Affinity Propagation
1. 调用方法:
AffinityPropagation(damping=0.5, max_iter=200, convergence_iter=15, copy=True, preference=None, affinity=’euclidean’, verbose=False)
参数:
damping : float, optional, default: 0.5 防止更新过程中数值震荡
max_iter : int, optional, default: 200
convergence_iter : int, optional, default: 15
如果类簇数目在达到这么多次迭代以后仍然不变的话,就停止迭代。
copy : boolean, optional, default: True
Make a copy of input data.
preference : array-like, shape (n_samples,) or float, optional
每个points的preference。具有更大preference的点更可能被选为exemplar。类簇的数目受此值的影响,如果没有传递此参数,它们 会被设置成input similarities的中值。???
affinity : string, optional, default=``euclidean``
度量距离的方式,推荐precomputed and euclidean这两种,euclidean uses the negative squared euclidean distance between points.
verbose : boolean, optional, default: False
属性:
cluster_centers_indices_ : array, shape (n_clusters,)
类簇中心的索引
cluster_centers_ : array, shape (n_clusters, n_features)
类簇中心 (if affinity != precomputed)
labels_ : array, shape (n_samples,)
每个point的标签
affinity_matrix_ : array, shape (n_samples, n_samples)
Stores the affinity matrix used in fit.
n_iter_ : int
达到收敛需要的迭代次数。
2. scikit-learn介绍
http://scikit-learn.org/stable/modules/clustering.html#affinity-propagation
3. 算法复杂性
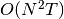 ,与样本数成正比。
,与样本数成正比。
4.算法描述
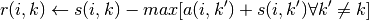
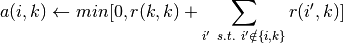
引入阻尼因子:
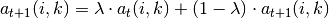
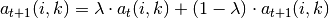
Affinity Propagation的更多相关文章
- AP(affinity propagation)研究
待补充…… AP算法,即Affinity propagation,是Brendan J. Frey* 和Delbert Dueck于2007年在science上提出的一种算法(文章链接,维基百科) 现 ...
- Affinity Propagation Algorithm
The principle of Affinity Propagation Algorithm is discribed at above. It is widly applied in many f ...
- Affinity Propagation Demo2学习【可视化股票市场结构】
这个例子利用几个无监督的技术从历史报价的变动中提取股票市场结构. 使用报价的日变化数据进行试验. Learning a graph structure 首先使用sparse inverse(相反) c ...
- Affinity Propagation Demo1学习
利用AP算法进行聚类: 首先导入需要的包: from sklearn.cluster import AffinityPropagation from sklearn import metrics fr ...
- AP聚类算法(Affinity propagation Clustering Algorithm )
AP聚类算法是基于数据点间的"信息传递"的一种聚类算法.与k-均值算法或k中心点算法不同,AP算法不需要在运行算法之前确定聚类的个数.AP算法寻找的"examplars& ...
- knn/kmeans/kmeans++/Mini Batch K-means/Affinity Propagation/Mean Shift/层次聚类/DBSCAN 区别
可以看出来除了KNN以外其他算法都是聚类算法 1.knn/kmeans/kmeans++区别 先给大家贴个简洁明了的图,好几个地方都看到过,我也不知道到底谁是原作者啦,如果侵权麻烦联系我咯~~~~ k ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- 【转帖】Python在大数据分析及机器学习中的兵器谱
Flask:Python系的轻量级Web框架. 1. 网页爬虫工具集 Scrapy 推荐大牛pluskid早年的一篇文章:<Scrapy 轻松定制网络爬虫> Beautiful Soup ...
- {Reship}{Code}{CV}
UIUC的Jia-Bin Huang同学收集了很多计算机视觉方面的代码,链接如下: https://netfiles.uiuc.edu/jbhuang1/www/resources/vision/in ...
随机推荐
- Spring中常见的设计模式——策略模式
策略模式(Strategy Pattern) 一.策略模式的应用场景 策略模式的应用场景如下: 系统中有很多类,而他们的区别仅仅在于行为不同. 一个系统需要动态的在集中算法中选择一种 二.用策略模式实 ...
- 用Decorator实现依赖注入,像Java一样写后台
最近闲来无事,突发奇想,也顺便练练手,于是就萌生了,能否用typescript的decorator写一个Nodejs SpringMVC,通过依赖注入,自动实现文件加载,实例化等.然后就有了这个项目. ...
- 在Windows Server 2003中搭建DNS服务器
1.安装Windows Server 2003虚拟机 准备好Windows Server 2003的镜像:http://www.downza.cn/soft/184944.html 2.Windows ...
- 【转】8 个效果惊人的 WebGL/JavaScript 演示
英文原文:9 IMPRESSIVE WEBGL JAVASCRIPT EFFECT SHOWCASE,翻译:iteye WebGL 是一种 3D 绘图标准,这种绘图技术标准允许把 JavaScript ...
- 案例分析丨H&M用设计冲刺将App研发周期缩短为6个月
案例背景 H&M是一家来自瑞典的时装公司,1947年成立.截至2018年6月,H&M 分店遍布全球 68 个国家和地区,分店数目为 4338 间. 作为快速服装生产商,H&M的 ...
- 两个关于 Java 面试的 Github 项目
哈喽,大家好.相信大家都知道金九银十,在人才市场上是指每年的 9 月和 10 月是企业的招聘高峰期.这个时候企业往往有大量招聘需求,求职者在这个时候就找工作无疑是最适合的.需求大,谈工资什么的就更容易 ...
- Replacing the deprecated Java JPEG classes for Java 7
[src: https://blog.idrsolutions.com/2012/05/replacing-the-deprecated-java-jpeg-classes-for-java-7/] ...
- maven install 报错 Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.12.4:test
pom文件引入以下依赖 <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId> ...
- HBase二次开发之搭建HBase调试环境,如何远程debug HBase源代码
版本 HDP:3.0.1.0 HBase:2.0.0 一.前言 之前的文章也提到过,最近工作中需要对HBase进行二次开发(参照HBase的AES加密方法,为HBase增加SMS4数据加密类型).研究 ...
- 动态规划 之 区间DP练习
前言 \(Loj\) 放上了那么多<信息学奥赛一本通>上的题(虽然我并没有这本书),我要给它点一个大大的赞 ^_^ 以后分类刷题不愁啦! 正文 那就一道道说吧. 石子合并 将 \(n\) ...