【论文考古】量化SGD QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding
D. Alistarh, D. Grubic, J. Li, R. Tomioka, and M. Vojnovic, “QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding,” Advances in Neural Information Processing Systems, vol. 30, 2017, Accessed: Jul. 31, 2021. [Online]. Available: https://proceedings.neurips.cc/paper/2017/hash/6c340f25839e6acdc73414517203f5f0-Abstract.html
作为量化SGD系列三部曲的第二篇,本篇文章是从单机学习到联邦学习的一个重要过渡,在前人的基础上重点进行了理论分析的完善,成为了量化领域绕不开的经典文献。
简介
相较于上一篇IBM的文章,本文考虑用梯度量化来改善并行SGD计算中的通信传输问题,并重点研究了通信带宽和收敛时间的关系(precision-variance trade-off)。具体而言,根据information-theoretic lower bounds,当调整每次迭代中传输的比特数时,梯度方差会发生改变,从而进行收敛性分析。实验结果表明在用ResNet-152训练ImageNet时能带来1.8倍的速率提升。
观点
- QSGD基于两个算法思想
- 保留原始统计性质的随机量化(来源于量化SGD的实验性质)
- 对量化后梯度的整数部分有损编码(进一步降低比特数)
- 减少通信开销往往会降低收敛速率,因此多训练带来的额外通信次数值不值,是神经网络量化传输需要考虑的重点
- 可以把量化看作一个零均值的噪声,只是它碰巧能够让传输更加有效
- 卷积层比其他层更容易遭受量化带来的性能下降,因此在量化方面,完成视觉任务的网络可能比深度循环网络获益更少
理论
方差对于SGD收敛性的影响
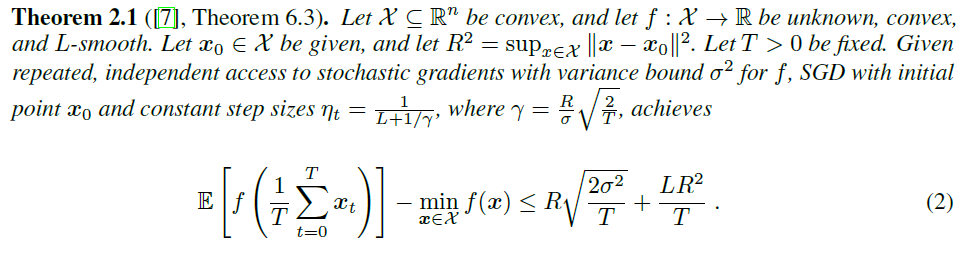
mini-batch操作可以看作是减少方差的一个方法,当第一项主导的时候,由于方差减少到了\(\sigma^2 /m\),因此收敛所需的迭代次数变为\(1/T\)
无损的parallel SGD就是一种mini batch,因此将定理换一种写法(其实就是写成不等式右边趋于零时),得到收敛所需迭代次数与方差的关系

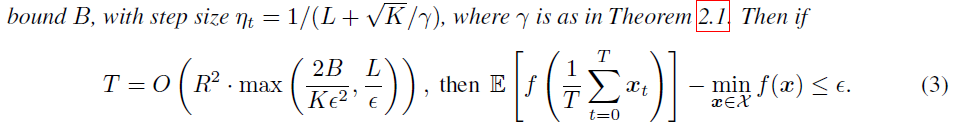
通常第一项会主导迭代次数,因此结论:收敛所需的迭代次数与随机梯度的二阶方差界\(B\)成线性关系
随机量化与编码
随机量化
量化水平数量\(s\)(没有包含0),量化水平在\([0,1]\)均匀分布。构造的目的为:1)preserves the value in expectation;2)introduce minimal variance。

- 对于向量中的每个分量单独量化
- 进行\(|v_i|/\|v\|_2\)操作后能保证每个分量都落在\([0,1]\)区间内,从而转化为\([0,1]\)上的量化
- 最终的上下取值概率之比就是量化点到上下量化水平的距离之比
好像和投影距离是等价的?
如此量化后有良好的统计特性(在这个量化值下有最小的方差)

编码
Elias integer encoding,基本思想是大的整数出现的频率会更低,因此循环的编码第一个非零元素的位置
将整数转变为二进制序列,编码后的长度为\(|\operatorname{Elias}(k)|=\log k+\log \log k+\ldots+1 \leq(1+o(1)) \log k+1\)
可得在给定量化方差界\(\left(\|v\|_{2}, \sigma, \zeta\right)\)后,需要传输的比特数上界为
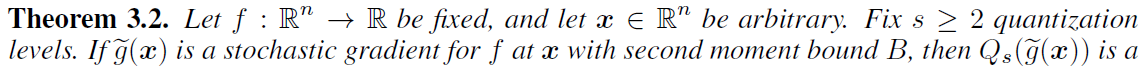
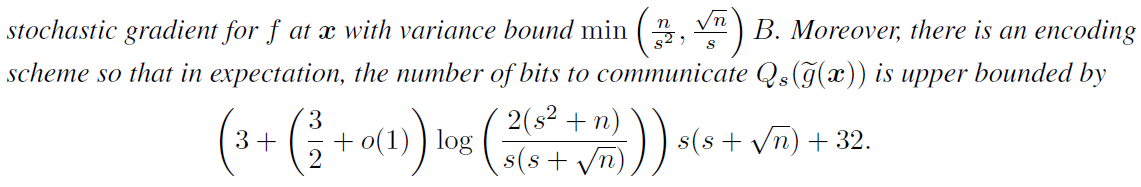
注:此时1bit传输作为\(s=1\)的稀疏特例
将两个定理合并后的结果如下。由于QSGD计算的是接口变量方差,因此可以很便利地结合到各种与方差相关的随机梯度分析框架中。
Smooth convex QSGD
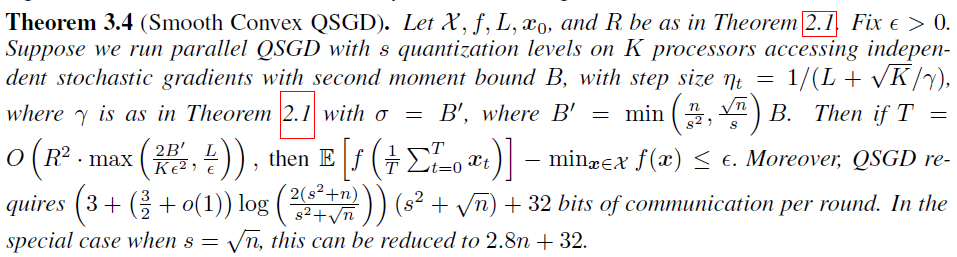
Smooth non-convex

QSGD在实际应用中的两个变种
- 将一个向量进一步分为若干bucket来量化,显然bucket size越大方差越大
- 在向量scaling的时候选用最大分量值而不是向量的二范数
实验
全精度SGD传\(32n\)比特,QSGD最少可以只传\(2.8n+32\)比特,在两倍迭代次数下,可以带来节约\(5.7\)倍的带宽
实验结果
性能上几乎超越了大模型
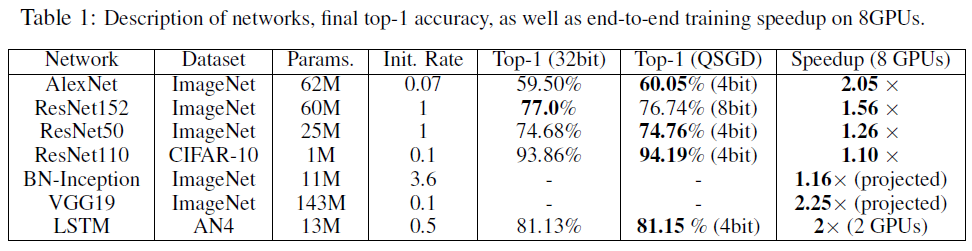
- 要用大模型才有量化的价值
We will not quantize small gradient matrices (< 10K elements), since the computational cost of quantizing them significantly exceeds the reduction in communication.
计算和通信的开销
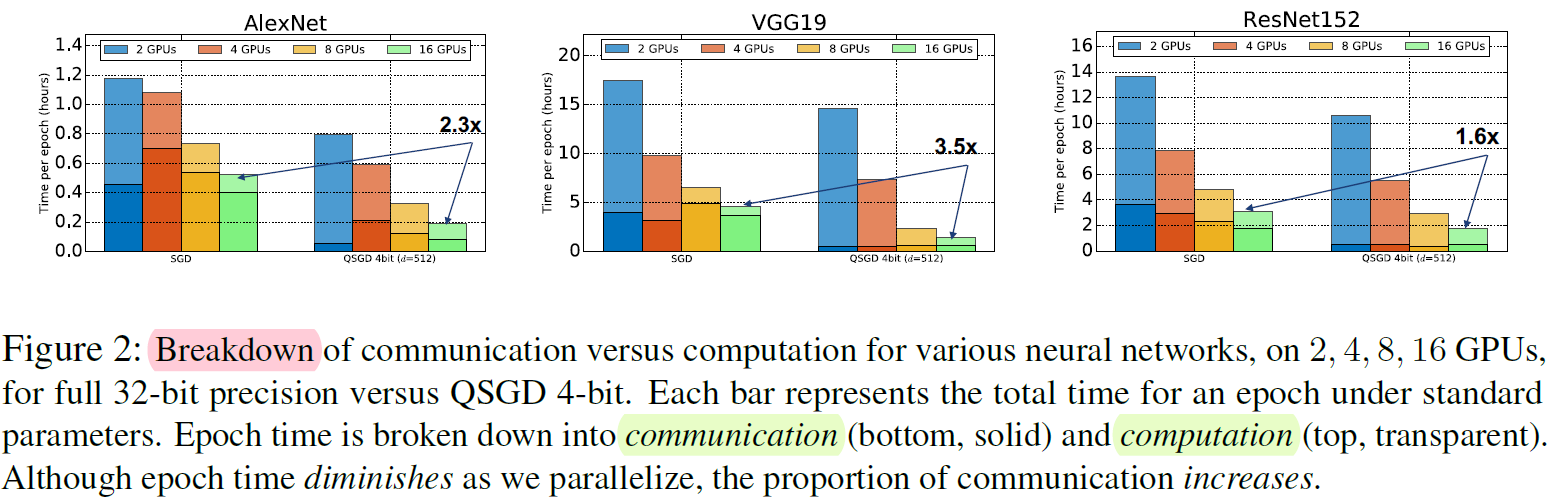
- 增加并行后主要耗时在通信上
实验部分还没有完全搞懂(比如protocol部分、GPU的并行)
借鉴
- 文章在QSGD的基础上,从stochastic variance-reduced variant角度又继续分析QSVRG,覆盖到了指数收敛速率。也就是通过添加新技术来说明原始方法的扩展性。
- 这篇文章的基础是communication complexity lower bound of DME,因此建立传输比特数和方差的关系是直接拿过来的。而方差和收敛性的分析也是常用的,因此在承认DME的基础上很容易得到tight bound。
- 这篇文章的写作并不算优秀,但是内容十分solid和extensive,绝对是经典之作。
【论文考古】量化SGD QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding的更多相关文章
- NeurIPS 2017 | QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding
由于良好的可扩展性,随机梯度下降(SGD)的并行实现是最近研究的热点.实现并行化SGD的关键障碍就是节点间梯度更新时的高带宽开销.因此,研究者们提出了一些启发式的梯度压缩方法,使得节点间只传输压缩后的 ...
- 【论文考古】分布式优化 Communication Complexity of Convex Optimization
J. N. Tsitsiklis and Z.-Q. Luo, "Communication complexity of convex optimization," Journal ...
- 论文笔记——A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding
论文<A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding> Prunin ...
- 【论文考古】联邦学习开山之作 Communication-Efficient Learning of Deep Networks from Decentralized Data
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, "Communication-Efficient Learni ...
- 论文解读(GCC)《Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering》
论文信息 论文标题:Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering论文作者:Chaki ...
- 【论文阅读】ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
ShuffleNet: An Extremely Efficient Convolutional Neural Network for MobileDevices
- [论文]CA-Tree: A Hierarchical Structure for Efficient and Scalable Coassociation-Based Cluster Ensembles
作者:Tsaipei Wang, Member, IEEE 发表:IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNET ...
- 【论文考古】知识蒸馏 Distilling the Knowledge in a Neural Network
论文内容 G. Hinton, O. Vinyals, and J. Dean, "Distilling the Knowledge in a Neural Network." 2 ...
- 【论文阅读】PBA-Population Based Augmentation:Efficient Learning of Augmentation Policy Schedules
参考 1. PBA_paper; 2. github; 3. Berkeley_blog; 4. pabbeel_berkeley_EECS_homepage; 完
随机推荐
- Linux配置 ftp 和 ftp简单介绍
一.ftp概念? /* ftp是一个协议和http协议都是叫协议 tcp和udp也是协议 ftp是文件(以流的形式进行传输)传输协议(针对于文件进行上传和下载) */ 1.如果ftp服务器有多台,服务 ...
- Arduino+ESP32 之 驱动GC9A01圆形LCD(二),移植LVGL,跑示例程序,显示自制图片
在前文Arduino+ESP32 之 驱动GC9A01圆形LCD(一), 我们已经移植好了arduino GFX库, 该库的示例程序内,还有LVGL的示例程序哦. arduino环境下移植lvgl是很 ...
- ABC209 E Shiritori
考虑对这个问题进行转化: 显然我们只关注每个串前三个棋子和后三个棋子,并且根据题目的特性,我们可以将任意的三个字符看作点,将一个字符串看作连接两个点的边,这样我们得到了一张点数为 \(52 ^ 3\) ...
- SP5971 LCMSUM - LCM Sum
一个基于观察不依赖于反演的做法. 首先 \(\rm lcm\) 是不好算的,转化为计算 \(\rm gcd\) 的问题,求: \[\sum\limits_{i = 1} ^ n \frac{in}{\ ...
- Thread中常用API
1.sleep方法 线程的 sleep 方法会使线程休眠指定的时间长度.休眠的意思是,当前逻辑执行到此不再继续执行,而是等待指定的时间.但在这段时间内,该线程持有的锁并不会释放.这样设计很好理解,因为 ...
- 关于obj.class.getResource()和obj.getClass().getClassLoader().getResource()的路径问题
感谢原文作者:yejg1212 原文链接:https://www.cnblogs.com/yejg1212/p/3270152.html 注:格式内容与原文有轻微不同. Java中取资源时,经常用到C ...
- Android中的多线程【转】
感谢大佬:https://www.cnblogs.com/zoe-mine/p/7954605.html 感谢大佬:https://blog.csdn.net/u014555121/article/d ...
- linux 批量替换文件内容及查找某目录下所有包含某字符串的文件
转载请注明来源:https://www.cnblogs.com/hookjc/ 1. sed C代码 grep -rl matchstring somedir/ | xargs sed -i 's ...
- Ajax接收服务器返回的信息response
Ajax可以向服务器发起请求,有去的方式,那么久必然可疑返回. 服务器返回的信息也可以通过Ajax接收. Ajax共有5种状态: 1.创建对象,没有调用open方法 2.对象发起请求http,已经调用 ...
- NSMutableDictionary基本概念
1.NSMutableDictionary 基本概念 什么是NSMutableDictionary NSMutableDictionary是NSDictionary的子类 NSDictionary是不 ...