5.3 RDD编程---数据读写
一、文件数据读写
1.本地文件系统的数据读写
可以采用多种方式创建Pair RDD,其中一种主要方式是使用map()函数来实现
惰性机制,即使输入了错误的语句spark-shell也不会马上报错。
(1)读
给出路径名称,TextFile会把路径下面的所有文件都读进来,生成一个RDD
(2)写

当只有一个分区时,单线程才会出现part-0000
如果分了两个分区,写完之后会生成part-0000和part-0001
2.分布式文件系统HDFS的数据读写
(1)读
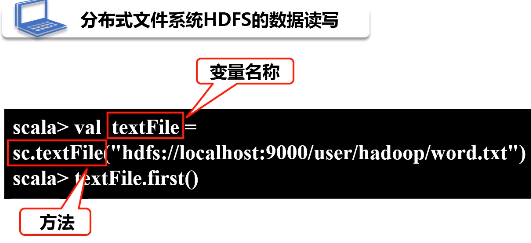

(2)写

3.JSON文件的数据读写
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式
(1)读

Scala中有一个自带的JSON库——scala.util.parsing.json.JSON,可以实现对JSON数据的解析
JSON.parseFull(jsonString:String)函数,以一个JSON字符串作为输入并进行解析,如果解析成功则返回一个Some(map: Map[String, Any]),如果解析失败则返回None。
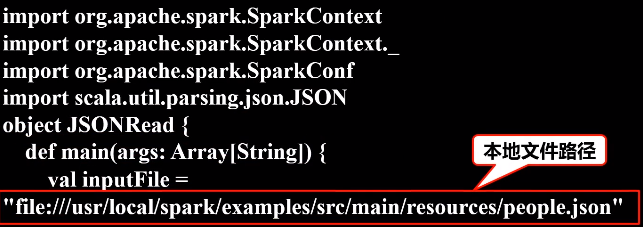

将整个应用程序打包成 JAR包,通过 spark-submit 运行程序

执行后可以在屏幕上的大量输出信息中找到如下结果:
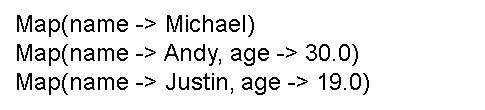
二、读写HBase数据
1.HBase简介
HBase是Google BigTable的开源实现


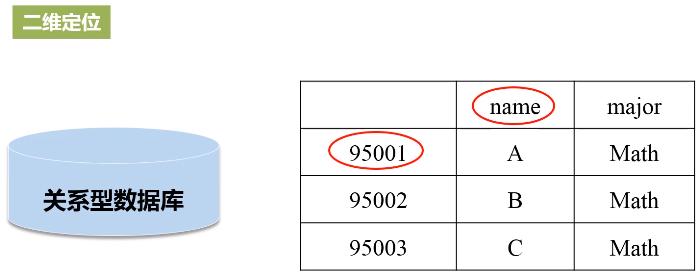
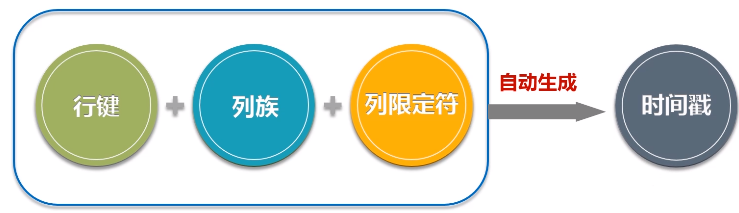
- HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳;
- 每个值是一个未经解释的字符串,没有数据类型;
- 用户在表中存储数据,每一行都有一个可排序的行键和任意多的列;
- 表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起;
- 列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换;
- HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留(这是和HDFS只允许追加不允许修改的特性相关的)
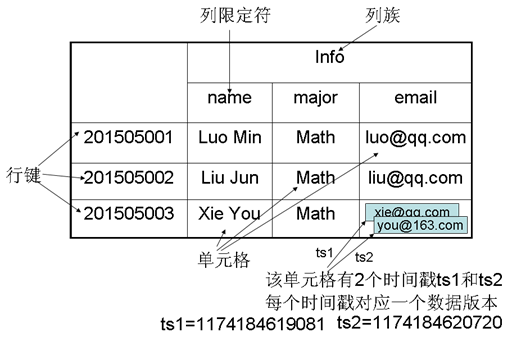
- 表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
- 行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
- 列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元
- 列限定符:列族里的数据通过列限定符(或列)来定位
- 单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
- 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引

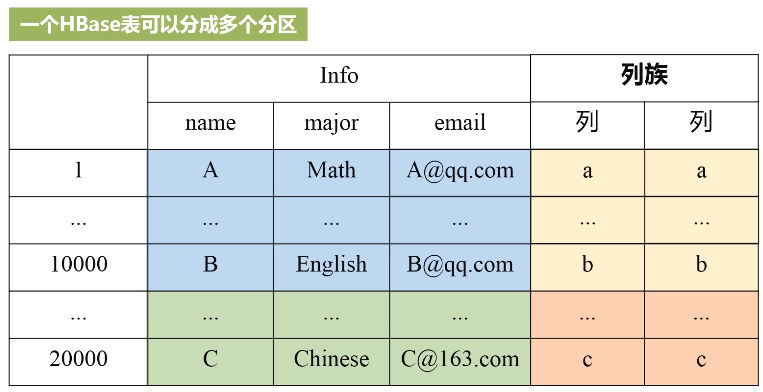
先切水平(学号1-10000,10001-20000,...),再切竖直(按列族分),每一种颜色得到小方格内都是一个分区,一个分区就是属于负载分发的基本单位,这样就可以实现分布式存储。有个元数据表可以存储每个分区对应的位置。
2.创建一个HBase表
第一步:安装配置HBase,将HBase安装成伪分布式
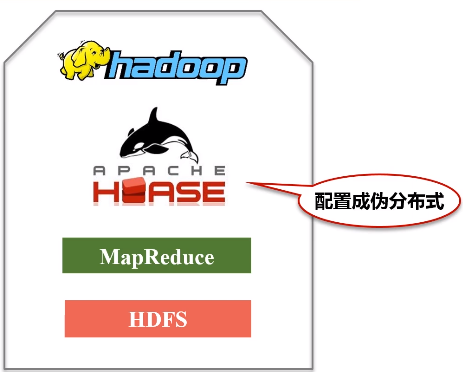
第二步:启动Hadoop和HBase

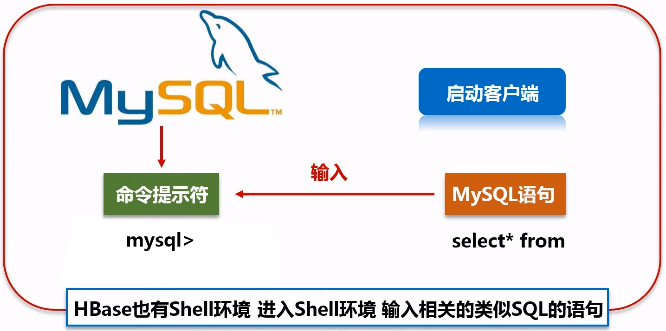
HBase也有shell环境,可以输入类似SQL的语句




3.配置Spark
把HBase的lib目录下的一些jar文件拷贝到Spark中,这些都是编程时需要引入的jar包,需要拷贝的jar文件包括:所有hbase开头的jar文件、guava-12.0.1.jar、htrace-core-3.1.0-incubating.jar和protobuf-java-2.5.0.jar

4.编写程序读取HBase数据
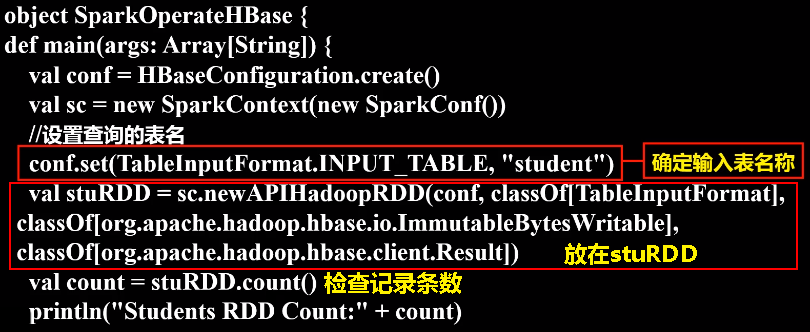
如果要让Spark读取HBase,就需要使用SparkContext提供的newAPIHadoopRDD这个API将表的内容以RDD的形式加载到Spark中。

import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase._
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf // 在SparkOperateHBase.scala文件中输入以下代码: object SparkOperateHBase {
def main(args: Array[String]) {
val conf = HBaseConfiguration.create()
val sc = new SparkContext(new SparkConf())
//设置查询的表名
conf.set(TableInputFormat.INPUT_TABLE, "student")
val stuRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
val count = stuRDD.count()
println("Students RDD Count:" + count)
stuRDD.cache()
//遍历输出
stuRDD.foreach({ case (_,result) =>
val key = Bytes.toString(result.getRow)
val name = Bytes.toString(result.getValue("info".getBytes,"name".getBytes))
val gender = Bytes.toString(result.getValue("info".getBytes,"gender".getBytes))
val age = Bytes.toString(result.getValue("info".getBytes,"age".getBytes))
println("Row key:"+key+" Name:"+name+" Gender:"+gender+" Age:"+age)
})
}
}



5.编写程序向HBase写入数据
下面编写应用程序把表中的两个学生信息插入到HBase的student表中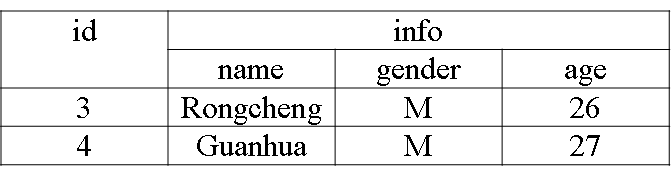
在SparkWriteHBase.scala文件中输入下面代码:
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.spark._
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.util.Bytes object SparkWriteHBase {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("SparkWriteHBase").setMaster("local")
val sc = new SparkContext(sparkConf)
val tablename = "student"
sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE, tablename)
val job = new Job(sc.hadoopConfiguration)
job.setOutputKeyClass(classOf[ImmutableBytesWritable])
job.setOutputValueClass(classOf[Result])
job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
val indataRDD = sc.makeRDD(Array("3,Rongcheng,M,26","4,Guanhua,M,27")) //构建两行记录
val rdd = indataRDD.map(_.split(',')).map{arr=>{
val put = new Put(Bytes.toBytes(arr(0))) //行健的值
put.add(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(arr(1))) //info:name列的值
put.add(Bytes.toBytes("info"),Bytes.toBytes("gender"),Bytes.toBytes(arr(2))) //info:gender列的值
put.add(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(arr(3).toInt)) //info:age列的值
(new ImmutableBytesWritable, put)
}}
rdd.saveAsNewAPIHadoopDataset(job.getConfiguration())
}
}


切换到HBase Shell中,执行如下命令查看student表


5.3 RDD编程---数据读写的更多相关文章
- Spark RDD编程-大数据课设
目录 一.实验目的 二.实验平台 三.实验内容.要求 1.pyspark交互式编程 2.编写独立应用程序实现数据去重 3.编写独立应用程序实现求平均值问题 四.实验过程 (一)pyspark交互式编程 ...
- Spark菜鸟学习营Day1 从Java到RDD编程
Spark菜鸟学习营Day1 从Java到RDD编程 菜鸟训练营主要的目标是帮助大家从零开始,初步掌握Spark程序的开发. Spark的编程模型是一步一步发展过来的,今天主要带大家走一下这段路,让我 ...
- Python之IO编程——文件读写、StringIO/BytesIO、操作文件和目录、序列化
IO编程 IO在计算机中指Input/Output,也就是输入和输出.由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口.从 ...
- Spark学习笔记2:RDD编程
通过一个简单的单词计数的例子来开始介绍RDD编程. import org.apache.spark.{SparkConf, SparkContext} object word { def main(a ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
- JavaScript高级编程———数据存储(cookie、WebStorage)
JavaScript高级编程———数据存储(cookie.WebStorage) <script> /*Cookie 读写删 CookieUtil.get()方法根据cookie的名称获取 ...
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- 5.1 RDD编程
一.RDD编程基础 1.创建 spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URL作为参数,这个URL可以是: 本地文件系统的地址 分布式文件系统HDFS的地址 ...
随机推荐
- Ambassador中,启用不同的Load balancing算法
默认就是轮循,如果要其它hash或是最少请求,那就需要作更多的设置了. https://www.getambassador.io/reference/core/load-balancer/#sourc ...
- 第50 课C++对象模型分析——成员函数(上)
类中的成员函数位于代码段中调用成员函数时对象地址作为参数隐式传递成员函数通过对象地址访问成员变量C++语法规则隐藏了对象地址的传递过程 #include<iostream> #includ ...
- Python学习笔记5 【转载】基本矩阵运算_20170618
需要 numpy 库支持 保存链接 http://www.cnblogs.com/chamie/p/4870078.html 1.numpy的导入和使用 from numpy import *;#导入 ...
- Mybatis环境搭建(二)
1. 创建Maven Project,选择war,修改pom.xml <properties> <!-- JDK版本 --> <java.version>1.8&l ...
- VMWare虚拟机提示:另一个程序已锁定文件的一部分,打不开磁盘...模块"Disk"启动失败的解决办法
重启了电脑之后,打开VMware就发现出现了“锁定文件失败,打不开磁盘......模块"Disk"启动失败.”这些文字 为什么会出现这种问题: 这是因为虚拟机在运行的时候,会锁定文 ...
- aliyun-OSS断点续传
阿里云OSS断点续传(Java版本) 在工作中发现开发的某项功能在用户网络环境差的时候部分图片无法显示,通过Review代码之后发现原来是图片上传到了国外的亚马逊服务器上,经过讨论决定将图片上传到国内 ...
- Vue indent eslint缩进webstorm冲突解决
参考教程 官方回复 ESlint设置 rules: { 'no-multiple-empty-lines': [1, {max: 3}], // 控制允许的最多的空行数量 'vue/script-in ...
- 这几款我私藏的Markdown编辑器,今天分享给你
相信很多人都使用 Markdown 来编写文章,Markdown 语法简洁,使用起来很是方便,而且各大平台几乎都已支持 Markdown 语法 那么,如何选择一款趁手的 Markdown 编辑器,就是 ...
- Java网络传输数据加密算法
算法可逆,具有跨平台特性 import java.io.IOException; import java.io.UnsupportedEncodingException; import java.se ...
- 【转】win7旗舰版英文版下载(64位|32位)|Windows7英文版ISO镜像
Win7旗舰版SP1 64位ISO镜像下载地址:文件名:en_windows_7_enterprise_with_sp1_x64_dvd_u_677651.isoSHA1:A491F985DCCFB5 ...