Hadoop(五)—— HDFS NameNode、DataNode工作机制
一、NN与2NN工作机制
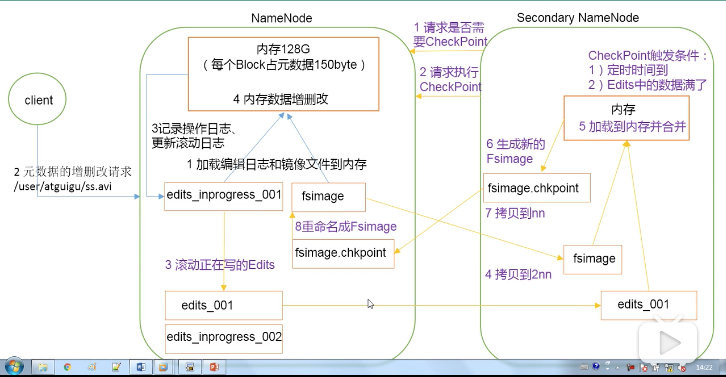
NameNode(NN)
1、当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中。
2-4、当元数据的增删改查请求进来时,NameNode会先将操作记录到日志中,之后再执行内存数据的增删改查
SecondNameNode(2NN)
1、SecondNameNode请求NameNode,请求是否需要checkPoint,checkPoint的触发条件:
- 定时时间到
- 日志文件满了
2-6、请求checkPoint,会将最近写的edits和fsImage拷贝到SecondNameNode本地,加载到内存中合并,生成fsImage.checkpoint。
7-8 将fsImage.checkpoint拷贝到NameNode,并更名为fsImage
二、Fs Image与Edits解析
到/usr/local/hadoop/Hadoop_tmp/dfs/name/current查看日志和fsImage

查看fsImage
hdfs oiv -p XML -i fsimage_0000000000000000131 -o fsimage.xml
得到结果
<?xml version="1.0"?>
<fsimage><NameSection>
<genstampV1>1000</genstampV1><genstampV2>1006</genstampV2><genstampV1Limit>0</genstampV1Limit><lastAllocatedBlockId>1073741829</lastAllocatedBlockId><txid>131</txid></NameSection>
<INodeSection><lastInodeId>16424</lastInodeId><inode><id>16385</id><type>DIRECTORY</type><name></name><mtime>1576421043641</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>9223372036854775807</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16386</id><type>DIRECTORY</type><name>fzj</name><mtime>1575714994678</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16387</id><type>DIRECTORY</type><name>jiagoushi</name><mtime>1575714994678</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16392</id><type>DIRECTORY</type><name>tmp</name><mtime>1576021083427</mtime><permission>fangzhijie:supergroup:rwx-wx-wx</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16393</id><type>DIRECTORY</type><name>hive</name><mtime>1576021083443</mtime><permission>fangzhijie:supergroup:rwx-wx-wx</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16394</id><type>DIRECTORY</type><name>fangzhijie</name><mtime>1576022280367</mtime><permission>fangzhijie:supergroup:rwx------</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16411</id><type>DIRECTORY</type><name>user</name><mtime>1576021954868</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16412</id><type>DIRECTORY</type><name>hive</name><mtime>1576021954868</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16413</id><type>DIRECTORY</type><name>warehouse</name><mtime>1576021954868</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16414</id><type>DIRECTORY</type><name>bigdata</name><mtime>1576021954868</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16417</id><type>DIRECTORY</type><name>test</name><mtime>1576326634124</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16418</id><type>DIRECTORY</type><name>hdfs</name><mtime>1576327378643</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16419</id><type>DIRECTORY</type><name>client</name><mtime>1576326634124</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16420</id><type>DIRECTORY</type><name>client1</name><mtime>1576327180252</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16421</id><type>DIRECTORY</type><name>client2</name><mtime>1576327378643</mtime><permission>fangzhijie:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16422</id><type>FILE</type><name>hdfs-test123456.xml</name><replication>3</replication><mtime>1576327781065</mtime><atime>1576327780439</atime><perferredBlockSize>134217728</perferredBlockSize><permission>fangzhijie:supergroup:rw-r--r--</permission><blocks><block><id>1073741827</id><genstamp>1004</genstamp><numBytes>878</numBytes></block>
</blocks>
</inode>
<inode><id>16423</id><type>FILE</type><name>hdfs-test123.xml</name><replication>2</replication><mtime>1576418894630</mtime><atime>1576418893994</atime><perferredBlockSize>134217728</perferredBlockSize><permission>fangzhijie:supergroup:rw-r--r--</permission><blocks><block><id>1073741828</id><genstamp>1005</genstamp><numBytes>878</numBytes></block>
</blocks>
</inode>
</INodeSection>
<INodeReferenceSection></INodeReferenceSection><SnapshotSection><snapshotCounter>0</snapshotCounter></SnapshotSection>
<INodeDirectorySection><directory><parent>16385</parent><inode>16386</inode><inode>16423</inode><inode>16422</inode><inode>16417</inode><inode>16392</inode><inode>16411</inode></directory>
<directory><parent>16386</parent><inode>16387</inode></directory>
<directory><parent>16392</parent><inode>16393</inode></directory>
<directory><parent>16393</parent><inode>16394</inode></directory>
<directory><parent>16411</parent><inode>16412</inode></directory>
<directory><parent>16412</parent><inode>16413</inode></directory>
<directory><parent>16413</parent><inode>16414</inode></directory>
<directory><parent>16417</parent><inode>16418</inode></directory>
<directory><parent>16418</parent><inode>16419</inode><inode>16420</inode><inode>16421</inode></directory>
</INodeDirectorySection>
<FileUnderConstructionSection></FileUnderConstructionSection>
<SnapshotDiffSection><diff><inodeid>16385</inodeid></diff></SnapshotDiffSection>
<SecretManagerSection><currentId>0</currentId><tokenSequenceNumber>0</tokenSequenceNumber></SecretManagerSection><CacheManagerSection><nextDirectiveId>1</nextDirectiveId></CacheManagerSection>
</fsimage>
查看日志文件
hdfs oev -p XML -i edits_0000000000000000130-0000000000000000131 -o edits.xml
得到结果
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>130</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_END_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>131</TXID>
</DATA>
</RECORD>
</EDITS>
三、NameNode故障处理
方案一
kill掉NameNode进程
将SecondNameNode的数据拷贝到NameNode中
重启NameNode
方案二
使用-importCheckpoint选项启动NameNode守护进程,从而将SecondNameNode中数据拷贝到NameNode目录中。
kill -9 NameNode
删除NameNode存储的数据
将SecondNameNode的数据拷贝到NameNode中
四、安全模式
NameNode进入安全模式的话,文件系统是只读的。
如何判断是否是进入安全模式
▶ ./hdfs dfsadmin -safemode get
19/12/21 23:44:39 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Safe mode is OFF
进入安全模式
local/hadoop/bin
▶ ./hdfs dfsadmin -safemode enter
19/12/21 23:53:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Safe mode is ON
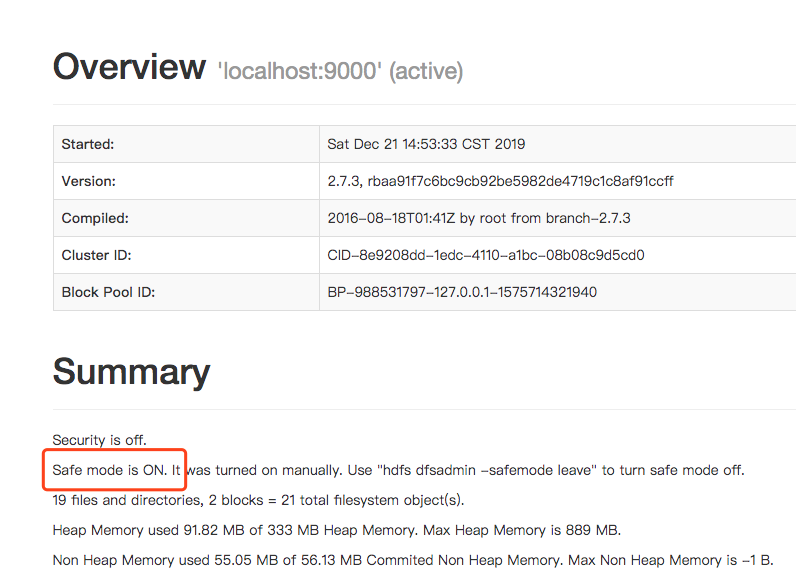
退出安全模式
./hdfs dfsadmin -safemode leave
等待安全模式
./hdfs dfsadmin -safemode wait
等待的意思是,在安全模式状态是ON的时候,阻塞,直到状态变为OFF,阻塞才取消,开始执行后续的操作。
五、NameNode 高可用
dir
六、NameNode的ZKFC机制
dir
七、数据完整性
循环冗余校验(CRC)码
使用CRC校验码来保证数据的完整性。
CRC 算法的基本思想:将传输的数据当做一个位数很长的数。将这个数除以另一个数。得到的余数作为校验数据附加到原数据后面。
CRC码中,校验位(R位)在信息位(K位)后面.
例如,CRC生成多项式为G(X) = X4 + X + 1,要求出二进制序列10110011的CRC校验码。
多项式对应的二进制为10011
10011 为除数,10110011为被除数,按照异或的计算方式,同为0,异为1,则计算过程如下:
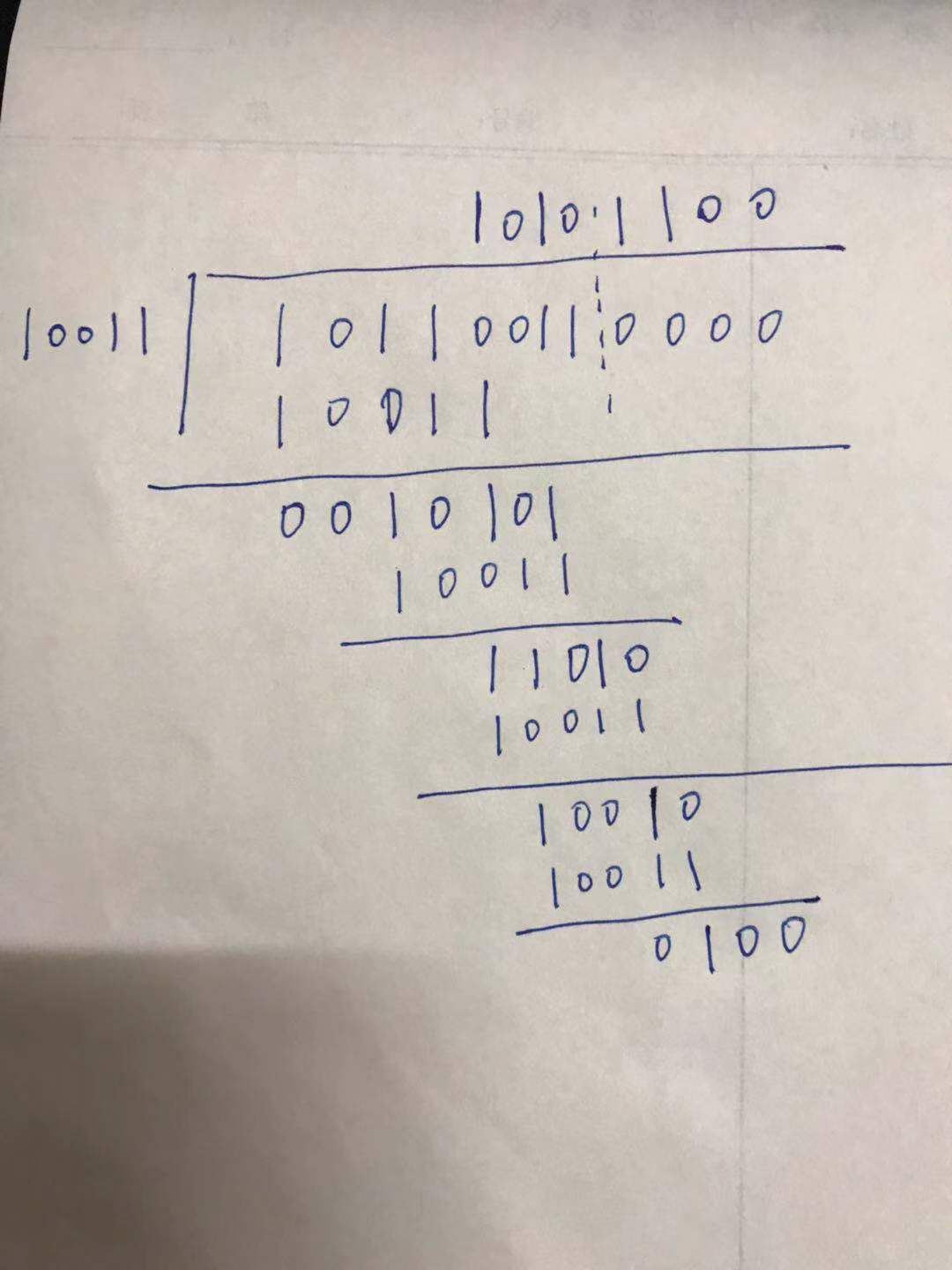
最后得到余数0100,即是校验位。那么整个CRC码为:10110011 0100
参考文档
循环冗余校验(CRC)码
HDFS:NameNode的Proxy该怎样做
字节跳动 EB 级 HDFS 实践
Hadoop(五)—— HDFS NameNode、DataNode工作机制的更多相关文章
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
- HDFS中DataNode工作机制
1.DataNode工作机制 1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,块数据的校验和,以及时间戳). 2)DataNod ...
- HDFS Namenode&Datanode
HDFS Namenode&Datanode HDFS 机制粗略示意图 客户端写入文件流程: NN && DN Namenode(NN)工作机制 NN是整个文件系统的管理节点. ...
- DataNode 工作机制
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_35641192/article/d ...
- Hadoop(10)-HDFS的DataNode详解
1.DataNode工作机制 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳. 2)DataNode启 ...
- Hadoop框架:DataNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.工作机制 1.基础描述 DataNode上数据块以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块元数据包括长度.校验.时 ...
- Hadoop:HDFS NameNode内存全景
原文转自:https://tech.meituan.com/namenode.html 感谢原作者 一.概述 从整个HDFS系统架构上看,NameNode是其中最重要.最复杂也是最容易出现问题的地方, ...
- hdfs的datanode工作原理
datanode的作用: (1)提供真实文件数据的存储服务. (2)文件块(block):最基本的存储单位.对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序 ...
- Hadoop_10_HDFS 的 DataNode工作机制
1.DataNode的工作机制: 1.DataNode工作职责:存储管理用户的文件块数据 定期向namenode汇报自身所持有的block信息(通过心跳信息上报) (这点很重要,因为,当集群中发生某 ...
随机推荐
- kafka汇总
Kafka 1. kafka概念 kafka是一个高吞吐亮的.分布式.基于发布/订阅(也就是一对多)的消息系统,最初由Linkedln公司开发的,使用Scala语言编写的,目前是Apache的开源项目 ...
- 仿EXCEL插件,智表ZCELL产品V1.7 版本发布,增加自定义右键菜单功能
详细请移步 智表(ZCELL)官网www.zcell.net 更新说明 这次更新主要应用户要求,主要解决了自定义右键菜单事件的支持,并新增了公式中自定义函数传参.快捷键剪切等功能,欢迎大家体验使用. ...
- 当ABAP遇见普罗米修斯
Jerry每次在工作场合中同Prometheus(普罗米修斯)打交道时,都会"出戏",因为这个单词给我的第一印象,并不是用go语言实现的微服务监控利器,而是名导雷德利·斯科特(Ri ...
- PageRank网页价值算法
一.简介 PageRank是Google提出的算法,用于衡量特定网页相对于其它网页而言的重要程度.是Google创始人拉里.佩奇和谢尔盖.布林于1997年创造的,用于实现将链接价值概念作为排名的重要因 ...
- 《我是一只IT小小鸟》(续)读书笔记——第八周
第三位作者强调了大学阶段规划的重要性,作者初入大学,一切都很新鲜想尝试,却缺乏对学习生活的规划.最终导致的是学习成绩的下降.其实编程也是一样,我们常常感到自己和那些大神的差距,感慨过后,往往也就罢了. ...
- 构建nodejs环境
总想留下点东西,不负年华! 00.download releasehttps://nodejs.org/dist/ //all release example https://nodejs. ...
- 【转】golang-defer坑的本质
本文节选自https://tiancaiamao.gitbooks.io/go-internals/content/zh/03.4.html 作者的分析非常透彻,从问题本质分析,就不会对defer产生 ...
- HTML常用全部代码--第一部分--HTML/CSS( 小伙伴要牢记😁😁😁😁 )
<一>html代码大全:结构性定义 (1) 文件类型<HTML></HTML> (放在档案的开头与结尾) (2) 文件主题<TITLE></TIT ...
- 微信小程序~tabBar和navigator一起使用无效
1.当注册了tabBar的时候,使用navigator时会发现不能跳转,这个时候需要在navigator上加上open-type=’switchTab’ 属性 <navigator open-t ...
- myslq数据库用union all查询出现 #1271 - Illegal mix of collations for operation 'UNION'
出现 #1271 - Illegal mix of collations for operation 'UNION' 的原因是两个字符编码不匹配造成的. 我遇到的是 utf8_general_ci ...