爬虫-通过本地IP地址从中国天气网爬取当前城市天气情况
1.问题描述
最近在做一个pyqt登录校园网的小项目,想在窗口的状态栏加上当天的天气情况,用爬虫可以很好的解决我的问题。
*最新,发现www.ip.cn采用了js动态加载,所以代码有所变化,但整体思路不变
2.解决思路
考虑到所处位置的不同,需要先获取本地城市地址,然后作为中国天气网的输入,爬取指定城市的天气信息。
a. 先通过https://www.ip.cn/爬取本地城市名称
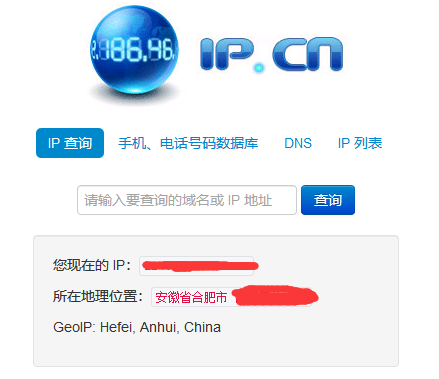
b. 再通过获取本地城市名称作为输入

进入城市页面获取所需信息即可,看起来不难,不就是爬、爬吗

3.思路实现
a 很容易实现,直接上代码
def download_page(url):
"""
获取网页源代码
"""
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0'}
html = requests.get(url, headers=headers)
# print(html.text)
return html.text
def get_city_name(html):
"""
对网页内容进行解析并分析得到需要的数据
"""
selector = etree.HTML(html) # 将源码转换为能被XPath匹配的格式
_info = selector.xpath('//script')[1].text # 由于网页采用动态加载,“所在的地理位置”跑到了<script>中
location = re.findall(r"<code>(.*?)</code>", _info)[1]
location = location.split(" ")[0]
if location in municipality:
city = location[:-1] # 直辖市的话不取'市',不然天气结果会不准
else:
for i, char in enumerate(location):
if char == "区" or char == "省":
index = i + 1
break
city = location[index:-1] # 取'省'后面一直到'市'中间的城市名称用作天气搜索
return city
我的ip会返回‘合肥’,北京,上海这些直辖市和一些自治区需要特别处理一下才能获得所需城市名,这里必须返回城市名称,不然直接搜索会出现这样,得不到任何天气data,好吧,能给我天气情况就行,要什么自行车:

b 的话需要2步走,首先获取城市对于编码
在输入合肥点击搜索之后,通过观察网络请求信息,浏览器发送了一个GET请求,服务器响应数据中包含城市码,如下图


def get_city_code(city='合肥'):
"""
输入一个城市,返回在中国天气网上城市所对应的code
"""
try:
parameter = urlparse.parse.urlencode({'cityname': city})
conn = http.client.HTTPConnection('toy1.weather.com.cn', 80, timeout=5)
conn.request('GET', '/search?'+parameter)
r = conn.getresponse()
data = r.read().decode()[1:-1]
json_data = json.loads(data)
code = json_data[0]['ref'].split('~')[0] # 返回城市编码
return code
except Exception as e:
raise e
模拟发送请求即可,头信息在这,这里&callback和&_参数可以不要,然后对响应做下处理,因为得到的JSON数据字符串,需要将字符串转为JSON数据格式,这就能得到城市码了。

终于到了最后一步,也是最烦,不对,是最难的一步,获取城市天气信息,按说操作思路和上面差不多,就是分析页面数据然后找标签就行了,,,
可是这个网站竟然是javascript动态加载的,获取的页面图上所指的内容啥都没,这要我怎么获取天气情况,对于只会爬取非动态网页的小白,只能留下没技术的眼泪。

就这样,又去学了一点动态爬取网站的基础知识,通过一个一个请求分析查看,终于找到了我所要的信息,其实只要看响应就行了,服务器js返回的值都在这能看到。

接着套路和上面一样,发送一个GET请求等服务器返回数据我们拿来用就行了
。。。。。。。。

问题又出现了,这次又是403,还有有人已经走过这条路了,在GET请求加上headers就行了,不让服务器发现这是爬虫,而是认为这是浏览器在请求,结果发现只需要在请求头加上Referer参数就行,看来服务器并没有真正做到反扒。。。。

def get_city_weather(city_code):
"""
通过城市编码找到天气信息
"""
try:
url = 'http://www.weather.com.cn/weather1dn/' + city_code + '.shtml'
# 这里选择的体验新版,所以是1dn,旧版是1d
headers = { "Referer": url }
conn = http.client.HTTPConnection('d1.weather.com.cn', 80, timeout=5)
conn.request('GET', '/sk_2d/' + city_code + '.html', headers=headers)
r = conn.getresponse()
data = r.read().decode()[13:]
weather_info = json.loads(data)
return weather_info
except Exception as e:
raise e
好了,大功告成!

贴一下自己的代码供有需要的人参考:
# -*- coding:utf-8 -*-
# 天气脚本
import json
import re
import urllib as urlparse
import http.client
import requests
from lxml import etree
target_url = 'https://www.ip.cn/'
municipality = ['北京市','上海市','重庆市','天津市']
def download_page(url):
"""
获取网页源代码
"""
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0'}
html = requests.get(url, headers=headers)
# print(html.text)
return html.text
def get_city_name(html):
"""
对网页内容进行解析并分析得到需要的数据
"""
selector = etree.HTML(html) # 将源码转换为能被XPath匹配的格式
_info = selector.xpath('//script')[1].text # 由于网页采用动态加载,“所在的地理位置”跑到了<script>中
location = re.findall(r"<code>(.*?)</code>", _info)[1] #使用正则表达式获取地理位置信息,在<code></code>标签中
location = location.split(" ")[0]
if location in municipality:
city = location[:-1] # 直辖市的话不取'市',不然天气结果会不准
else:
for i, char in enumerate(location):
if char == "区" or char == "省":
index = i + 1
break
city = location[index:-1] # 取'省'后面一直到'市'中间的城市名称用作天气搜索
return city
def get_city_code(city='合肥'):
"""
输入一个城市,返回在中国天气网上城市所对应的code
"""
try:
parameter = urlparse.parse.urlencode({'cityname': city})
conn = http.client.HTTPConnection('toy1.weather.com.cn', 80, timeout=5)
conn.request('GET', '/search?' + parameter)
r = conn.getresponse()
data = r.read().decode()[1:-1]
json_data = json.loads(data)
code = json_data[0]['ref'].split('~')[0] # 返回城市编码
return code
except Exception as e:
raise e
def get_city_weather(city_code):
"""
通过城市编码找到天气信息
"""
try:
url = 'http://www.weather.com.cn/weather1dn/' + city_code + '.shtml'
headers = { "Referer": url }
conn = http.client.HTTPConnection('d1.weather.com.cn', 80, timeout=5)
conn.request('GET', '/sk_2d/' + city_code + '.html', headers=headers)
r = conn.getresponse()
data = r.read().decode()[13:]
weather_info = json.loads(data)
return weather_info
except Exception as e:
raise e
if __name__ == '__main__':
city = get_city_name(download_page(target_url))
city_code = get_city_code(city)
city_wether = get_city_weather(city_code)
print(city_wether)
PS:第一次写博客,markdown刚学还不是很熟,表达可能也有点欠缺。
每次都是从别人那填好的坑走过,这次要填自己的坑,给别人开路
爬虫-通过本地IP地址从中国天气网爬取当前城市天气情况的更多相关文章
- Python-定时爬取指定城市天气(二)-邮件提醒
目录 一.概述 二.模块重新划分 三.优化定时任务 四.发送邮件 五.源代码 一.概述 上一篇文章python-定时爬取指定城市天气(一)-发送给关心的微信好友中我们讲述了怎么定时爬取城市天气,并发送 ...
- Python-定时爬取指定城市天气(一)-发送给关心的微信好友
一.背景 上班的日子总是3点一线,家里,公司和上班的路径,对于一个特别懒得我来说,经常遇到上班路上下雨了,而我却没带伞,多么痛的领悟.最近对python有一种狂热的学习热情,写了4年多的C++代码,对 ...
- 关于python的中国历年城市天气信息爬取
一.主题式网络爬虫设计方案(15分)1.主题式网络爬虫名称 关于python的中国城市天气网爬取 2.主题式网络爬虫爬取的内容与数据特征分析 爬取中国天气网各个城市每年各个月份的天气数据, 包括最高城 ...
- 获取本地IP地址信息
2012-06-05 /// <summary> /// 获取本地IP地址信息 /// </summary> void G ...
- 获取Mac、CPUID、硬盘序列号、本地IP地址、外网IP地址OCX控件
提供获取Mac.CPUID.硬盘序列号.本地IP地址.外网IP地址OCX控件 开发语言:vc++ 可应用与WEB程序开发应用 <HTML><HEAD><TITLE> ...
- c、c++混编实现查询本地IP地址
一.思路 1.要想得到本地IP地址,可以通过本机名来查询,所以首先得得到本机名. 2.牵涉到IP地址,首先想到牵涉到网络协议,因此得加载套接字协议,所以先使用WSAStartup函数完成对Winsoc ...
- python获取本地ip地址的方法
#_*_coding:utf8_*_ #以下两种方法可以在ubuntu下或者windows下获得本地的IP地址 import socket # 方法一 localIP = socket.gethost ...
- C# — 动态获取本地IP地址及可用端口
1.在VS中动态获取本地IP地址,代码如下: 2.获取本机的可用端口以及已使用的端口:
- Android 获得本地IP地址、外网IP地址、本设备网络状态信息、本地Mac地址
本地内网IP和外网IP的区别: 根据我的经验一台电脑需要两个ip才可以上网,一个是本地的内网ip 一个是外网的ip 本地的ip 一般是192.168.1.2这种样子 只要在不同的路由器上可以重复 外 ...
随机推荐
- Docker概述
Docker概述 Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化.容器是完全可以使用沙盒机制,互 ...
- zabbix proxy部署
一.概述 环境: 因为公司需要监控远程客户机,但server端无法主动连接agent端,客户端可以连接公司ip 公司有固定ip,可以开放某个端口给zabbixserver,客户机agent端可以主动通 ...
- (十一)Updating Documents
In addition to being able to index and replace documents, we can also update documents. Note though ...
- dede 5.7 任意用户重置密码前台
返回了重置的链接,还要把&删除了,就可以重置密码了 结果只能改test的密码,进去过后,这个居然是admin的密码,有点头大,感觉这样就没有意思了 我是直接上传的一句话,用菜刀连才有乐趣 ...
- Django视图(views)
1.FBV (基于函数的视图) 实例 url.py url(r'^add_publicer/',views.add_publicer) def add_publicer(request): if re ...
- [Oracle维护工程师手记]为什么flashback 的时候既需要 flashback log ,又需要 archive log?
为什么flashback 的时候既需要 flashback log ,又需要 archive log 呢? 如果数据库的活动不是很频繁,可以看到,其flashback log 是比较小的.那么是通过怎 ...
- Word写博常用博客URL地址
地址 描述 http://imguowei.blog.51cto.com/xmlrpc.php 51cto http://upload.move.blog.sina.com.cn/blog_rebui ...
- MySQL中 in和exists的区别
A表: 100条数据 , B: 10条数据 select * from A where id in ( select aid from B ) 先执行括号里面的查询,然后执行外面,总共需要查询的次数的 ...
- github 管理代码: code.Aliyun
阿里云代码管理,,cao,搞了半天,配置百度就可以了,我只想说代码控制可以用github桌面版管理
- Django模板语言进阶
一.母板 1.什么情况下使用母版 当多个页面的大部分内容都一样的时候,我们可以把相同的部分提取出来,放到一个单独的母版HTML文件中 然后在母版中定义需要被替换的block 例如:母板页面 <! ...