21、Shuffle原理剖析与源码分析
一、普通shuffle原理
1、图解
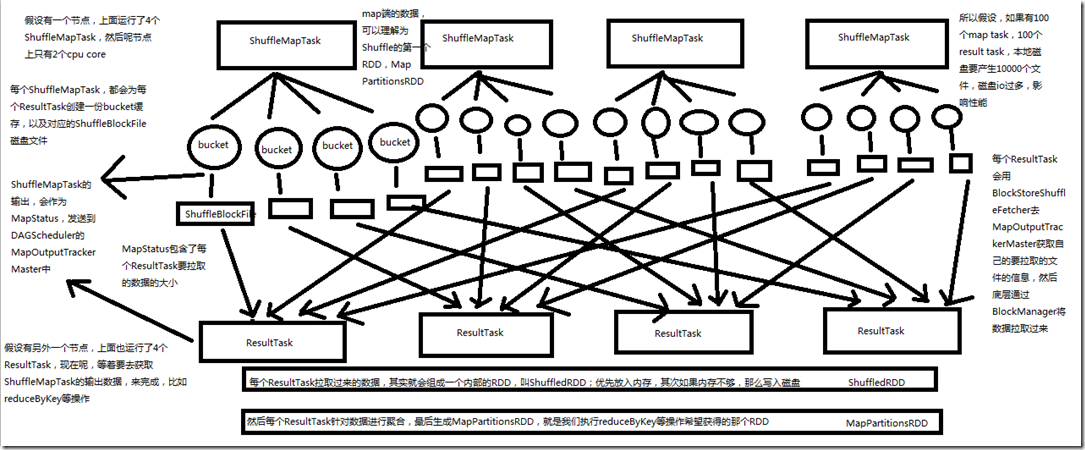
假设有一个节点上面运行了4个 ShuffleMapTask,然后这个节点上只有2个 cpu core。假如有另外一台节点,上面也运行了4个ResultTask,现在呢,正等着要去
ShuffleMapTask 的输出数据来完成比如 reduceByKey 等操作。 每个 ShuffleMapTask 都会为 ReduceTask 创建一份 bucket 缓存,以及对应的 ShuffleBlockFile 磁盘文件。 ShuffleMapTask 的输出会作为 MapStatus,发送到 DAGScheduler 的 MapOutputTrackerMaster 中。MapStatus 包含了每个 ResultTask 要拉取的数据的大小。 每个 ResultTask 会用 BlockStoreShuffleFetcher 去 MapOutputTrackerMaster 获取自己要拉取数据的信息,然后底层通过 BlockManager 将数据拉取过来。 每个 ResultTask 拉取过来的数据,其实就会组成一个内部的RDD,叫ShuffleRDD;优先放入内存,其次内存不够,那么写入磁盘。 然后每个ResultTask针对数据进行聚合,最后生成MapPartitionsRDD,也就是我们执行reduceByKey等操作希望获得的那个RDD。map端的数据,可以理解为Shuffle的第一个
RDD,MapPartitionsRDD。所以假设如果有100个map task ,100个 reduce task,本地磁盘要产生10000个文件,磁盘IO过多,影响性能。
2、Spark Shuffle操作的两个特点
第一个特点
在Spark早期版本中,那个bucket缓存是非常非常重要的,因为需要将一个ShuffleMapTask所有的数据都写入内存缓存之后,才会刷新到磁盘。但是这就有一个问题,如果
map side数据过多,那么很容易造成内存溢出。所以spark在新版本中,优化了,默认那个内存缓存是100kb,然后呢,写入一点数据达到了刷新到磁盘的阈值之后,就会
将数据一点一点地刷新到磁盘。
这种操作的优点,是不容易发生内存溢出。缺点在于,如果内存缓存过小的话,那么可能发生过多的磁盘写io操作。所以,这里的内存缓存大小,是可以根据实际的业务
情况进行优化的。 第二个特点
与MapReduce完全不一样的是,MapReduce它必须将所有的数据都写入本地磁盘文件以后,才能启动reduce操作,来拉取数据。为什么?因为mapreduce要实现默认的根
据key的排序!所以要排序,肯定得写完所有数据,才能排序,然后reduce来拉取。
但是Spark不需要,spark默认情况下,是不会对数据进行排序的。因此ShuffleMapTask每写入一点数据,ResultTask就可以拉取一点数据,然后在本地执行我们定义的聚合
函数和算子,进行计算。
spark这种机制的好处在于,速度比mapreduce快多了。但是也有一个问题,mapreduce提供的reduce,是可以处理每个key对应的value上的,很方便。但是spark中,由于这
种实时拉取的机制,因此提供不了,直接处理key对应的values的算子,只能通过groupByKey,先shuffle,有一个MapPartitionsRDD,然后用map算子,来处理每个key对应的
values。就没有mapreduce的计算模型那么方便。
二、优化后的shuffle原理
1、图解
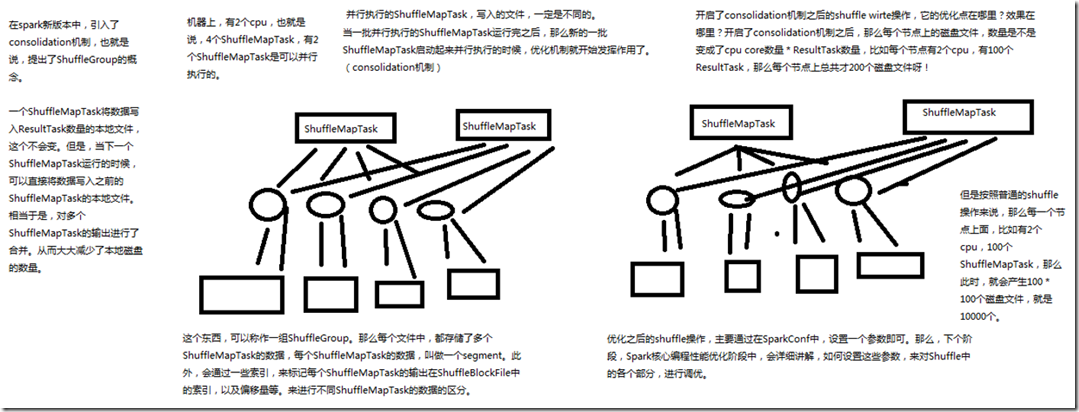
在spark新版本中,引入了 consolidation 机制,也就是说提出了ShuffleGroup的概念。一个 ShuffleMapTask 将数据写入 ResultTask 数量的本地文本,这个不会变。但是,
当下一个 ShuffleMapTask 运行的时候,可以直接将数据写入之前的 ShuffleMapTask 的本地文件。相当于是,对多个 ShuffleMapTask 输出做了合并,从而大大减少了本地
磁盘的数量。 假设一台机器上有两个 cpu ,也就是说,4个 ShuffleMapTask,有2个ShuffleMapTask是可以并行执行的。并行执行的 ShuffleMapTask ,写入的文件,一定是不同的。当一
批并行执行的 ShuffleMapTask 运行完之后,那么新的一批 ShuffleMapTask 启动起来并执行的时候,优化机制就开始发挥作用了(consolidation机制)。这个东西,就可以
称作为一组 ShuffleGroup。那么每个文件中,都存储了多个 ShuffleMapTask 的数据,每个 ShuffleMapTask 的数据 ,叫做一个 segment,此外,会通过一些索引,来标记每
个 ShuffleMapTask 的输出在 ShuffleBlockFlie 中的索引,以及偏移量等,来进行不同 ShuffleMapTask 的数据的区分。 开启了 consolidation 机制之后的 shuffle write 操作,它的优化点在哪里?效果在哪里? 开启了 consolidation 机制之后,那么每个节点上的磁盘文件,数量是不是变成了 cpu core 数量* ResultTask数量,比如每个节点有2个 cpu,有100个 ResultTask,那么每个
节点上总共才200 个磁盘文件呀!但是按照普通的 shuffle 操作来说,那么第一个节点上面,比如每个节点有2个 cpu,有100个 ShuffleMapTask,那么此时就会产生100*100
个磁盘文件,就是1000个。 优化之后的 shuffle 操作,主要通过在 SparkConf 中设置一个参数即可。
三、shuffle源码分析
1、shuffle写
###org.apache.spark.shuffle.hash/HashShuffleWriter.scala // 将每个ShuffleMapTask计算出来的新的rdd的partition数据,写入本地磁盘
override def write(records: Iterator[_ <: Product2[K, V]]): Unit = {
// 首先判断,是否需要再map端本地进行聚合,这里的话,如果是reduceByKey这种操作,它的dep.aggregator.isDefined、dep.mapSideCombine都是true
// 那么就会进行map端的本地聚合
val iter = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
// 这里就会执行本地聚合,比如本地有(hello,1)、(hello,1),那么此时就会聚合成(hello,2)
dep.aggregator.get.combineValuesByKey(records, context)
} else {
records
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
records
} // 需要本地聚合,那么先本地聚合,然后遍历数据,对每个数据,调用partitioner,默认是HashPartitioner
// 生成bucketId,也就是决定了,每一份数据,要写入哪个bucket中
for (elem <- iter) {
val bucketId = dep.partitioner.getPartition(elem._1)
// 获取到了bucketId之后,会调用shuffleBlockManager.forMapTask()方法,来生成bucketId对应的writer,然后用writer将数据写入bucket
shuffle.writers(bucketId).write(elem)
}
} ###org.apache.spark.shuffle/FileShuffleBlockManager.scala // 给每一个mao task 获取一个ShuffleWriterGroup
def forMapTask(shuffleId: Int, mapId: Int, numBuckets: Int, serializer: Serializer,
writeMetrics: ShuffleWriteMetrics) = {
new ShuffleWriterGroup {
shuffleStates.putIfAbsent(shuffleId, new ShuffleState(numBuckets))
private val shuffleState = shuffleStates(shuffleId)
private var fileGroup: ShuffleFileGroup = null // 对应之前讲解的,shuffle有两种模式,一种是普通的,一种是优化后的
// 这里会判断,如果开启了consolidation机制,也就是consolidateShuffleFiles为true的话,那么实际上,不会给每个bucket都获取一个独立的文件
// 而是为这个bucket获取一个ShuffleGroup的writer
val writers: Array[BlockObjectWriter] = if (consolidateShuffleFiles) {
fileGroup = getUnusedFileGroup()
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
// 首先,用shuffleId、mapId、bucketId(也就是reduceId,一个bucket对应一个reduce)生成一个唯一的ShuffleBlockId
// 然后用buckId,来调用ShuffleFileGroup的apply()函数,为bucket获取一个ShuffleFileGroup
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
// 然后调用BlockManager的getDiskWriter()方法,针对ShuffleFileGroup获取一个writer
// 这里,就明白了,如果开启了consolidation机制,实际上,对于每一个bucket,都会获取一个针对ShuffleFileGroup的wtriter,而不是一个独立的ShuffleBlockFile的writer
// 这样就实现了所谓的,多个ShuffleMapTask的输出数据的合并
blockManager.getDiskWriter(blockId, fileGroup(bucketId), serializer, bufferSize,
writeMetrics)
}
} else {
// 如果没有开启consolidation机制,也就是普通的shuffle操作的话
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
// 同样生成一个ShuffleBlockId
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
// 然后调用BlockManager的diskBlockManager,获取一个代表了要写入本地磁盘文件的blockFile
val blockFile = blockManager.diskBlockManager.getFile(blockId)
// Because of previous failures, the shuffle file may already exist on this machine.
// If so, remove it.
// 而且会判断,如果blockFile要是存在的话,还得删除它
if (blockFile.exists) {
if (blockFile.delete()) {
logInfo(s"Removed existing shuffle file $blockFile")
} else {
logWarning(s"Failed to remove existing shuffle file $blockFile")
}
}
// 然后调用BlockManager的getDiskWriter()方法,针对那个blockFile生成writer
blockManager.getDiskWriter(blockId, blockFile, serializer, bufferSize, writeMetrics)
}
// 所以使用这种普通的shuffle操作的话,对于每一个ShuffleMapTask输出的bucket,都会在本地获取一个单独的ShuffleBlockFile
}
2、shuff读
入口
###org.apache.spark.rdd/ShuffledRDD.scala override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
// ResultTask或者ShuffleMapTask在执行到ShuffleRDD时,肯定会调用ShuffleRDD的computer()方法,来计算当前这个RDD的partition的数据
// 在这里,会调用ShuffleManager的getReader()方法,获取一个HashShuffleReader,然后调用它的read()方法,拉取该ResultTask / ShuffleMapTask需要聚合的数据
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
} ###org.apache.spark.shuffle.hash/HashShuffleReader.scala /** Read the combined key-values for this reduce task */
override def read(): Iterator[Product2[K, C]] = {
val ser = Serializer.getSerializer(dep.serializer)
// reduceTask在拉取数据时,其实会用BlockStoreShuffleFetcher来从DAGDcheduler的MapOutputTrackerMaster中获取自己想要的数据的信息
// 然后底层,再通过blockManager从对应的位置,拉取需要的数据
val iter = BlockStoreShuffleFetcher.fetch(handle.shuffleId, startPartition, context, ser) val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
new InterruptibleIterator(context, dep.aggregator.get.combineCombinersByKey(iter, context))
} else {
new InterruptibleIterator(context, dep.aggregator.get.combineValuesByKey(iter, context))
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!") // Convert the Product2s to pairs since this is what downstream RDDs currently expect
iter.asInstanceOf[Iterator[Product2[K, C]]].map(pair => (pair._1, pair._2))
} // Sort the output if there is a sort ordering defined.
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled,
// the ExternalSorter won't spill to disk.
val sorter = new ExternalSorter[K, C, C](ordering = Some(keyOrd), serializer = Some(ser))
sorter.insertAll(aggregatedIter)
context.taskMetrics.incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics.incDiskBytesSpilled(sorter.diskBytesSpilled)
sorter.iterator
case None =>
aggregatedIter
}
} ###org.apache.spark.shuffle.hash/BlockStoreShuffleFetcher.scala private[hash] object BlockStoreShuffleFetcher extends Logging {
def fetch[T](
shuffleId: Int,
reduceId: Int,
context: TaskContext,
serializer: Serializer)
: Iterator[T] =
{
logDebug("Fetching outputs for shuffle %d, reduce %d".format(shuffleId, reduceId))
// 拿到全局的blockManager
val blockManager = SparkEnv.get.blockManager val startTime = System.currentTimeMillis
// 拿到一个全局的MapOutputTracker的引用,调用其getServerStatuses()方法,传入了shuffleId和reduceId
// shuffleId可以代表当前这个stage的上一个stage,shuffle是分为两个stage的,shuffle writer发生在上一个stage中,shuffle read 是发生在当前stage中的
// 首先通过shuffleId可以限制到上一个stage的所有ShuffleMapTask的输出的MapStatus,接着,通过reduceId,也就是所谓的bucketId,来限制,从每个mapTask中,获取当前这个resultTask需要获取的每个ShuffleMapTask的输出文件的信息
// getServerStatuses()方法,一定是走远程网络通信的,因为要联系Driver上的DAGScheduler的MapOutputTrackerMaster
val statuses = SparkEnv.get.mapOutputTracker.getServerStatuses(shuffleId, reduceId)
logDebug("Fetching map output location for shuffle %d, reduce %d took %d ms".format(
shuffleId, reduceId, System.currentTimeMillis - startTime)) // 对刚才拉取的数据,进行一些数据结构上的转换操作
val splitsByAddress = new HashMap[BlockManagerId, ArrayBuffer[(Int, Long)]]
for (((address, size), index) <- statuses.zipWithIndex) {
splitsByAddress.getOrElseUpdate(address, ArrayBuffer()) += ((index, size))
} val blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = splitsByAddress.toSeq.map {
case (address, splits) =>
(address, splits.map(s => (ShuffleBlockId(shuffleId, s._1, reduceId), s._2)))
} def unpackBlock(blockPair: (BlockId, Try[Iterator[Any]])) : Iterator[T] = {
val blockId = blockPair._1
val blockOption = blockPair._2
blockOption match {
case Success(block) => {
block.asInstanceOf[Iterator[T]]
}
case Failure(e) => {
blockId match {
case ShuffleBlockId(shufId, mapId, _) =>
val address = statuses(mapId.toInt)._1
throw new FetchFailedException(address, shufId.toInt, mapId.toInt, reduceId, e)
case _ =>
throw new SparkException(
"Failed to get block " + blockId + ", which is not a shuffle block", e)
}
}
}
}
// ShuffleBlockFetcherIterator构造以后,在其内部,就直接根据拉取到的地理位置信息,通过BlockManager去远程ShuffleMapTask所在的节点的BlockManager去拉取数据
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
SparkEnv.get.blockManager.shuffleClient,
blockManager,
blocksByAddress,
serializer,
SparkEnv.get.conf.getLong("spark.reducer.maxMbInFlight", 48) * 1024 * 1024)
val itr = blockFetcherItr.flatMap(unpackBlock) // 最后,将拉取到的数据,执行一些转换和封装,返回
val completionIter = CompletionIterator[T, Iterator[T]](itr, {
context.taskMetrics.updateShuffleReadMetrics()
}) new InterruptibleIterator[T](context, completionIter) {
val readMetrics = context.taskMetrics.createShuffleReadMetricsForDependency()
override def next(): T = {
readMetrics.incRecordsRead(1)
delegate.next()
}
}
}
}
21、Shuffle原理剖析与源码分析的更多相关文章
- 65、Spark Streaming:数据接收原理剖析与源码分析
一.数据接收原理 二.源码分析 入口包org.apache.spark.streaming.receiver下ReceiverSupervisorImpl类的onStart()方法 ### overr ...
- 18、TaskScheduler原理剖析与源码分析
一.源码分析 ###入口 ###org.apache.spark.scheduler/DAGScheduler.scala // 最后,针对stage的task,创建TaskSet对象,调用taskS ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- 22、BlockManager原理剖析与源码分析
一.原理 1.图解 Driver上,有BlockManagerMaster,它的功能,就是负责对各个节点上的BlockManager内部管理的数据的元数据进行维护, 比如Block的增删改等操作,都会 ...
- 64、Spark Streaming:StreamingContext初始化与Receiver启动原理剖析与源码分析
一.StreamingContext源码分析 ###入口 org.apache.spark.streaming/StreamingContext.scala /** * 在创建和完成StreamCon ...
- 20、Task原理剖析与源码分析
一.Task原理 1.图解 二.源码分析 1. ###org.apache.spark.executor/Executor.scala /** * 从TaskRunner开始,来看Task的运行的工作 ...
- 19、Executor原理剖析与源码分析
一.原理图解 二.源码分析 1.Executor注册机制 worker中为Application启动的executor,实际上是启动了这个CoarseGrainedExecutorBackend进程: ...
- 23、CacheManager原理剖析与源码分析
一.图解 二.源码分析 ###org.apache.spark.rdd/RDD.scalal ###入口 final def iterator(split: Partition, context: T ...
- 16、job触发流程原理剖析与源码分析
一.以Wordcount为例来分析 1.Wordcount val lines = sc.textFile() val words = lines.flatMap(line => line.sp ...
随机推荐
- Centos7 在线安装开发环境 jdk1.8+mysql+tomcat
写在最前 刚刚开始接触Linux,并折腾着在服务器上部署自己的项目,当然作为一个后端开发人员,必不可少的东西肯定是 JDK Mysql Tomcat容器 每天记录一天,每天进步一点点~~ 1.更新系统 ...
- 配置Setting.xml文件提高maven更新下载jar包速度
<?xml version="1.0" encoding="UTF-8"?> <settings xmlns="http://mav ...
- 常用的MySQL命令
1.新建数据库: create database person; 2.使用数据库 use person: 3.创建一个表格 create table student ( id int(10) not ...
- Ubuntu 下安装 OpenSSH Server
Ubuntu 下安装 OpenSSH Server 是无比轻松的一件事情,需要的命令只有一条: sudo apt-get install openssh-server (查看返回的结果,如果没有出错, ...
- 博客使用 utterances 作为评论系统
utterances 是一款基于 GitHub issues 的评论工具. 相比同类的工具 gitment.gitalk 以及 disqus 评论工具,优点如下: 极其轻量 加载非常快 配置比较简单 ...
- DataPipeline的增量数据支持回滚功能
DataPipeline的增量数据支持回滚功能 第一步:数据任务有增量数据时,回滚按钮激活,允许用户使用该功能进行数据回滚. 第二步:点击回滚按钮,允许用户选择回滚时间或者回滚位置进行数据回滚.选择按 ...
- Android里的Dalvik、ART、JIT、AOT有什么关系?
JIT,Just-in-time,即时编译,边运行边编译: AOT,Ahead Of Time,提前编译,指运行前编译. 区别 这两种编译方式的主要区别在于是否在“运行时”进行编译 优劣JIT优点: ...
- SQL PLUS 远程连接数据库
-- SQL PLUS 远程连接Oracle数据库(WINDOWS+SQL PLUS)命令:用户名/密码@ip地址[:端口]/service_name [as sysdba] EG: ORCL/ORC ...
- 交互式计算引擎REOLAP篇
交互式计算引擎ROLAP篇 摘自:<大数据技术体系详解:原理.架构与实践> 一.Impala Impala最初由Cloudera公司开发的,其最初设计动机是充分结合传统数据库与大数据系 ...
- JavaSE字符串日期与时间拼接小列子与JSON小列子
1.在对象中有个字段为Timestamp类型,需要将数据库的开始日期字段和开始时间字段拼接成一个字段开始字段 private static Timestamp getDateTime(String d ...