2003031126-石升福-Python数据分析-五一假期作业
| 项目 | 内容 |
| 班级链接 | 20级数据班(本) |
| 作业链接 | 五一假期作业 |
| 博客名称 | 2003031126-石升福-Python数据分析-五一假期作业 |
| 要求 | 每道题要有题目,代码(使用插入代码,不会插入代码的自己查资料解决,不要直接截图代码!!),截图(只截运行结果)。 |
作业:把期中考试代码看懂、运行并调通,要求每一行 或 每个重要功能写上注释。
1.
分析1996~2015年人口数据特征间的关系
考查知识点:掌握pyplot常用的绘图参数的调节方法;掌握子图的绘制方法;掌握绘制图形的保存与展示方法;掌握散点图和折线图的作用与绘制方法。
需求说明:
人口数据总共拥有6个特征,分别为年末总人口、男性人口、女性人口、城镇人口、乡村人口和年份。查看各个特征随着时间推移发生的变化情况可以分析出未来男女人口比例、城乡人口变化的方向。
截图如下:
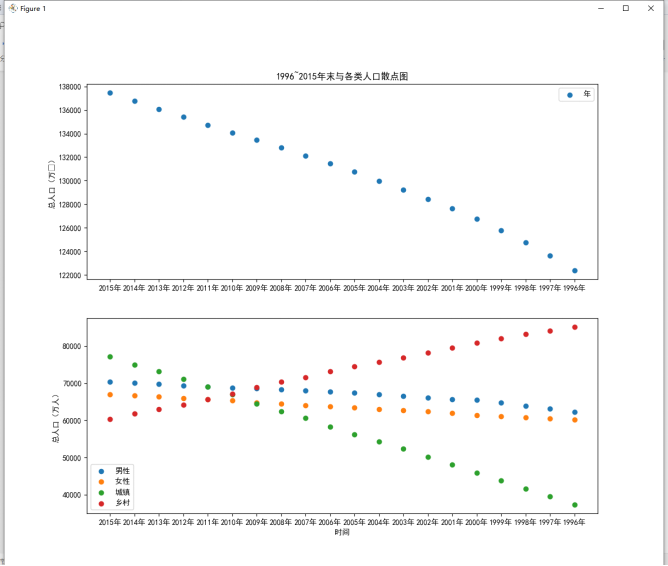

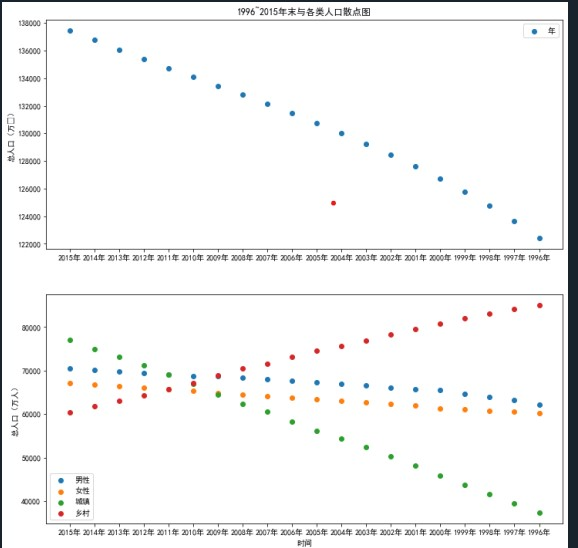
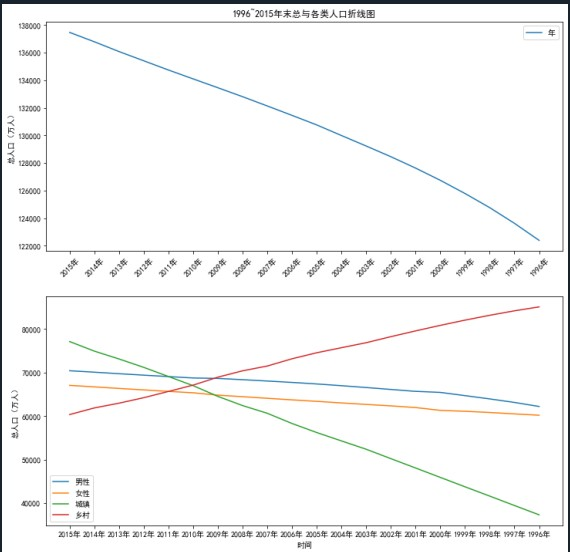
要求:
(1)使用NumPy库读取人口数据。
(2)创建画布,并添加子图。
(3)在两个子图上分别绘制散点图和折线图。
(4)保存,显示图片。
(5)分析未来人口变化趋势
1 import pandas as pd;
2 import numpy as np
3 from sqlalchemy import create_engine
4 engine = create_engine('mysql+pymysql://root:root@127.0.0.1:\3306/testdb?charset=tuf8')
5 detail = pd.read_sql_table('Training_Userupdate',con = engine)
6
7 print('维度',detial.ndim)
8 print('',detial.shape)
9 '''
10 '''
11 import numpy as np
12 import matplotlib.pyplot as plt
13 #使⽤numpy库读取⼈⼝数据
14 data=np.load('C:/Users/ASUS/Desktop/populations.npz',allow_pickle=True)
15 print(data.files)#查看⽂件中的数组
16 print(data['data'])
17 print(data['feature_names'])
18 plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
19 plt.rcParams['axes.unicode_minus'] = False# 防止字符无法显示
20 name=data['feature_names']#提取其中的feature_names数组,视为数据的标签
21 values=data['data']#提取其中的data数组,视为数据的存在位置
22 p1=plt.figure(figsize=(12,12))#确定画布⼤⼩
23 pip1=p1.add_subplot(2,1,1)#创建⼀个两⾏⼀列的⼦图并开始绘制
24 #在⼦图上绘制散点图
25 plt.scatter(values[0:20,0],values[0:20,1])#,marker='8',color='red'
26 plt.ylabel('总人口(万⼈)')
27 plt.legend('年末')
28 plt.title('1996~2015年末与各类人口散点图')
29 pip2=p1.add_subplot(2,1,2)#绘制⼦图2
30 plt.scatter(values[0:20,0],values[0:20,2])#,marker='o',color='yellow'
31 plt.scatter(values[0:20,0],values[0:20,3])#,marker='D',color='green'
32 plt.scatter(values[0:20,0],values[0:20,4])#,marker='p',color='blue'
33 plt.scatter(values[0:20,0],values[0:20,5])#,marker='s',color='purple'
34 plt.xlabel('时间')
35 plt.ylabel('总人口(万人)')
36 plt.xticks(values[0:20,0])
37 plt.legend(['男性','女性','城镇','乡村'])
38 #在⼦图上绘制折线图
39 p2=plt.figure(figsize=(12,12))
40 p1=p2.add_subplot(2,1,1)
41 plt.plot(values[0:20,0],values[0:20,1])#,linestyle = '-',color='r',marker='8'
42 plt.ylabel('总人口(万人)')
43 plt.xticks(range(0,20,1),values[range(0,20,1),0],rotation=45)#rotation设置倾斜度
44 plt.legend('年末')
45 plt.title('1996~2015年末总与各类人口折线图')
46 p2=p2.add_subplot(2,1,2)
47 plt.plot(values[0:20,0],values[0:20,2])#,'y-'
48 plt.plot(values[0:20,0],values[0:20,3])#,'g-.'
49 plt.plot(values[0:20,0],values[0:20,4])#,'b-'
50 plt.plot(values[0:20,0],values[0:20,5])#,'p-'
51 plt.xlabel('时间')
52 plt.ylabel('总人口(万人)')
53 plt.xticks(values[0:20,0])
54 plt.legend(['男性','女性','城镇','乡村'])
55 #显⽰图⽚
56 plt.show()
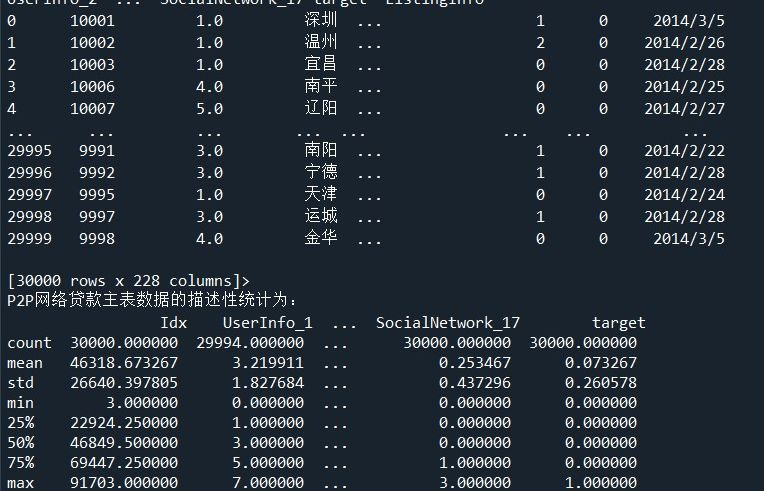
2.读取并查看P2P网络贷款数据主表的基本信息
考查知识点:掌握常见的数据读取方式;掌握DataFrame常用属性与方法;掌握基础时间数据处理方法;掌握分组聚合的原理与方法;掌握透视表与交叉表的制作。
需求说明:
P2P贷款主表数据主要存放了网贷用户的基本信息。探索数据的基本信息,能够洞察数据的整体分布、数据的类属关系、从而发现数据间的关联。
要求:
(1)使用ndim、shape、memory_usage属性分别查看维度、大小、占用内存信息。
1 import pandas as pd
2 master = pd.read_csv('C:/Users/Desktop/Training_Master.csv',encoding='gbk')#读取文件数据
3 print('P2P网络贷款主表数据的维度为:',master.ndim)
4 print('P2P网络贷款主表数据的形状大小为:',master.shape)
5 print('P2P网络贷款主表数据的占用内存为:',master.memory_usage)
6 print('P2P网络贷款主表数据的描述性统计为:\n',master.describe())
3.提取用户信息更新表和登录信息表的时间信息
考查知识点:掌握常见的数据读取方式;掌握DataFrame常用属性与方法;掌握基础时间数据处理方法;掌握分组聚合的原理与方法;掌握透视表与交叉表的制作。
需求说明:
用户信息更新表和登录信息表汇总均存在大量的时间数据,提取时间数据内存在的信息,一方面可以加深对数据的理解,另一方面能够探索这部分信息和目标的关联程度。同时用户登录时间、借款成交时间、用户信息更新时间这些时间的时间差信息冶能反映出P2P网络贷款不同用户的行为信息。
要求:
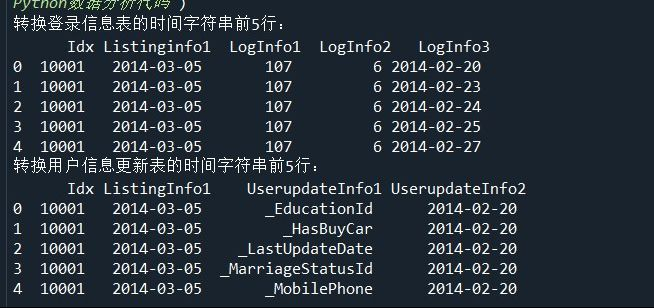
(1)使用to_datetime函数转换用户信息更新表和登录信息表的时间字符串。
import pandas as pd
#读取文件
LogInfo = pd.read_csv('D:/Users/ASUS/Desktop/Training_LogInfo(1).csv',encoding='gbk')
Userupdate = pd.read_csv('D:/Users/ASUS/Desktop/Training_Userupdate.csv',encoding='gbk')
# 转换时间字符串
LogInfo['Listinginfo1']=pd.to_datetime(LogInfo['Listinginfo1'])
LogInfo['LogInfo3']=pd.to_datetime(LogInfo['LogInfo3'])
print('转换登录信息表的时间字符串前5行:\n',LogInfo.head())
Userupdate['ListingInfo1']=pd.to_datetime(Userupdate['ListingInfo1'])
Userupdate['UserupdateInfo2']=pd.to_datetime(Userupdate['UserupdateInfo2'])
print('转换用户信息更新表的时间字符串前5行:\n',Userupdate.head())
4.使用分组聚合方法进一步分析用户信息更新表和登录信息表(1题30分,共30分)
考查知识点:掌握常见的数据读取方式;掌握DataFrame常用属性与方法;掌握基础时间数据处理方法;掌握分组聚合的原理与方法;掌握透视表与交叉表的制作。
需求说明:
分析用户信息更新表和登录信息表时,除了提取时间本身的信息外,还可以结合用户编号进行分组聚合,然后进行组内分析。通过组内分析可以得出每组组内的最早和最晚信息更新时间、最早和最晚登录时间、信息更新的次数、登录的次数等信息。
要求:
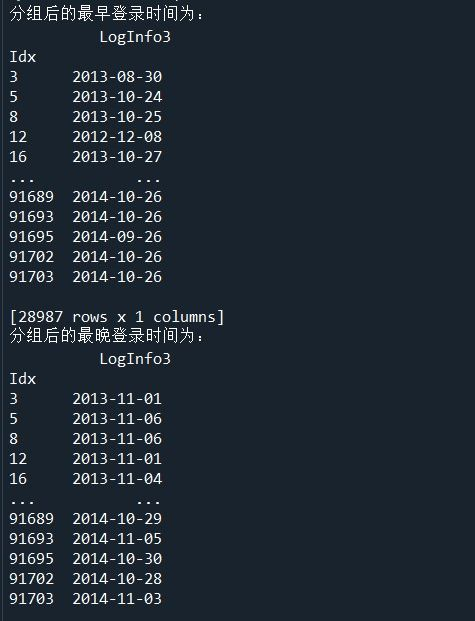
(1)使用groupby方法对用户信息更新表和登录信息表进行分组。
(2)使用agg方法求取分组后的最早和最晚更新及登录时间。
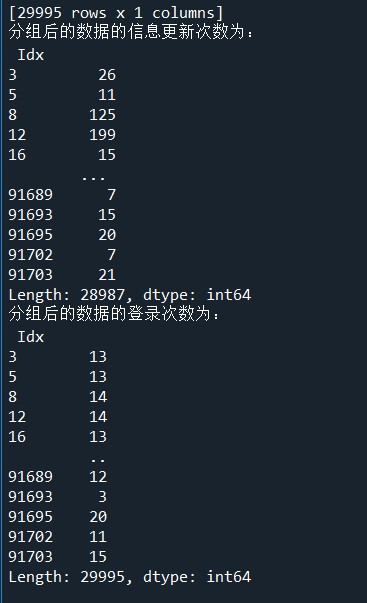
(3)使用size方法求取分组后的数据的信息更新次数与登录次数。
import pandas as pd
import numpy as np
LogInfo = pd.read_csv('D:/Users/ASUS/Desktop/Training_LogInfo(1).csv',encoding='gbk')
Userupdate = pd.read_csv('D:/Users/ASUS/Desktop/Training_Userupdate.csv',encoding='gbk')
# 使用groupby方法对用户信息更新表和登录信息表进行分组
LogGroup = LogInfo[['Idx','LogInfo3']].groupby(by = 'Idx')
UserGroup = Userupdate[['Idx','UserupdateInfo2']].groupby(by = 'Idx') # 使用agg方法求取分组后的最早,最晚,更新登录时间
print('分组后的最早登录时间为:\n',LogGroup.agg(np.min))
print('分组后的最晚登录时间为:\n',LogGroup.agg(np.max))
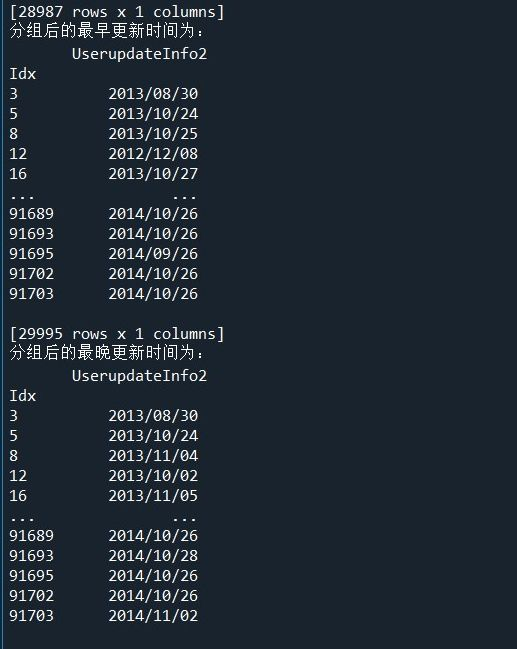
print('分组后的最早更新时间为:\n',UserGroup.agg(np.min))
print('分组后的最晚更新时间为:\n',UserGroup.agg(np.max)) # 使用size方法求取分组后的数据的信息更新次数与登录次数
print('分组后的数据的信息更新次数为:\n',LogGroup.size())
print('分组后的数据的登录次数为:\n',UserGroup.size())
2003031126-石升福-Python数据分析-五一假期作业的更多相关文章
- 2003031121-浦娟-python数据分析五一假期作业
项目 内容 课程班级博客链接 20级数据班(本) 这个作业要求链接 Python作业 博客名称 2003031121-浦娟-python数据分析五一假期作业 要求 每道题要有题目,代码(使用插入代码, ...
- 2003031121-浦娟-python数据分析第四周作业-第二次作业
项目 内容 课程班级博客链接 20级数据班(本) 作业链接 Python第四周作业第二次作业 博客名称 2003031121-浦娟-python数据分析第四周作业-matolotlib的应用 要求 每 ...
- Python数据分析(二): Numpy技巧 (2/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
- Python数据分析(二): Numpy技巧 (3/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
- python数据分析中常用的库
Python是数据处理常用工具,可以处理数量级从几K至几T不等的数据,具有较高的开发效率和可维护性,还具有较强的通用性和跨平台性,这里就为大家分享几个不错的数据分析工具,需要的朋友可以参考下 Pyth ...
- Python数据分析之Pandas操作大全
从头到尾都是手码的,文中的所有示例也都是在Pycharm中运行过的,自己整理笔记的最大好处在于可以按照自己的思路来构建矿建,等到将来在需要的时候能够以最快的速度看懂并应用=_= 注:为方便表述,本章设 ...
- [Python数据分析]新股破板买入,赚钱几率如何?
这是本人一直比较好奇的问题,网上没搜到,最近在看python数据分析,正好自己动手做一下试试.作者对于python是零基础,需要从头学起. 在写本文时,作者也没有完成这个小分析目标,边学边做吧. == ...
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
- 【Python数据分析】Python3操作Excel(二) 一些问题的解决与优化
继上一篇[Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 对豆瓣图书Top250进行爬取以后,鉴于还有一些问题没有解决,所以进行了进一步的交流讨论,这期间得到了一只尼玛 ...
- 【搬砖】【Python数据分析】Pycharm中plot绘图不能显示出来
最近在看<Python数据分析>这本书,而自己写代码一直用的是Pycharm,在练习的时候就碰到了plot()绘图不能显示出来的问题.网上翻了一下找到知乎上一篇回答,试了一下好像不行,而且 ...
随机推荐
- 《ImageNet Classification with Deep Convolutional Neural Networks (AlexNet)2012》
Abstract 作者训练了一个大型的深度卷积神经网络,用于在 ImageNet LSVRC-2010 比赛中对120万张高分辨率图像分为1000个不同的类别.在测试数据上,作者们达到了 top-1 ...
- simlink物体仿真中连接scope
该模块用于连接scope和multibody仿真中物理模型的输出值.
- Flutter statecontroller.update(MaterialState.disabled,false)无效
因为中间会调用 void initStatesController() { if (widget.statesController == null) { internalStatesControlle ...
- 安装centos7 报错no controller found踩坑
安装centos7.9时出现如上报错,特记录解决方法: 1.查看硬盘 出现如上报错时,耐心等待,等错误提醒不断滚动时,一会出现命令行输入界面,输入命令: [root@localhost ~]# ls ...
- C语言-Windows定时关机小程序
整理文件发现以前写的定时关机小程序(Windows下) 1-效果 2-程序 #include <stdio.h> #include <stdlib.h> #include &l ...
- SAP 常见函数
*大小写转换 TRANSLATE STRING TO UPPER CASE. TRANSLATE STRING TO LOWER CASE. *前缀去零 CALL FUNCTION 'CONVERSI ...
- 2019-2020-1 20199318《Linux内核原理与分析》第九周作业
第8章 进程的切换和系统的一般执行过程 一.学习总结 Linux系统的一般执行过程: 最一般的情况:正在运行的用户态进程X切换到运行用户态进程Y的过程. (1)正在运行的用户态进程X; (2)发生中断 ...
- python对象的三要素
id() 函数返回对象的唯一标识符,标识符是一个整数. 返回值 :返回对象的内存地址. >>>a = 'runoob' >>> id(a) 4531887632 i ...
- js已知多边形坐标点,求多边形的中心点坐标
你需要传入的数据类型如下: // 取面对象 中心点 var calculateCenter = function (lnglatarr) { var total = lnglatarr.length; ...
- TypeScript Map 对象
TypeScript Map 对象 Map 对象保存键值对,并且能够记住键的原始插入顺序. 任何值(对象或者原始值) 都可以作为一个键或一个值. Map 是 ES6 中引入的一种新的数据结构,可以参考 ...