Faiss源码剖析:类结构分析
摘要:在下文中,我将尝试通过Faiss源码中各种类结构的设计来梳理Faiss中的各种概念以及它们之间的关系。
本文分享自华为云社区《Faiss源码剖析(一):类结构分析》,原文作者:HW007。
Faiss是由Facebook AI Research研发的为稠密向量提供高效相似度搜索和聚类的框架。通过其官方给出的新手指南,我们可以快速地体验Faiss的基本功能。但是,相信大多数人看完官方的新手指南后,对Faiss很多的概念还是有点模糊、无法清晰的明确这些概念之间的边界。比如说在Faiss中,Quantizer是个什么概念、其与Index之间的联系是什么;还有各种Index之间的关系又是什么等等。为此,在下文中,我将尝试通过Faiss源码中各种类结构的设计来梳理Faiss中的各种概念以及它们之间的关系。
首先奉上Faiss源码的类图全家福如下,详细的EA类图文件见附件:

图一:Faiss的类图全家福
首先,我们来看一下Faiss最主要的功能:相似度搜索。如下图所示,以图片搜索为例,所谓相似度搜索,便是在给定的一堆图片(下图中左上角的图集)中,寻找出我指定的目标(下图中左下角的巴士图片)最像的K张图片,也简称为KNN(K近邻)问题。
接下来我们看一下为了解决KNN问题,在工程上我们至少需要做哪些事情。显然,有两件事是必须要做的,第一,我们要把上面例子中的那个图库存储起来;第二,当用户指定一种图片后,我们需要知道怎么从存储的图库中找到最近相似的K张图片。由此,我们确定了Faiss在其应用场景中至少应该具备的两个功能:添加功能和搜索功能。
对于熟悉数据库的同学来说,应该能在这里嗅到点“CRUD”的味道。的确,当我们对“图集”有添加存储这样的动作后,修改和删除等功能也便接踵而来了。由此Faiss本质上就是一个向量数据库。对于数据库来说,时空优化是两个永恒的主题,即在存储上如何以更少的空间来存储更多的信息,在搜索上如何以更快的速度来搜索出更准确的信息。如何减少搜索所需的时间?在数据库中很最常见的操作便是加各种索引,把各种加速搜索算法的功能或空间换时间的策略都封装成各种各样的索引,以满足各种不同的引用场景。
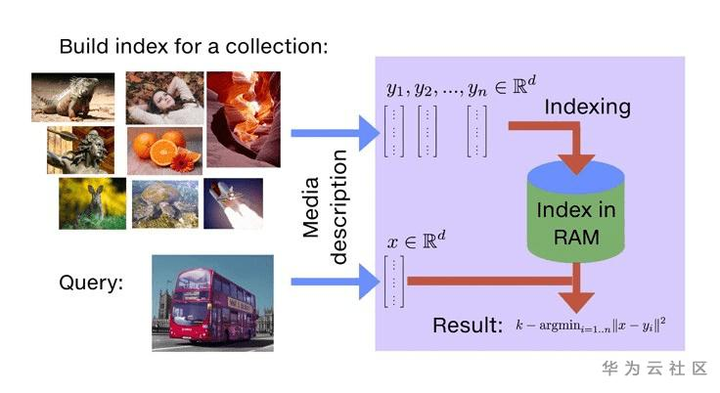
由此,我们便不难理解为什么Faiss中为什么会有那么多的Index了,因为Index这个概念本身就与加速搜索是绑在一起的。由此也可以看出在Faiss中,如何又快又准地找到相似向量是第一要务。下图中给出的是Faiss中最重要的两个基类:Index和IndexBinary。
在上图中,用白色的箭头标出了这两个基类中最重要的三个函数,其中add()和search() 函数便对应了我上文中所提到的Faiss至少应该实现的两个基本功能:存储和搜索。在此顺带提一下,与传统的数据库相比,Faiss的Index还包含了数据存储的功能,如果你一开始就从字面上按照传统数据库中索引的概念来理解地话,就会感觉有点怪怪的。接下来,我们重点聊聊Index中的train()函数,我们都知道天上是不会白白掉馅饼的,对于Faiss来说,不管其为了减少存储空间还是加速搜索,都需要提前做好一些准备工作,这便是train()函数发挥作用的时候了。
以减少存储为例子,我们都知道在图片处理中通过PCA可以将图片从高维空间(p维)转换到低维空间(q维, 其中 p > q ),其具体操作便是是将高维空间中的图片向量(n*p)乘以一个转换矩阵(p*q),得到一个低维空间中的向量(n*q)。为了使得在整个降维的过程中信息丢失最少,我们需要对待转换图片进行分析计算得到相应的转换矩阵(p*q)。也就是说这个降维中乘以的转换矩阵是与待转换图片息息相关的。
回到我们的Faiss中来,假设我期望使用PCA预处理来减少Index中的存储空间,那在整个处理流程中,除了输入搜索图库外,我必须多输入一个转换矩阵,但是这个转换矩阵是与图库息息相关的,是可以由图库数据计算出来的。如果把这个转换矩阵看成一个参数的话,我们可以发现,在Faiss的一些预处理中,我们会引入一些参数,这些参数又无法一开始由人工来指定,只能通过喂样本来训练出来,所以Index中需要有这样的一个train() 函数来为这种参数的训练提供输入训练样本的接口。由此,我们也可以发现,这些喂给train()函数的样本数据最好与之后要添加存储的图集以及搜索目标一致比较好,比如说,你先给Index喂一个猪脸数据集训练出PCA中的转换矩阵,再给这个Index添加人脸数据集,最后再在这个索引上做人脸识别,这样肯定比不上一开始就喂人脸数据集得到PCA转换矩阵的效果好。
由上,我们已经可以从train()、add()和search()三大函数大概地了解到Faiss中的Index是个什么东西了,接下来我们看一下Faiss中有哪些不同的Index。从图一中的类图中可以看到,在Faiss中,大多数类基本都继承或使用了Index接口,他们要么对Index接口中定义的train、add和search函数进行了自己个性化的实现(如图一中被淡橙色标注的类),要么就是对已经实现的三大函数的类进行包装,提供一些三大函数之外的流程上的加工处理(如图一中被淡蓝色标注的类)。
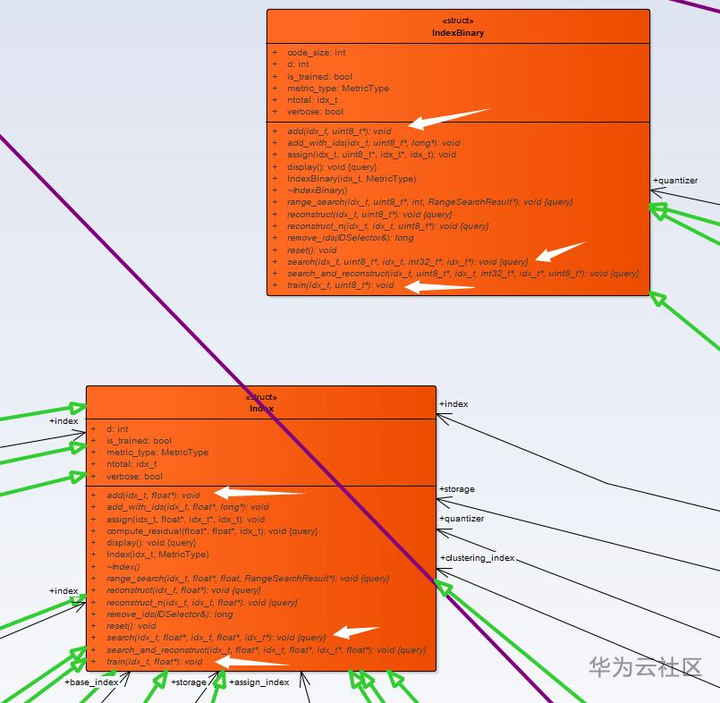
从图一中我们可以看到这些被淡蓝色标注的偏包装的Index子类,他们与Index基类之间既有“is a”又有“hold a”关系,在类结构上出现这种关系的时候,设计者要么是在设计一个树或链表的节点,要么是在设计一个包装类。显然在Faiss中更偏向于后者。一方面,淡蓝色的Index子类借助其所“hold”的Index来提供基本的train、add和search功能,使其自身符合Index接口的定义标准,成为一种Index,为之后的层层嵌套包装提供支持。另一方面,他又对其所“hold”的Index类进行了一些通用的功能扩展。如下图的IndexPreTransform类所示,Faiss将对待存储图集的预处理,如归一化、PCA降维等功能抽象成一个VectorTransform接口,让IndexPreTransform使用它来为其所“hold”的Index添加预处理功能,这种预处理功能是与其所“hold”的是什么Index没有任何关系,因此我更偏向于将这种功能归结为Index之外的流程上的包装功能。如IndexPreTransform类提供了数据预处理功能、IndexIDMap类提供了自定义ID功能、IndexShards类为Index的并行计算提供了相关的支持等。
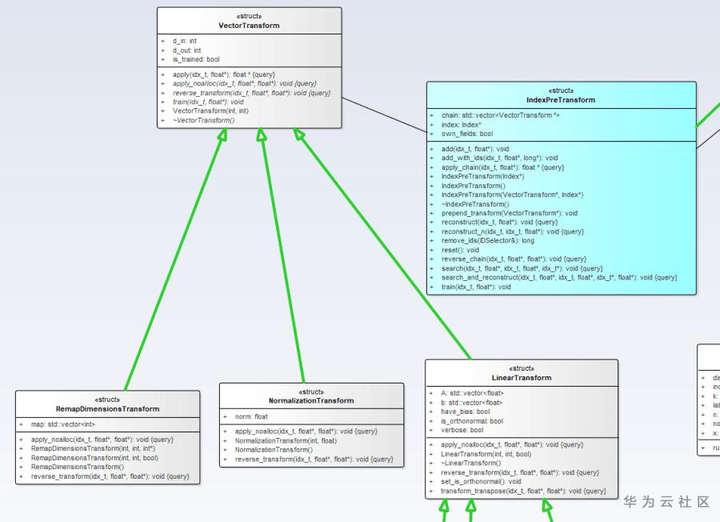
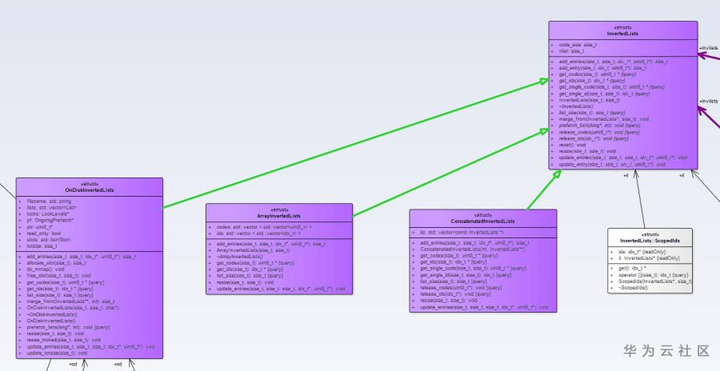
接下来我们来看一下图一中被淡橙色标注的Index子类,如IndexLSH、IndexPQ、IndexIVFPQ等,从名字中我们可以大概了解到这些类都是基于一些不同的算法实现的不同索引,他们的train、add和search方法各有差异。但在整体上还是能找到一些其他结构上的共性。在上文中,我们知道Index具有存储的功能,这些被淡橙色标注的Index子类在数据存储方式上基本可以划分为两大类,一类是统一存到一个容器中,如在IndexLSH、IndexPQ等中我们都可以看到一个命名为codes的vector容器。另一类是分桶储存到多个容器中,这主要为索引后续的非精确分桶局部搜索提供支持,为此,Faiss特地抽象出InvertedLists接口,需要支持分桶局部搜索的Index子类均会有hold一个实现了InvertedLists接口(淡紫色标注)的实例来存储其数据。如下图所示,Faiss为InvertedLists接口提供了数组、链表和磁盘文件等三种不同的实现。
在图一中还有两个被标记为淡绿色的类ProductQuantizer和ScalarQuantizer值得大家关注下,在结构上,这两个类均没有派生的子类,并且所有其他的类与他们的关系均为“hold a”关系,很纯粹的工具类。从其命名中的Quantizer(量化器)后缀可知,这两个工具类的作用是将“连续或稠密”的数据进行“离散或稀疏化”,简单来说就是进行聚类的操作,就像我们把18岁以下的称为少年,18~50岁的称为中年一样,我们把具体年龄量化成年龄段的过程就是一个聚类的过程。从图一中还可以看到,带有Quantizer后缀的类还有四个:MultiIndexQuantizer、MultiIndexQuantizer2、IndexScalarQuantizer和Level1Quantizer。其中前三个均是通过对ProductQuantizer或ScalarQuantizer的包装来实现Quantizer的功能,没什么稀奇的地方,但最后一个Level1Quantizer类竟然是包装了两个Index类,而且其中一个Index类的属性名还是quantizer,如下图所示。

难道Index也是一种Quantizer?的确,对于Index来说,我们更熟悉的是其将数据集存储起来,再寻找某个数据在该数据集中的K个最近邻点的功能。但如果Index中存储的是数据分类后各个类的中心点呢,那么对于某个数据,我们便可以在该Index上通过KNN来求得其K(此时K=1)个最近邻点,这些求出来的中心点所代表的类便是该数据在聚类中该归属的类。由此我们可以看到Index是可用来聚类,将数据量化成类的中心点的。因此,Index可以被包装成一个Quantizer也便不足为奇了。其实Index的这种聚类功能在Faiss的设计中是很常见的,除了上面所说的用来做Quantizer外,还可以用来辅助实现K-means算法,这也是为什么Level1Quantizer类中除quantizer外还存在一个名为clustering_index的Index类型属性的原因。通过上面的分析,我们还可以知道,在Faiss的Quantizer类中,或明或暗都应该有个地方来存储用来辅助量化的“centroids”,即类中心点,它们在大多数场景中都是经过数据训练出来的(如对数据进行K-means聚类),在少数场景中也可以直接人为设定。

让我们最后来关注下IndexIVF类(上图中被圈出来的淡紫色类)。也许在上文介绍淡紫色的InvertedLists类簇时,有人会有疑问,InvertedLists类及其派生子类在Faiss中主要为Index提供非精确的分桶局部搜索功能,这种功能与Index的种类毫无关系,按上文对Index派生的子类的分类标准来看,IndexIVF类应该是一个偏包装的Index子类,应该被标注为淡蓝色才对。的确,如上图所示,虽然IndexIVF类没有直接“hold a”Index类,但其通过继承Level1Quantizer类间接“hold a”Index类,确实也是一个偏包装的Index派生子类。图一的颜色标注只是为了突出拥有IVF功能的Index类,通过颜色来辅助各个功能类簇在视觉上的区分度而已,不必深究。
通过上文,我们可以发现,Faiss的整个类结构设计是非常清晰简洁的,其首先将KNN问题的解决过程切分成train、add和search三个步骤并抽象出Index基类。接着从这些基类派生出各种偏功能实现或者偏流程包装的Index子类。此外还为Index提供了两种的存储方式:集中和分桶(IVF)。最后还提供了SQ和PQ两种量化编码工具以及将这些编码工具或其他的Index包装成Quantizer的类。
Faiss源码剖析:类结构分析的更多相关文章
- 老李推荐:第6章8节《MonkeyRunner源码剖析》Monkey原理分析-事件源-事件源概览-小结
老李推荐:第6章8节<MonkeyRunner源码剖析>Monkey原理分析-事件源-事件源概览-小结 本章我们重点围绕处理网络过来的命令的MonkeySourceNetwork这个事 ...
- 老李推荐:第6章7节《MonkeyRunner源码剖析》Monkey原理分析-事件源-事件源概览-注入按键事件实例
老李推荐:第6章7节<MonkeyRunner源码剖析>Monkey原理分析-事件源-事件源概览-注入按键事件实例 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜 ...
- 老李推荐:第6章6节《MonkeyRunner源码剖析》Monkey原理分析-事件源-事件源概览-命令队列
老李推荐:第6章6节<MonkeyRunner源码剖析>Monkey原理分析-事件源-事件源概览-命令队列 事件源在获得字串命令并把它翻译成对应的MonkeyEvent事件后,会把这些 ...
- 老李推荐:第6章4节《MonkeyRunner源码剖析》Monkey原理分析-事件源-事件源概览-翻译命令字串
老李推荐:第6章4节<MonkeyRunner源码剖析>Monkey原理分析-事件源-事件源概览-翻译命令字串 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自 ...
- 老李推荐:第6章5节《MonkeyRunner源码剖析》Monkey原理分析-事件源-事件源概览-事件
老李推荐:第6章5节<MonkeyRunner源码剖析>Monkey原理分析-事件源-事件源概览-事件 从网络过来的命令字串需要解析翻译出来,有些命令会在翻译好后直接执行然后返回,但有 ...
- 老李推荐:第6章3节《MonkeyRunner源码剖析》Monkey原理分析-事件源-事件源概览-命令翻译类
老李推荐:第6章3节<MonkeyRunner源码剖析>Monkey原理分析-事件源-事件源概览-命令翻译类 每个来自网络的字串命令都需要进行解析执行,只是有些是在解析的过程中直接执行 ...
- 老李推荐:第6章2节《MonkeyRunner源码剖析》Monkey原理分析-事件源-事件源概览-获取命令字串
老李推荐:第6章2节<MonkeyRunner源码剖析>Monkey原理分析-事件源-事件源概览-获取命令字串 从上一节的描述可以知道,MonkeyRunner发送给Monkey的命令 ...
- 老李推荐:第5章7节《MonkeyRunner源码剖析》Monkey原理分析-启动运行: 循环获取并执行事件 - runMonkeyCycles
老李推荐:第5章7节<MonkeyRunner源码剖析>Monkey原理分析-启动运行: 循环获取并执行事件 - runMonkeyCycles poptest是国内唯一一家培养测试开 ...
- 老李推荐:第5章6节《MonkeyRunner源码剖析》Monkey原理分析-启动运行: 初始化事件源
老李推荐:第5章6节<MonkeyRunner源码剖析>Monkey原理分析-启动运行: 初始化事件源 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试 ...
随机推荐
- KnowRbao_uni-app
uni-app开发项目模板 主要的代码如下: pages.json 这里是添加页面的路径代码还可以设置标题: { "pages" : [ //pages数组中第一项表示应用启动页, ...
- virtualbox-centos扩容
virtualbox-centos扩容 版本信息 virtualbox:版本 6.1.4 r136177 (Qt5.6.2) centos:CentOS Linux release 7.7.1908 ...
- 后端程序员之路 17、LaTeX公式
之前的文章写了两个公式:d(x,y)=\sqrt{\sum_{i=1}^{n}(x_i-y_i)^2} H_x=-\sum_{i=1}^{n}p(x_i)\log_{2}{p(x_i)} LaTex ...
- 这是你没见过的不一样的redis
转: 这是你没见过的不一样的redis 提到Redis,大家一定会想到的几个点是什么呢? 高并发,KV存储,内存数据库,丰富的数据结构,单线程(6版本之前) 那么,接下来,上面提到的这些,都会一一给大 ...
- C++的标识符的作用域与可见性
下面是关于C++的标识符的作用域与可见性学习记录,仅供参考 标识符的作用域与可见性 作用域是一个标识符在程序正文中有效的区域. 作用域分类 ①函数原型作用域 ②局部作用域(快作用域) ③类作用域 ④文 ...
- LNMP配置——PHP安装
一.下载 #cd /usr/local/src //软件包都放在这里方便管理 #wget http://cn2.php.net/distributions/php-5.6.30.tar.gz 二.解压 ...
- imagemagick 之 Fred's ImageMagick Scripts 在Ubuntu 下的实践
Fred's ImageMagick Scripts 官网:http://www.fmwconcepts.com/imagemagick/index.php Windows 10 (64-bit) u ...
- 攻防世界 resver catch-me
catch-me asis-ctf-quals-2016 附件给了个压缩包文件,重命名,解压,获取到elf文件 程序有两处关键比较 第一处: 这里进行动态调试,得到v3=0xB11924E1, byt ...
- concurrentHashMap扩容相关方法详解
上一个博客中说到了concurrentHashMap的put操作,在put操作之后如果添加了节点,我们首先会把全局的节点数+1,如果满足了扩容条件,我们则进行扩容 我们先从addCount方法说起 / ...
- J. Cole 的 InnoDB 系列 - 1. 学习 InnoDB - 深入探索核心原理之旅
原文地址:https://blog.jcole.us/2013/01/02/on-learning-innodb-a-journey-to-the-core/,本系列翻译会在其基础上扩展一些 MySQ ...