数据量与半监督与监督学习 Data amount and semi-supervised and supervised learning
机器学习工程师最熟悉的设置之一是访问大量数据,但需要适度的资源来注释它。处于困境的每个人最终都会经历逻辑步骤,当他们拥有有限的监督数据时会问自己该做什么,但很多未标记的数据,以及文献似乎都有一个现成的答案:半监督学习。
这通常是出现问题的时候。
从历史上看,半监督学习一直是每个工程师作为一种通过仪式进行的兔子洞之一,只是为了发现对普通旧数据标签的新发现。细节对于每个问题都是独一无二的,但从广义上讲,它们通常可以描述如下:

在低数据制度中,半监督培训确实倾向于提高绩效。但在实际环境中,你经常会从“可怕且不可用”的性能水平变为“不太可怕但仍然完全无法使用”。从本质上讲,当你处于半监督学习实际上有帮助的数据体系时,这意味着你也处于一种你的分类器非常糟糕且没有实际用途的制度中。
此外,半监督通常不是免费的,并且使用半监督学习的方法通常不能为您提供监督学习在高数据制度中所做的相同渐近性质 - 未标记的数据可能会引入偏差, 例如。参见例如第4节。在深度学习的早期,一种非常流行的半监督学习方法是首先在未标记数据上学习自动编码器,然后对标记数据进行微调。几乎没有人这样做,因为通过自动编码学习的表示倾向于凭经验限制微调的渐近性能。有趣的是,即使是大大改进的现代生成方法也没有多大改善这种情况,可能是因为什么使得良好的生成模型不一定是什么使得良好的分类器。因此,当您看到工程师今天对模型进行微调时,通常从在监督数据上学习的表示开始 - 是的,我认为文本是用于语言建模目的的自我监督数据。在任何可行的情况下,从其他预训练模型转移学习是一个更加强大的起点,半监督方法难以超越。
因此,典型的机器学习工程师在半监督学习的沼泽中的旅程如下:
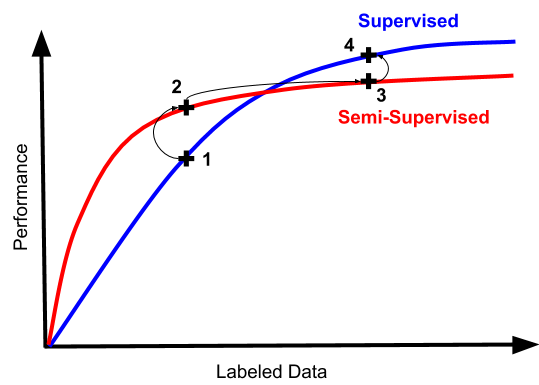
1:一切都很糟糕,让我们尝试半监督学习!(毕竟,这是工程工作,比标记数据更有趣......)
2:看,数字上升!但是仍然很可怕。看起来我们毕竟必须标记数据......
3:更多的数据更好,但是你有没有尝试过丢弃半监督机器会发生什么?
4:嘿,你知道什么,它实际上更简单,更好。我们可以通过完全跳过2和3来节省时间和大量技术债务。
如果您非常幸运,您的问题也可能具有这样的性能特征:
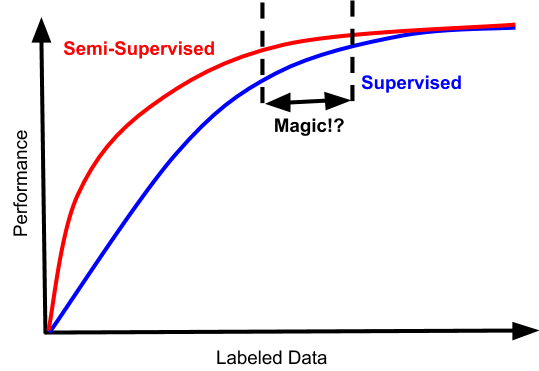
在这种情况下,存在一种狭窄的数据体系,其中半监督是不可怕的并且还提高了数据效率。根据我的经验,很难打到那个甜蜜点。考虑到额外复杂性的成本,标记数据量的差距通常不是更好的数量级,并且收益递减,这很少值得麻烦,除非你在学术基准上竞争。
但等等,这部题为“安静的半监督革命”的作品不是吗?
一个引人入胜的趋势是半监督学习的景观可能会变成看起来更像这样的东西:
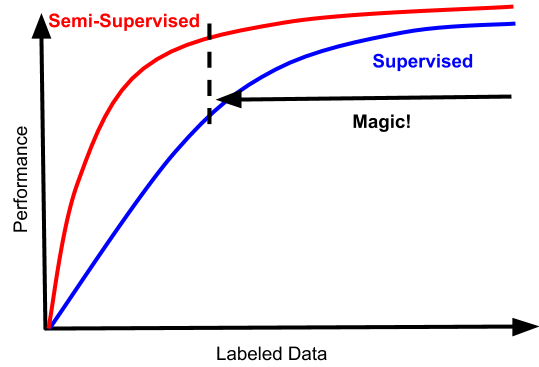
这会改变一切。首先,这些曲线与半监督方法应该做的心理模型相匹配:更多数据应该总是更好。即使对于监督学习表现良好的数据制度,半监督和监督之间的差距也应严格为正。并且越来越多地发生这种情况是免费的,而且额外的复杂性非常小。“魔术区”开始走低,同样重要的是,它不受高数据制度的束缚。
什么是新的?很多东西:许多聪明的方法来自我标记数据并以这样的方式表达损失,即它们与噪声和自我标记的潜在偏差兼容。最近的两部作品举例说明了最近的进展并指出了相关文献:MixMatch:半监督学习和无监督数据增强的整体方法。
半监督学习世界的另一个根本转变是认识到它可能在机器学习隐私中扮演非常重要的角色。例如,颈部的方法(半监督知识转移的深度学习从私人训练数据,可扩展的私学教育与PATE,)从而使监管数据被估计私人,并具有较强的私密性保证学生模型仅使用未标记的培训(假定公共)数据。用于提取知识的隐私敏感方法正在成为联邦学习的关键推动者之一,联合学习提供了有效的分布式学习的承诺,其不依赖于具有访问用户数据的模型,具有强大的数学隐私保证。
在实际环境中重新审视半监督学习的价值是一个激动人心的时刻。看到一个长期存在的假设受到挑战,这是该领域惊人进展的一个很好的指标。这种趋势都是最新的,我们必须看看这些方法是否经得起时间的考验,但是这些进步可能导致机器学习工具架构发生根本转变的可能性非常大。
数据量与半监督与监督学习 Data amount and semi-supervised and supervised learning的更多相关文章
- 斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)
下图为四种不同算法应用在不同大小数据量时的表现,可以看出,随着数据量的增大,算法的表现趋于接近.即不管多么糟糕的算法,数据量非常大的时候,算法表现也可以很好. 数据量很大时,学习算法表现比较好的原理: ...
- 学习笔记DL003:神经网络第二、三次浪潮,数据量、模型规模,精度、复杂度,对现实世界冲击
神经科学,依靠单一深度学习算法解决不同任务.视觉信号传送到听觉区域,大脑听学习处理区域学会“看”(Von Melchner et al., 2000).计算单元互相作用变智能.新认知机(Fukushi ...
- 达观数据CTO纪达麒:小标注数据量下自然语言处理实战经验
自然语言处理在文本信息抽取.自动审校.智能问答.情感分析等场景下都有非常多的实际应用需求,在人工智能领域里有极为广泛的应用场景.然而在实际工程应用中,最经常面临的挑战是我们往往很难有大量高质量的标注语 ...
- 小样本利器1.半监督一致性正则 Temporal Ensemble & Mean Teacher代码实现
这个系列我们用现实中经常碰到的小样本问题来串联半监督,文本对抗,文本增强等模型优化方案.小样本的核心在于如何在有限的标注样本上,最大化模型的泛化能力,让模型对unseen的样本拥有很好的预测效果.之前 ...
- OSVOS 半监督视频分割入门论文(中文翻译)
摘要: 本文解决了半监督视频目标分割的问题.给定第一帧的mask,将目标从视频背景中分离出来.本文提出OSVOS,基于FCN框架的,可以连续依次地将在IMAGENET上学到的信息转移到通用语义信息,实 ...
- Machine Learning分类:监督/无监督学习
从宏观方面,机器学习可以从不同角度来分类 是否在人类的干预/监督下训练.(supervised,unsupervised,semisupervised 以及 Reinforcement Learnin ...
- 详解使用EM算法的半监督学习方法应用于朴素贝叶斯文本分类
1.前言 对大量需要分类的文本数据进行标记是一项繁琐.耗时的任务,而真实世界中,如互联网上存在大量的未标注的数据,获取这些是容易和廉价的.在下面的内容中,我们介绍使用半监督学习和EM算法,充分结合大量 ...
- sql server 大数据, 统计分组查询,数据量比较大计算每秒钟执行数据执行次数
-- 数据量比较大的情况,统计十分钟内每秒钟执行次数 ); -- 开始时间 ); -- 结束时间 declare @num int; -- 结束时间 set @begintime = '2019-08 ...
- 半监督学习方法(Semi-supervised Learning)的分类
根据模型的训练策略划分: 直推式学习(Transductive Semi-supervised Learning) 无标记数据就是最终要用来测试的数据,学习的目的就是在这些数据上取得最佳泛化能力. 归 ...
随机推荐
- Android ProGuard:代码混淆压缩
写这篇文章的目的 一直以来,在项目中需要进行代码混淆时每次都要去翻文档,很麻烦.也没有像写代码那样记得那么多.既然要查来查去,就不如自己捋一捋这个知识点了,被人写的终究还是别人的.所以自己去翻看了很多 ...
- 从学习“单例模式”学到的Java知识:双重检查锁和延迟初始化
一切真是有缘,上午刚刚看完单例模式,还在为其中的代码块同步而兴奋,下午就遇见这篇文章:双重检查锁定与延迟初始化.我一看,文章开头语出惊人,说这是一种错误的优化,我说,难道上午学的东西下午就过时了吗?仔 ...
- c# IEnumerable集合
- javascript详解1
推荐学习链接: https://book.apeland.cn/details/356/ http://es6.ruanyifeng.com/#README https://developer.moz ...
- linux网络编程之socket编程(三)
今天继续对socket编程进行学习,在学习之前,需要回顾一下上一篇中编写的回射客户/服务器程序(http://www.cnblogs.com/webor2006/p/3923254.html),因为今 ...
- InvenSense 美国公司
InvenSense为智能型运动处理方案的先驱.全球业界的领导厂商,驱动了运动感测人机接口在消费性电子产品上的应用.公司提供的集成电路(IC)整合了运动传感器-陀螺仪以及相对应的软件,有别于其他厂商, ...
- MyEclipse激活代码
package TestCase; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStr ...
- 行为型模式(八) 职责链模式(Chain of Responsibility)
一.动机(Motivate) 在软件构建过程中,一个请求可能被多个对象处理,但是每个请求在运行时只能有一个接受者,如果显示指定,将必不可少地带来请求发送者与接受者的紧耦合.如何使请求的发送者不需要指定 ...
- 题解 UVa10780
题目大意 多组数据,每组数据给定两个整数 \(m,n\),输出使 \(n\%m^k=0\) 的最大的 \(k\).如果 \(k=0\) 则输出Impossible to divide. 分析 计数水题 ...
- 【CSP-S 2019】【洛谷P5658】括号树【dfs】【二分】
题目: 题目链接:https://www.luogu.org/problem/P5658?contestId=24103 本题中合法括号串的定义如下: () 是合法括号串. 如果 A 是合法括号串,则 ...