【原创】MapReduce程序如何在集群上执行
首先了解下资源调度管理框架Yarn。
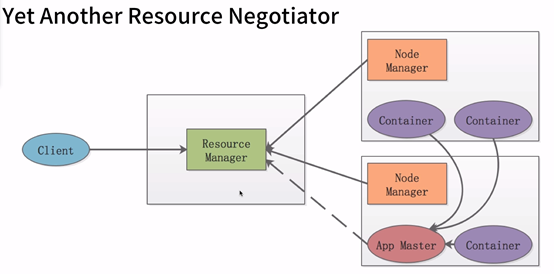
Yarn的结构(如图):
Resource Manager (rm)负责调度管理整个集群上的资源,而每一个计算节点上都会有一个Node Manager(nm)来负责该节点上的计算资源,我们把计算资源抽象成一个个Container(容器),每个Container包含一定数量的cpu核数和一定大小的内存。一个应用程序由一个App Master 来管理,App Master 负责将一个程序运行在各个节点的Container中。
Yarn 组件分工:
1. Resource Manager
主要职责是调度,对应用程序的整体进行资源分配。
2. Container
单个节点的物理资源的集合,比如内存,cpu。
3. Node Manage
管理Container生命周期,资源使用情况,节点健康状况,并且将这些信息汇报给Recource Manager。
4. Application Master
协调集群中的应用程序,与Resource Manager协商资源,并且将这个应用程序运行在集群之中。
MapReduce程序如何在集群上执行?
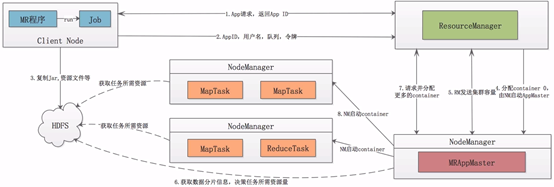
执行过程:
- mr会在客户端启动,客户端会向rm 发送一个 app 请求,rm会返回一个appid给客户端,
- 客户端会拿着appid,用户名,队列,令牌向rm进行请求,
- 客户端会将应用程序所用的jar包,资源文件,以及程序运行时所需要的数据传送到hdfs,
- rm会分配一个container0的资源包,由nm启动一个 appmaster
- rm将集群容量信息发送给appmaster,
- appmaster计算这个程序需要的资源量
- 向rm 请求分配更多的container
- nm在各个节点上启动map任务和reduce任务。
总结:
- 客户端提交mr程序,向rm请求资源,并将程序依赖的资源上传到hdfs,
- Rm分配一个container0,nm启动am,用来管理这个mr程序,am计算好所需要的资源后向rm请求更多的资源。
- nm在各个节点上启动map task和reduce task
【原创】MapReduce程序如何在集群上执行的更多相关文章
- [MapReduce_add_1] Windows 下开发 MapReduce 程序部署到集群
0. 说明 Windows 下开发 MapReduce 程序部署到集群 1. 前提 在本地开发的时候保证 resource 中包含以下配置文件,从集群的配置文件中拷贝 在 resource 中新建 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- 攻城狮在路上(陆)-- 提交运行MapReduce程序到hadoop集群运行
此种方式不能直接在eclipse中调试代码. 首先需要在src下放置服务器上的hadoop配置文件:core-site.xml\yarn-site.xml\hdfs-site.xml\mapred-s ...
- CDH集群spark-shell执行过程分析
目的 刚入门spark,安装的是CDH的版本,版本号spark-core_2.11-2.4.0-cdh6.2.1,部署了cdh客户端(非集群节点),本文主要以spark-shell为例子,对在cdh客 ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控
写在前面 相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试 用python + hado ...
- hadoop 把mapreduce任务从本地提交到hadoop集群上运行
MapReduce任务有三种运行方式: 1.windows(linux)本地调试运行,需要本地hadoop环境支持 2.本地编译成jar包,手动发送到hadoop集群上用hadoop jar或者yar ...
- 在集群上运行caffe程序时如何避免Out of Memory
不少同学抱怨,在集群的GPU节点上运行caffe程序时,经常出现"Out of Memory"的情况.实际上,如果我们在提交caffe程序到某个GPU节点的同时,指定该节点某个比较 ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
随机推荐
- 前端-chromeF12 谷歌开发者工具详解 Network篇
开发者工具初步介绍 chrome开发者工具最常用的四个功能模块: Elements:主要用来查看前面界面的html的Dom结构,和修改css的样式.css可以即时修改,即使显示.大大方便了开发者调试页 ...
- jxl读取excel
String path=""; String path2=""; File file = new File(path); File file2 = new Fi ...
- java中引用
java中引用分为,强,弱,虚,软 (1)强引用 使用最普遍的引用.如果一个对象具有强引用,它绝对不会被gc回收.如果内存空间不足了,gc宁愿抛出OutOfMemoryError,也不是会回收具有强引 ...
- python update()
Python 字典 update() 函数把字典参数 dict2 的 key/value(键/值) 对更新到字典 dict 里. dict.update(dict2) 如果dict2里的键和dict1 ...
- CAS总结
n++的问题不能保证原子操作. 因为被编译后拆分成了3个指令,先获取值,然后加一,然后写回内存.把变量声明为volatile,volatile只能保证内存可见性,但是不能保证原子性,在多线程并发下,无 ...
- JavaSwing概述
GUI(Graphic User Interface)为程序提供图形界面,它最初的设计目的是构建一个通用的GUI,使其能在所有平台上运行.在Java1.0中基础类AWT(Abstract Window ...
- 在Vue项目中使用html2canvas生成页面截图并上传
使用方法 项目中引入 npm install html2canvas html代码 //html代码 <!-- 把需要生成截图的元素放在一个元素容器里,设置一个ref --> <di ...
- 12.2.0.1 restart环境执行root.sh 报 CLSRSC-400 错误
问题描述: 在LINUX 7.5 的环境上安装12.2.0.1 Restart Grid环境,执行root.sh 报 CLSRSC-400 错误 错误如下: 解决办法: 1. 参考(文档ID 136 ...
- jQuery练习 | 模态对话框(添加删除)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- GridView控件详解
一.介绍 GridView控件一表格形式显示数据源中的数据.提供对列进行排序.分页以及编辑.删除单个记录的功能. 二.绑定数据源 第一种使用DataSourceID属性.可以直接把GridView控件 ...