爬虫requests库 之爬虫贴吧
首先要观察爬虫的URL规律,爬取一个贴吧所有页的数据,观察点击下一页时URL是如何变化的。
思路:
定义一个类,初始化方法什么都不用管
定义一个run方法,用来实现主要逻辑
3 class TiebaSpider():
4 def __init__(self):
5 pass
6
7
8 def run(self): # 实现主要逻辑
9 # 1、构造url列表
10 # 2、遍历列表发送请求,获取响应
11 # 3、保存html页面到本地
思路:
观察要爬取的贴吧URL规律:转化URL,https://tieba.baidu.com/f?kw=李毅&ie=utf-8&pn=0 如果第一页看不出规律,点下一页观察,然后再回到第一页,第一页再次出现的URL会与最开始有所不同。
第一页pn=0,每次点击下一页,pn就会+50
把url_temp放到init方法中,会变化的地方pn先用大括号占位,还有贴吧名称会变化,后面需要传递参数过来,所以init方法中还需要写个形参tieba_name,这个参数是通过最下方的if name ==“main”:来传递的
self.url_temp = “https://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}”
3 class TiebaSpider():
4 def __init__(self,tieba_name):
5 self.url_temp = "https://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}"
6
14
15 def run(self): # 实现主要逻辑
16 # 1、构造url列表
17 # 2、遍历列表发送请求,获取响应
18 # 3、保存html页面到本地
19
20
21 if __name__ == "__main__":
22 tieba_spider = TiebaSpider("李毅")
思路:
run方法中的逻辑框架搭建完成后,分别对每个步骤再定义一个方法
构造url列表,定义一个get_url_list方法,利用for循环,然后用return返回循环完成的列表,return是在for循环体外。构造完之后在run方法中调用一下get_url_list,就得到了一个url列表。
接下来完成run方法中的第二步,遍历列表发送请求,获取响应。for url in url_list:
遍历列表用for循环,发送请求获取响应也可以定义一个方法,然后放到for循环体内。
3 class TiebaSpider():
4 def __init__(self,tieba_name):
5 self.url_temp = "https://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}"
6
7
8 def get_url_list(self):
9 """构造url列表,获取贴吧1-1000页的内容"""
10 url_list = []
11 for i in range (1000):
12 url_list.append(self.url_temp.format(i*50))
13 return url_list
14
15
19 def run(self): # 实现主要逻辑
20 # 1、构造url列表
21 url_list = self.get_url_list()
22 # 2、遍历列表发送请求,获取响应
23 for url in url_list:
24
25 # 3、保存html页面到本地
26
27
28 if __name__ == "__main__":
29 tieba_spider = TiebaSpider("李毅")
思路:
去定义run方法中第二步的一个方法def parse_url(self):用来发送请求获取响应。
定义的所有方法中,都默认带一个self参数,如果还需要传递其它参数,就继续放进去
response = requests.get(url,headers=)用来获取响应,此时用到了requests,需要导入模块,还用到了url变量,需要传递过来,所以要在def parse_url(self)中传递一个形参url,变成def parse_url(self,url),此时还用到一个headers,可以定义一个字典headers并给它赋值,值可以通过进入贴吧右击检查从Network-Name-Headers-Request Headers中获取,只需赋值User-Agent键值对即可,然后加双引号构造成字典。headers字典变量可以放在定义的def parse_url(self,url)方法上方,也可以放在 def init(self,tieba_name)方法内,放在init方法内需要写成self.headers=字典。然后return response.content.decode()返回响应的字符串。
然后在run方法中调用def parse_url(self,url)函数,调用时方法前加self,同时传递url参数进去,用变量html_str接收。
1 import requests
2
3 class TiebaSpider():
4 def __init__(self,tieba_name):
5 self.url_temp = "https://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}"
6 self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36"}
7
8 def get_url_list(self):
9 """构造url列表,获取贴吧1-1000页的内容"""
10 url_list = []
11 for i in range (1000):
12 url_list.append(self.url_temp.format(i*50))
13 return url_list
14
15
16 def parse_url(self,url):
17 response = requests.get(url,headers=self.headers)
18 return response.content.decode()
19
20
21 def run(self): # 实现主要逻辑
22 # 1、构造url列表
23 url_list = self.get_url_list()
24 # 2、遍历列表发送请求,获取响应
25 for url in url_list:
26 html_str = self.parse_url(url)
27 # 3、保存html页面到本地
28
29
30 if __name__ == "__main__":
31 tieba_spider = TiebaSpider("李毅")
思路:
完成第三步,保存,定义一个save_html()方法
with open("","") as f: 第一个参数是位置,第二个是写入方法。
对保存的html进行格式化,“李毅-第1页”,李毅和X页都是会变化的,设置一个变量:file_path = “{}-第{}页.html”.format(),format中需要传递两个参数,第一个参数不能直接用tieba_name或者self.tieba_name,因为self没有tieba_name,self是TiebaSpider的一个实例,所以去init中定义一个self.tieba_name = tieba_name,此时,format中的第一个参数就可以写self.tieba_name了。format还需要第二个参数,所以给save_html()传递一个page_num参数。然后再f.write(html_str),把上一步获取的html_str写进去就可以了。
注意,open()中的第一个参数file_path不加引号,write()中的参数html_str没有引号。
1 import requests
2
3 class TiebaSpider():
4 def __init__(self,tieba_name):
5 self.tieba_name = tieba_name
6 self.url_temp = "https://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}"
7 self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36"}
8
9 def get_url_list(self):
10 """构造url列表,获取贴吧1-1000页的内容"""
11 url_list = []
12 for i in range (1000):
13 url_list.append(self.url_temp.format(i*50))
14 return url_list
15
16
17 def parse_url(self,url):
18 response = requests.get(url,headers=self.headers)
19 return response.content.decode()
20
21
22 def save_html(self,html_str,page_num):
23 """保存html字符串"""
24 file_path = "{}-第{}页".format(self.tieba_name,page_num)
25 with open (file_path,"w") as f: # "李毅吧-第1页"做成格式化
26 f.write(html_str)
27
28
29
30 def run(self): # 实现主要逻辑
31 # 1、构造url列表
32 url_list = self.get_url_list()
33 # 2、遍历列表发送请求,获取响应
34 for url in url_list:
35 html_str = self.parse_url(url)
36 # 3、保存html页面到本地
37
38
39 if __name__ == "__main__":
40 tieba_spider = TiebaSpider("李毅")
思路:
接下来在run中调用刚才定义的save_html方法,run中的第三步保存html页面到本地也应放在for循环体内。
调用save_html时需要传递两个参数,因为save_html方法中用到了,所以这里需要传递过去。一个是html_str,这个是上一步得到的,已经有了,可以直接传,还有一个page_num,这个还没有,需要现在定义,page_num = url_list.index(url)+1,页码数就是当前url在url列表中的地址,但因为列表的地址是从0开始的,也就是说第一个url的位置是0,所以后面要加1.
接下来就可以调用run方法了,此处的run方法相当于之前学习定义的main函数,只是换了一个名字而已。
1 import requests
2
3 class TiebaSpider():
4 def __init__(self,tieba_name):
5 self.tieba_name = tieba_name
6 self.url_temp = "https://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}"
7 self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36"}
8
9 def get_url_list(self):
10 """构造url列表,获取贴吧1-1000页的内容"""
11 url_list = []
12 for i in range (1000):
13 url_list.append(self.url_temp.format(i*50))
14 return url_list
15
16
17 def parse_url(self,url):
18 print(url)
19 response = requests.get(url,headers=self.headers)
20 return response.content.decode()
21
22
23 def save_html(self,html_str,page_num):
24 """保存html字符串"""
25 file_path = "{}-第{}页.html".format(self.tieba_name,page_num)
26 with open (file_path,"w",encoding="utf-8") as f: # "李毅吧-第1页"做成格式化
27 f.write(html_str)
28
29
30
31 def run(self): # 实现主要逻辑
32 # 1、构造url列表
33 url_list = self.get_url_list()
34 # 2、遍历列表发送请求,获取响应
35 for url in url_list:
36 html_str = self.parse_url(url)
37 # 3、保存html页面到本地
38 page_num = url_list.index(url)+1
39 self.save_html(html_str,page_num)
40
41
42 if __name__ == "__main__":
43 tieba_spider = TiebaSpider("李毅") # 创建一个类对象
44 tieba_spider.run()无锡看妇科哪里好 http://www.xasgfk.cn/
接下来可以测试程序,但是不会有任何现象,可以在parse_url方法下的第一行代码加一个print,用print打印一下当前的url,看跑到了哪个url。
debug注意:
所有的方法,包括run,一定要写在 class
TiebaSpider():下,一定要缩进,不能和类左对齐,因为这些方法都是类方法,否则运行时会提示AttributeError:
‘TiebaSpider’ object has no attribute ‘run’
with open (file_path,“w”,encoding=“utf-8”) as f: # "李毅吧-第1页"做成格式化
f.write(html_str)
如果报错, 一定要写上encoding=“utf-8”
面向对象知识复习
列表的另一种构造方式
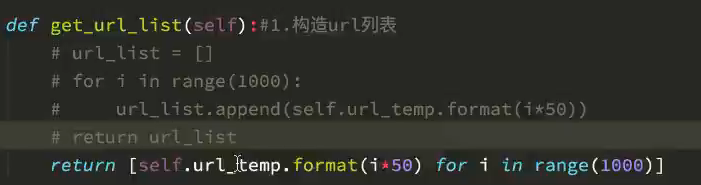
用列表的另一种构造方式替换代码:用5、6行代替1-4行
1 #url_list = []
2 #for i in range (1000):
3 #url_list.append(self.url_temp.format(i50))
4 #return url_list
5 url_list = [self.url_temp.format(i50) for i in range(1000)]
6 return url_list
替换后代码如下,运行结果与之前一致:
1 import requests
2
3 class TiebaSpider():
4 def __init__(self,tieba_name):
5 self.tieba_name = tieba_name
6 self.url_temp = "https://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}"
7 self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36"}
8
9 def get_url_list(self):
10 """构造url列表,获取贴吧1-1000页的内容"""
11 #url_list = []
12 #for i in range (1000):
13 #url_list.append(self.url_temp.format(i*50))
14 #return url_list
15 url_list = [self.url_temp.format(i*50) for i in range(1000)]
16 return url_list
17
18
19 def parse_url(self,url):
20 print(url)
21 response = requests.get(url,headers=self.headers)
22 return response.content.decode()
23
24
25 def save_html(self,html_str,page_num):
26 """保存html字符串"""
27 file_path = "{}-第{}页.html".format(self.tieba_name,page_num)
28 with open (file_path,"w",encoding="utf-8") as f: # "李毅吧-第1页"做成格式化
29 f.write(html_str)
30
31
32
33 def run(self): # 实现主要逻辑
34 # 1、构造url列表
35 url_list = self.get_url_list()
36 # 2、遍历列表发送请求,获取响应
37 for url in url_list:
38 html_str = self.parse_url(url)
39 # 3、保存html页面到本地
40 page_num = url_list.index(url)+1
41 self.save_html(html_str,page_num)
42
43
44 if __name__ == "__main__":
45 tieba_spider = TiebaSpider("李毅") # 创建一个类对象
46 tieba_spider.run()
爬虫requests库 之爬虫贴吧的更多相关文章
- Python爬虫—requests库get和post方法使用
目录 Python爬虫-requests库get和post方法使用 1. 安装requests库 2.requests.get()方法使用 3.requests.post()方法使用-构造formda ...
- requests库(爬虫)
北京理工大学嵩天老师的课程:http://www.icourse163.org/course/BIT-1001870001 官方文档:http://docs.python-requests.org/e ...
- Python爬虫--Requests库
Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,requests是python实现的最简单易用的HTTP库, ...
- Python爬虫:HTTP协议、Requests库(爬虫学习第一天)
HTTP协议: HTTP(Hypertext Transfer Protocol):即超文本传输协议.URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源. HTTP协议 ...
- 【Python成长之路】Python爬虫 --requests库爬取网站乱码(\xe4\xb8\xb0\xe5\xa)的解决方法【华为云分享】
[写在前面] 在用requests库对自己的CSDN个人博客(https://blog.csdn.net/yuzipeng)进行爬取时,发现乱码报错(\xe4\xb8\xb0\xe5\xaf\x8c\ ...
- [爬虫] requests库
requests库的7个常用方法 requests.request() 构造一个请求,支撑以下各种方法的基础方法 requests.get() 获取HTML网页的主要方法,对应于HTTP的GET re ...
- Requests库网络爬虫实战
实例一:页面的爬取 >>> import requests>>> r= requests.get("https://item.jd.com/1000037 ...
- Python爬虫 requests库基础
requests库简介 requests是使用Apache2 licensed 许可证的HTTP库. 用python编写. 比urllib2模块更简洁. Request支持HTTP连接保持和连接池,支 ...
- python爬虫---requests库的用法
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下 ...
随机推荐
- 前端页面模拟浏览器搜索功能Ctrl+F实现
<html> <head> <style type="text/css"> .res { color: Red; } .result{ back ...
- HTTP协议之chunk,单页应用这样的动态页面,怎么获取Content-Length的办法
当客户端向服务器请求一个静态页面或者一张图片时,服务器可以很清楚的知道内容大小,然后通过Content-Length消息首部字段告诉客户端需要接收多少数据.但是如果是动态页面等时,服务器是不可能预先知 ...
- Linux中的关机操作
shutdown -h now //马上停止服务进行关机 shutdown -h 12:00 .//在12点后进行关机 shutdown -h +10 //在10分钟后进行关机 shutdown ...
- max的高级用法
- VS中的Modules窗口
当我在别人的机器上调试问题时,我做的第一件事就是查看modules窗口.按版本排序并看到一个不属于的dll可以帮助立即诊断配置问题,并节省许多调试痛苦. 下面介绍下各列的意思: Name:模块名称. ...
- postgresql plv8 安装
网上可以看到pg 9.6 版本的plv8容器镜像,没有pg 高版本的支持镜像,但是在基于原有dockerfile 进行构建的时候,居然失败了,有墙的问题,有版本的问题 所以通过虚拟机尝试下构建方式安装 ...
- [RN] Android 设备adb连接后unauthorized解决方法
Android 设备adb连接后unauthorized解决方法 安卓设备usb或者adbwireless连接后输入adb device后都是未授权状态 相信很多同学都会遇到这种情况,除了一直重复开关 ...
- Linux系统中python默认版本为python2.7,修改为python3 项目上传码云
# 查询系统本系统中安装的python版本 ls -l /usr/bin/python* 1.在虚拟机上新建虚拟环境 # 系统中python默认版本为python2.,可以将其修改为python3 # ...
- hive基础知识五
Hive 主流文件存储格式对比 1.存储文件的压缩比测试 1.1 测试数据 https://github.com/liufengji/Compression_Format_Data M 1.2 T ...
- 作业:SSH
作业:使用SSH通过网络远程控制电脑 在虚拟机中用apt命令安装了ssh,但多次连接都失败了,尝试了很多次.后来发现只要是虚拟机中的系统使用的ip都是一样的从而发现了问题.虚拟机的网络是被更改后的,后 ...