Python爬虫教程-24-数据提取-BeautifulSoup4(二)
Python爬虫教程-24-数据提取-BeautifulSoup4(二)
本篇介绍 bs 如何遍历一个文档对象
遍历文档对象
- contents:tag 的子节点以列表的方式输出
- children:子节点以迭代器形式返回
- descendants:所有子孙节点
- string:用string打印出标签的具体内容,不带有标签,只有内容
- 案例代码27bs3.py文件:https://xpwi.github.io/py/py爬虫/py27bs3.py
# BeautifulSoup 的使用案例
# 遍历文档对象
from urllib import request
from bs4 import BeautifulSoup
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
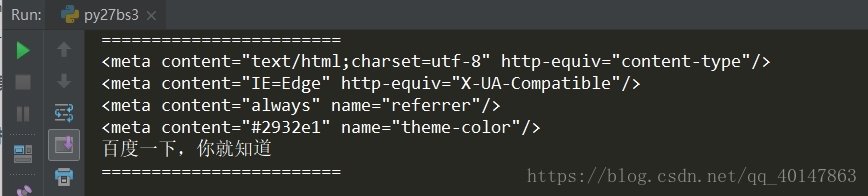
print("=="*12)
# 使用 contents
for node in soup.head.contents:
if node.name == "meta":
print(node)
if node.name == "title":
print(node.string)
print("=="*12)
运行结果
常用string打印出标签的具体内容,不带有标签,只有内容
当然,如果觉得遍历太耗费资源,没有必要遍历的时候,可以使用搜索
搜索文档对象
- find_all(name, attrs, recursive, text, ** kwargs)
- 使用find_all(),返回的列表格式,也就是说如果 find_all(name='meta') ,如果有多个 meta 就以列表形式返回
- name 参数:按照哪个字符搜索,可以传入的内容为
- 1.字符串
- 2.正则表达式,使用正则需要编译:
例如:我们需要打印所有以 me 开头的标签内容
tags = soup.find_all(re.compile('^me')) - 3.也可以是列表
- keyword 参数,可以用来表示属性
- text:对应 tag 的文本值
- 案例代码27bs4.py文件:https://xpwi.github.io/py/py爬虫/py27bs4.py
# BeautifulSoup 的使用案例
# 搜索文档对象
from urllib import request
from bs4 import BeautifulSoup
import re
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
# 使用 find_all
# 使用 name 参数
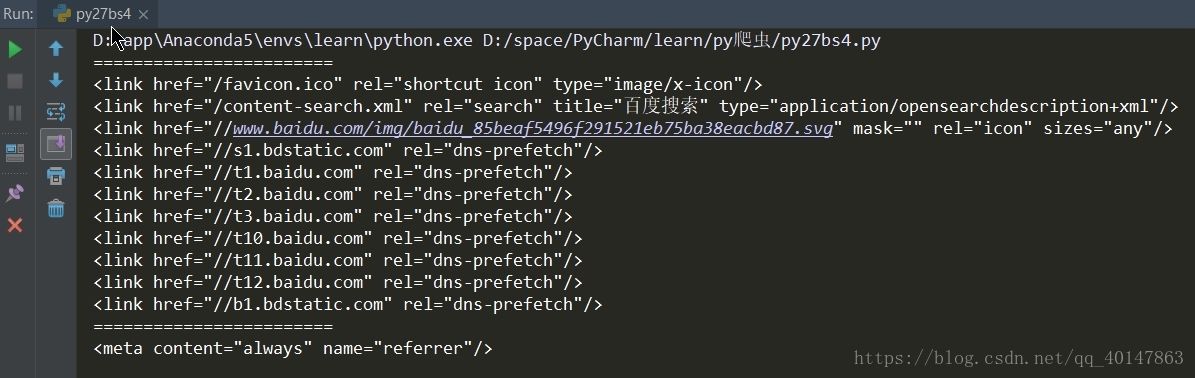
print("=="*12)
tags = soup.find_all(name='link')
for i in tags:
print(i)
# 使用正则表达式
print("=="*12)
# 同时使用两个条件
tags = soup.find_all(re.compile('^me'), content='always')
# 这里直接打印 tags 会打印一个列表
for i in tags:
print(i)
运行结果:
因为使用两个条件,所以只匹配到一条 meta
下一篇介绍,BeautifulSoup 的 css 选择器
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-24-数据提取-BeautifulSoup4(二)的更多相关文章
- Python爬虫教程-23-数据提取-BeautifulSoup4(一)
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc. ...
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
- Python爬虫教程-19-数据提取-正则表达式(re)
本篇主页内容:match的基本使用,search的基本使用,findall,finditer的基本使用,匹配中文,贪婪与非贪婪模式 Python爬虫教程-19-数据提取-正则表达式(re) 正则表达式 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫 什么是分布式爬虫 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集.单机爬虫就是只在一 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
随机推荐
- 解决kvm虚拟机启动之后,网卡eth0变为eth1问题
2018-12-19 故障前提 kvm虚拟机迁移到其他服务器上之后,重新启动网卡会出现问题 例如原网卡名称为eth0,迁移重启之后会自动变为eth1 为什么eth0会变成eth1? 很多Linux d ...
- springMVC中一些功能
1.controller的生命周期 spring框架默认为单例模式,会使数据之间的传递互相影响,而springMVC给我们提供了request与session两个,request每次请求就会产生一个单 ...
- 解决js array的key不为数字时获取长度的问题
最近写js时碰到了当数组key不为数字时,获取数组的长度为0 的情况. 1.问题场景 var arr = new Array(); arr[‘s1‘] = 1001; console.log(arr. ...
- EXTJS文档地址
文档地址:http://docs.sencha.com/extjs/4.2.3/#!/api/Ext.form.field.Field-event-change
- js获取字符串字节的位数
ifSubUser.getBlength = function(str){ ;i--;){ n += str.charCodeAt(i) > ? : ; } return n; }
- RabbitMQ的TopicExchange通配符问题
TopicExchange交换机支持使用通配符*.# *号只能向后多匹配一层路径. #号可以向后匹配多层路径.
- Hibernate的抓取策略(优化)
延迟加载的概述 什么是延迟加载 延迟加载:lazy(懒加载).执行到该行代码的时候,不会发送语句去进行查询,在真正使用这个对象的属性的时候才会发送SQL语句进行查询. 延迟加载的分类 l 类级别的延 ...
- (转)MySQL- 5.7 sys schema笔记,mysql-schema
原文:http://www.bkjia.com/Mysql/1222405.html http://www.ywnds.com/?p=5045 performance_schema提供监控策略及大量监 ...
- Bugfree安装与使用
第一步:下载XAMPP和bugfree http://www.bugfree.org.cn/ http://www.apachefriends.org/zh_cn/xampp.html 第二步:安装 ...
- 使用jsp完成商品列表的动态显示
1数据库准备工作 1创建数据库 2 创建product表 代码如下: CREATE TABLE `product` ( `pid` ) NOT NULL, `pname` ) DEFAULT NULL ...