VMware Fusion 我们在使用虚拟机的时候,经常遇到这样的问题,我们会换地方,IP 会变化,如果虚拟机使用桥接的方式,那么很多与 IP 相关的服务都会 ...
- 微信DAT文件解密(dat转图像)
微信电脑版现在已经是日常工作生活必不可少的工具,有时候删除了聊天记录或者被系统清理软件清理了,但还想查看曾经的微信聊天图片. 这个时候辛辛苦苦找到了文件,却发现无法查看,因为微信电脑版为了保护我们的隐 ...
- Go语言核心36讲25
你好,我是郝林,今天我分享的主题是:测试的基本规则和流程(上). 你很棒,已经学完了本专栏最大的一个模块!这涉及了Go语言的所有内建数据类型,以及非常有特色的那些流程和语句. 你已经完全可以去独立编写 ...
- 读书笔记《A Philosophy of Software Design - John Ousterhout 软件设计哲学》
软件设计哲学这本书很薄,值得一读.这本书将大家平时碰到的很多软件问题从更深刻的层面进行了抽象分析,同时又给出了具体的解决方案.可以说既有理论高度,又能贴近实践. 但针对软件问题,这本书并没有提出太多与 ...
- springBoot 过滤器去除请求参数前后空格(附源码)
背景 : 用户在前端页面中不小心输入的前后空格,为了防止因为前后空格原因引起业务异常,所以我们需要去除参数的前后空格! 如果我们手动去除参数前后空格,我们可以这样做 @GetMapping(value ...
- Visual Studio高版本 ArcObject for .Net 低版本
在基于ArcGIS的开发中,经常会存在Visual Studio版本高,ArcObject for .Net 版本低的问题.例如Visual Studio 2015的环境下,安装ArcObject f ...
- day02 数据类型 & 运算符
day02 数据类型 基本数据类型 共有四类八种 1)整数类型 byte short int long byte: 字节 bit比特,1bit = 1二进制位 ,byte占8位 [-128,128 ...