使用IDEA打包scala程序并在spark中运行
一、首先配置ssh无秘钥登陆,
先使用这条命令:ssh-keygen,然后敲三下回车;
然后使用cd .ssh进入 .ssh这个隐藏文件夹;
再创建一个文件夹authorized_keys,使用命令touch authorized_keys;
然后使用cat id_rsa.pub > authorized_keys 即可;
最后使用 chmod 600 authorized_keys修改权限就完成了。
二、创建spark项目
idea创建spark项目的过程这里就略过了,具体可以看这里https://www.cnblogs.com/xxbbtt/p/8143441.html
三、在pom.xml加入相关的依赖包
在pom.xml文件中添加:
<properties>
<spark.version>2.1.0</spark.version>
<scala.version>2.11</scala.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency> </dependencies> <build>
<plugins> <plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin> </plugins>
</build>
然后等待就好了。。。
四、编写一个示范程序
创建一个scala类,并写以下代码,也可以是其他的,这里只是测试而已
object first {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordcount")
val sc = new SparkContext(conf)
val input = sc.textFile("/home/cjj/testfile/helloSpark.txt")
val lines = input.flatMap(line => line.split(" "))
val count = lines.map(word => (word, 1)).reduceByKey { case (x, y) => x + y }
val output = count.saveAsTextFile("/home/cjj/testfile/helloSparkRes")
}
}
这里使用了Spark实现的功能是,计算helloSpark.txt这个文件各个单词出现的次数,并保存在helloSparkRes文件夹中。
五、打包
file->Porject Structure->Artifacts->绿色的加号->JAR->from modules...
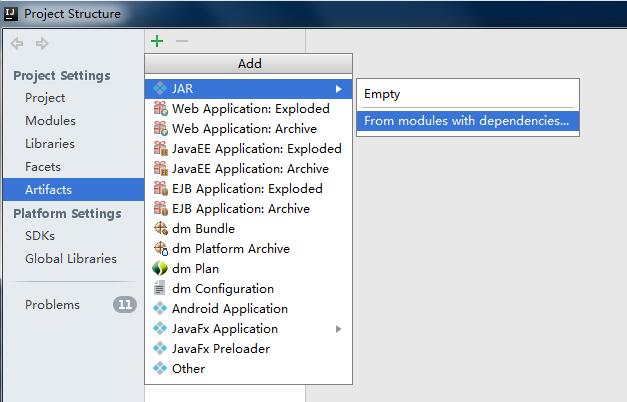
跳出以下对话框,选择要打包的类,然后选择copy to.....选项,这里的意思是只打包这一个类。
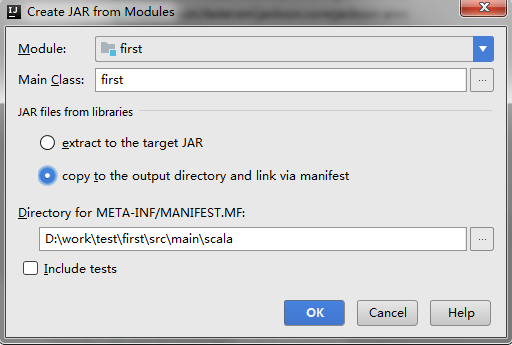
然后点击ok,然后ok。然后build->build Artifacts
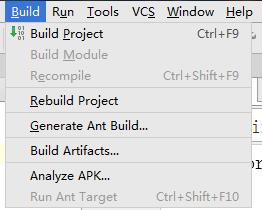
再然后点击build
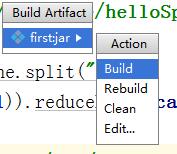
等待build完成。然后可以在项目的这个目录中找到刚刚打包的这个jar包
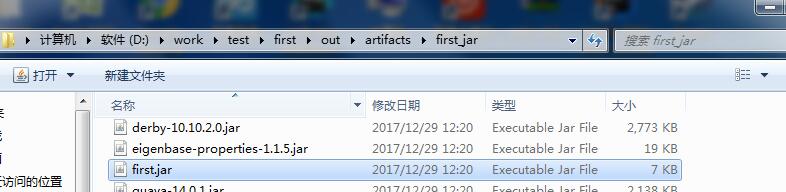
这里的first的我的项目名。
六、启动集群
先将刚才打包的jar包复制到虚拟机中,
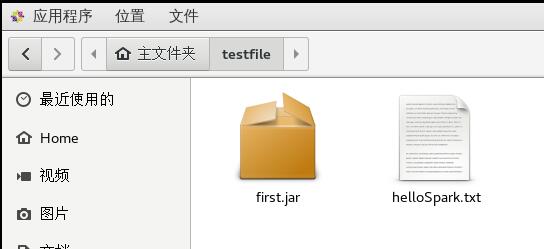
helloSpark.txt是我将要操作的文件。接着就是启动集群,分为三步
- 启动master ./sbin/start-master.sh
- 启动worker ./bin/spark-class
- 提交作业 ./bin/spark-submit
首先进入spark-2.2.1-bin-hadoop2.7文件夹,然后运行命令./sbin/start-master.sh
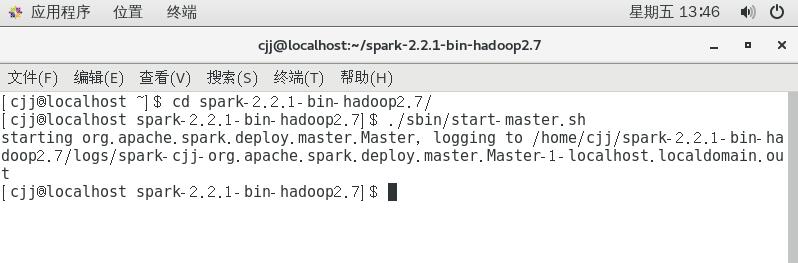
然后可以打开浏览器,进入localhost:8080,可以看到
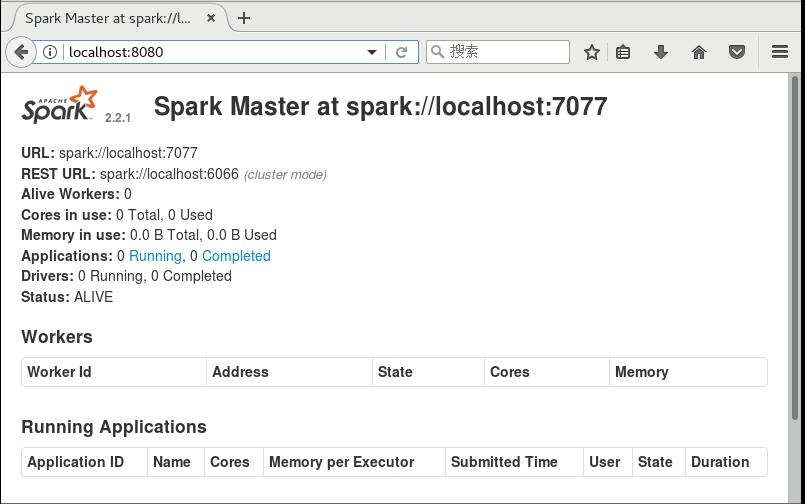
这里的URL spark://localhost:7077需要记下来下一步需要使用,下一步启动work,加上刚刚的URL,可以使用的命令是,
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
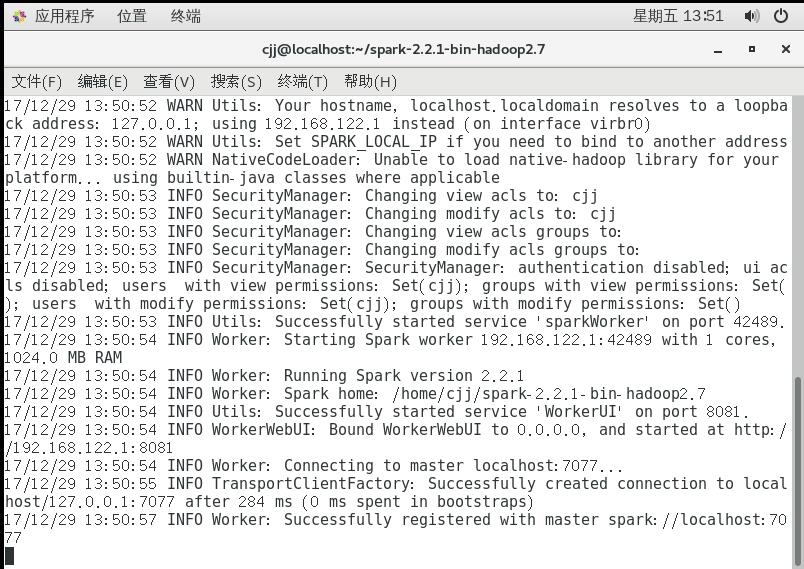
这时启动另一个窗口进行提交作业,同样需要先进入spark文件夹,然后运行命令
./bin/spark-submit --master spark://localhost:7077 --class first /home/cjj/testfile/first.jar
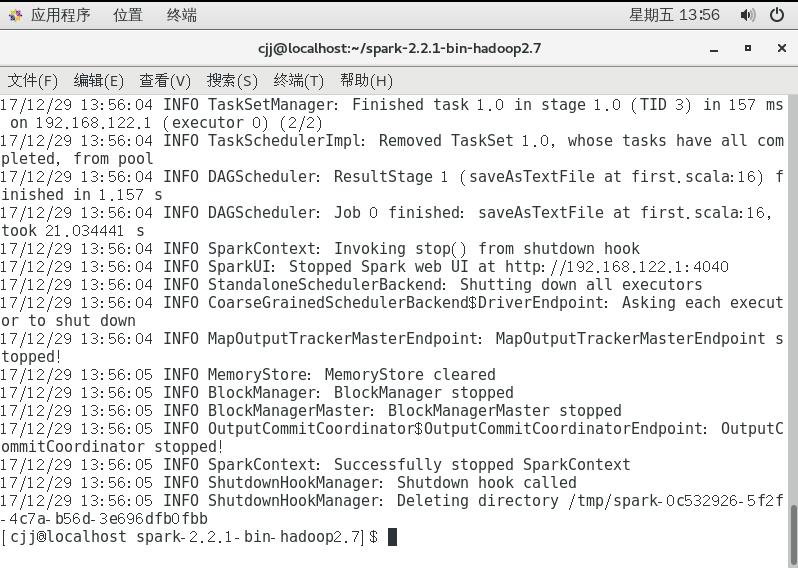
这样就算完成了,我们可以来看看结果,看结果之前需要先看一看helloSpark.txt的内容
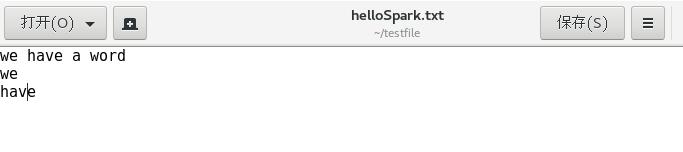
结果保存在helloSparkRes中,下面是结果
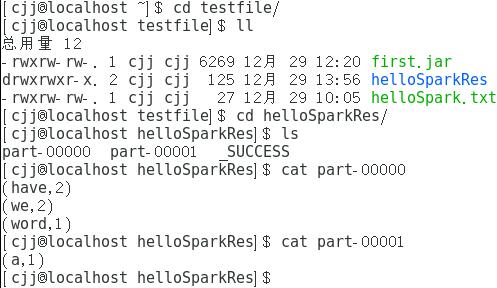
这里的结果告诉我们have和word的个数为2,word和a的个数为1。
使用IDEA打包scala程序并在spark中运行的更多相关文章
- docker 运行jenkins及vue项目与springboot项目(五.jenkins打包springboot服务且在docker中运行)
docker 运行jenkins及vue项目与springboot项目: 一.安装docker 二.docker运行jenkins为自动打包运行做准备 三.jenkins的使用及自动打包vue项目 四 ...
- intellij-idea打包Scala代码在spark中运行
.创建好Maven项目之后(记得添加Scala框架到该项目),修改pom.xml文件,添加如下内容: <properties> <spark.version></spar ...
- 使用IntelliJ IDEA编写Scala在Spark中运行
使用Scala写一个测试代码: object Test { def main(args: Array[String]): Unit = { println("hello world" ...
- 判断Java程序是否在jar中运行
URL url = TextRenderer.class.getResource(""); String protocol = url.getProtocol(); boolean ...
- 关于python程序在VS code中运行时提示文件无法找到的报错
经过测试,在设置文件夹目录时,可以找到当前目录下的htm文件,采用with open()语句可以正常执行程序,如下图. 而当未设置当前目录,直接用vscode执行该程序时,就会报错文件无法找到File ...
- C编译器MinGW安装、下载及在notepad++中运行C程序
一.C编译器MinGW的下载及安装步骤 打开MinGW官网:http://www.mingw.org/ 图一 图二 图三 图四 图五 图六 系统中配置环境变量: 图七 验证是否安装成功: CMD中运行 ...
- sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类
sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类 详述 使用sbt对写的Spark程序打包,过程中没有问题 spark-submit提交jar包运行提示找不到对应的类 解 ...
- 通过IDEA搭建scala开发环境开发spark应用程序
一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安装scala插件,具体安装办法如下. 1.打开idea,点击c ...
- IDEA搭建scala开发环境开发spark应用程序
通过IDEA搭建scala开发环境开发spark应用程序 一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安 ...
随机推荐
- Modbus RTU新版本指令介绍
Modbus RTU新版本指令介绍 TIA V13 SP1版本软件中提供了2个版本的Modbus RTU指令: 图1. 两个版本Modbus RTU指令 早期版本的Modbus RTU指令(图1. 中 ...
- c++二分查找
c++二分查找 题目是在一些数字里找出一个数字,并输出他在第几行 代码 + 注释 #include <stdio.h> #include<iostream> using nam ...
- 微信开发:微信js_sdk分享,使用场景,网页在微信app内部分享时的标题与描述,包括logo设置(一)
主要有下面几步.首先大家先分清楚 小程序的appid,appSecret 跟公众号的appid,appSecret是不一样的.因为这两个都能拿到token,且是不同的值. 准备开始: 1.准备好 公众 ...
- Node热部署插件
一.supervisor 首先需要使用 npm 安装 supervisor(这里需要注意一点,supervisor必须安装到全局) $ npm install -g supervisor Linux ...
- JAVA基础-基础类型
学习JAVA的同学都知道,数据类型是基础中的基础,而JAVA本身是强类型语言,他对变量的类型有这魔一般的执著,所以学好JAVA的重心就是要学好数据类型.既然有强类型语言,就会有弱类型语言如PHP.Ja ...
- python接口自动化(二十九)--html测试报告通过邮件发出去——上(详解)
简介 前边几篇,已经教小伙伴们掌握了如何生成HTML的测试报告,那么生成测试报告,我们也不能放在那里不管了,这样即使你报告在漂亮,领导也看不到.因此如果想向领导汇报工作,不仅需要提供更直观的测试报告. ...
- android_alertDialog
主文件 package cn.com.sxp;import android.app.Activity;import android.app.AlertDialog;import android.con ...
- vs2010 安装项目完成桌面快捷方式无法定位程序文件夹 解决方法
本文转载自http://www.cnblogs.com/jasonxuvip/archive/2012/07/13/2589952.html 软件打包工具有很多种,让人不知道选那个方便自己使用,Tig ...
- 【CYH-02】NOIp考砸后虐题赛:函数:题解
这道题貌似只有@AKEE 大佬A掉,恭喜! 还有因为c++中支持两个参数数量不同的相同名称的函数调用,所以当时就没改成两个函数,这里表示抱歉. 这道题可直接用指针+hash一下,然后就模拟即可. 代码 ...
- echarts在react项目中的使用
数据可视化在前端开发中经常会遇到,万恶的图表,有时候总是就差一点,可是怎么也搞不定. 别慌,咱们一起来研究. 引入我就不多说了 npm install echarts 对于基础的可视化组件,我一般采用 ...