Machine Learning for hackers读书笔记(二)数据分析
#均值:总和/长度
mean()
#中位数:将数列排序,若个数为奇数,取排好序数列中间的值.若个数为偶数,取排好序数列中间两个数的平均值
median()
#R语言中没有众数函数
#分位数
quantile(data):列出0%,25%,50%,75%,100%位置处的数据
#可自己设置百分比
quantile(data,probs=0.975)
#方差:衡量数据集里面任意数值与均值的平均偏离程度
var()
#标准差:
sd()
#直方图,binwidth表示区间宽度为1
ggplot(heights.weights, aes(x = Height)) +geom_histogram(binwidth = 1)

#发现上图是对称的,使用直方图时记住:区间宽度是强加给数据的一个外部结构,但是它却同时揭示了数据的内部结构
#把宽度改成5
ggplot(heights.weights, aes(x = Height)) +geom_histogram(binwidth = 5)
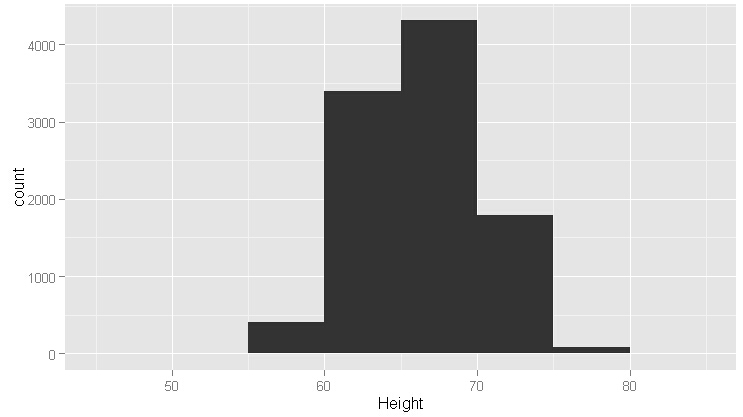
#从上图看,对称性不存在了,这叫过平滑,相反的情况叫欠平滑,如下图
ggplot(heights.weights, aes(x = Height)) +geom_histogram(binwidth = 0.01)

#因此合适的直方图需要调整宽度值.可以选择其他方式进行可视化,即密度曲线图
ggplot(heights.weights, aes(x = Height)) +geom_density()

#如上图,峰值平坦,尝试按性别划分数据
ggplot(heights.weights, aes(x = Height, fill = Gender)) +geom_density()

#混合模型,由两个标准分布混合而形成的一个非标准分布
#正态分布,钟形曲线或高斯分布
#按性别分片
ggplot(heights.weights, aes(x = Weight, fill = Gender)) +geom_density() +facet_grid(Gender ~ .)

#以下代码指定分布的均值和方差,m和s可以调整,只是移动中心或伸缩宽度
m <- 0
s <- 1
ggplot(data.frame(X = rnorm(100000, m, s)), aes(x = X)) +geom_density()
#构建出了密度曲线,众数在钟形的峰值处
#正态分布的众数同时也是均值和中位数
#只有一个众数叫单峰,两个叫双峰,两个以上叫多峰
#从一个定性划分分布有对称(symmetric)分布和偏态(skewed)分布
#对称(symmetric)分布:众数左右两边形状一样,比如正态分布
#这说明观察到小于众数的数据和大于众数的数据可能性是一样的.
#偏态(skewed)分布:说明在众数右侧观察到极值的可能性要大于其左侧,称为伽玛分布
#从另一个定性区别划分两类数据:窄尾分布(thin-tailed)和重尾分布(heavy-tailed)
#窄尾分布(thin-tailed)所产生的值通常都在均值附近,可能性有99%
#柯西分布(Cauchy distribution)大约只有90%的值落在三个标准差内,距离均值越远,分布特点越不同
#正态分布几乎不可能产生出距离均值有6个标准差的值,柯西分布有5%的可能性
#产生正态分布及柯西分布随机数
set.seed(1)
normal.values <- rnorm(250, 0, 1)
cauchy.values <- rcauchy(250, 0, 1)
range(normal.values)
range(cauchy.values)
#画图
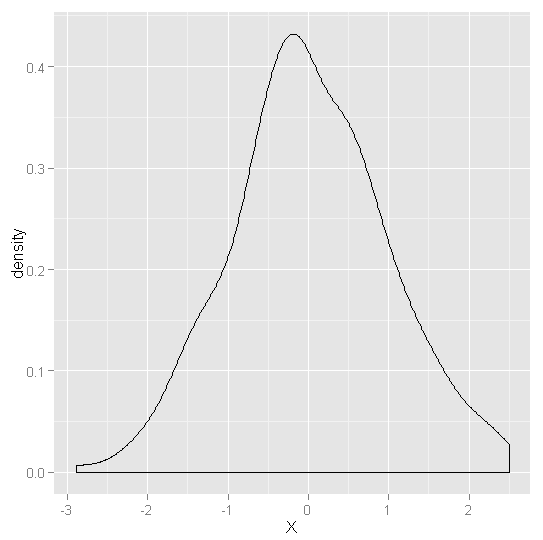
ggplot(data.frame(X = normal.values), aes(x = X)) +geom_density()
ggplot(data.frame(X = cauchy.values), aes(x = X)) +geom_density()
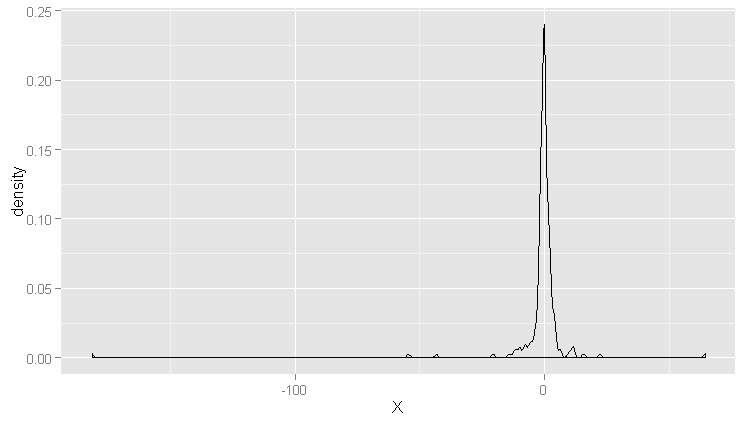
#正态分布:单峰,对称,钟形窄尾
#柯西分布:单峰,对称,钟形重尾
#产生gamma分布随机数
gamma.values <- rgamma(100000, 1, 0.001)
ggplot(data.frame(X = gamma.values), aes(x = X)) +geom_density()

#游戏数据很多都符合伽玛分布
#伽玛分布只有正值
#指数分布:数据集中频数最高是0,并且只有非负值出现
#例如,企业呼叫中心常发现两次收到呼叫请求的间隔时间看上去符合指数分布
#散点图
ggplot(heights.weights, aes(x = Height, y = Weight)) +geom_point()
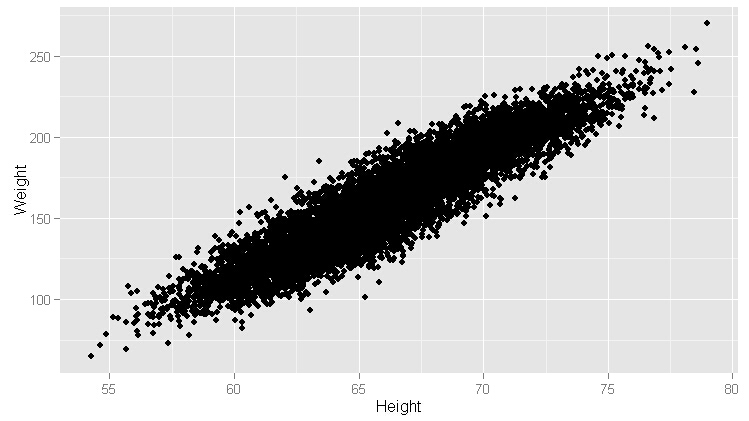
#加平滑模式
ggplot(heights.weights, aes(x = Height, y = Weight)) +geom_point() +geom_smooth()
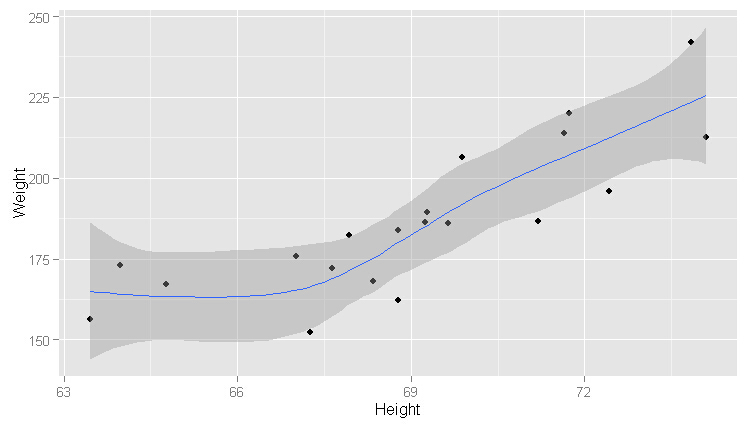
ggplot(heights.weights[1:20, ], aes(x = Height, y = Weight)) +geom_point() +geom_smooth()
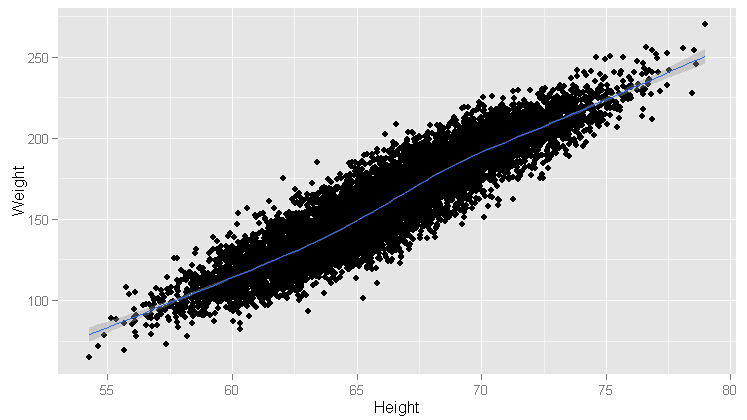
ggplot(heights.weights[1:200, ], aes(x = Height, y = Weight)) +geom_point() +geom_smooth()

ggplot(heights.weights[1:2000, ], aes(x = Height, y = Weight)) +geom_point() +geom_smooth()

ggplot(heights.weights, aes(x = Height, y = Weight)) +
geom_point(aes(color = Gender, alpha = 0.25)) +
scale_alpha(guide = "none") +
scale_color_manual(values = c("Male" = "black", "Female" = "gray")) +
theme_bw()
# An alternative using bright colors.
ggplot(heights.weights, aes(x = Height, y = Weight, color = Gender)) +
geom_point()
#
# Snippet 35
#
heights.weights <- transform(heights.weights,
Male = ifelse(Gender == 'Male', 1, 0))
logit.model <- glm(Male ~ Weight + Height,
data = heights.weights,
family = binomial(link = 'logit'))
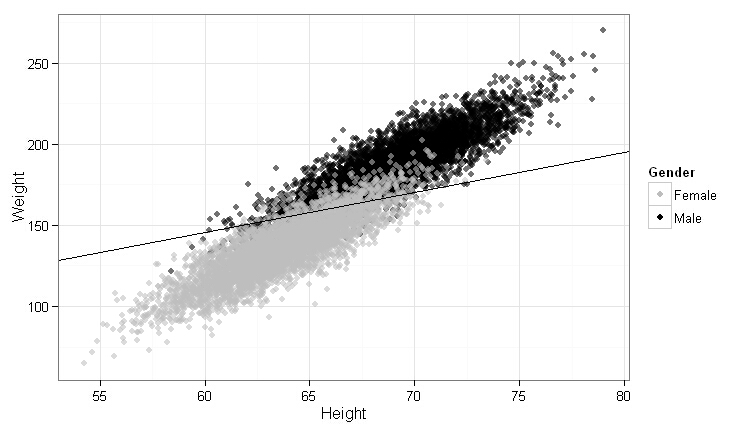
ggplot(heights.weights, aes(x = Height, y = Weight)) +
geom_point(aes(color = Gender, alpha = 0.25)) +
scale_alpha(guide = "none") +
scale_color_manual(values = c("Male" = "black", "Female" = "gray")) +
theme_bw() +
stat_abline(intercept = -coef(logit.model)[1] / coef(logit.model)[2],
slope = - coef(logit.model)[3] / coef(logit.model)[2],
geom = 'abline',
color = 'black')
Machine Learning for hackers读书笔记(二)数据分析的更多相关文章
- Machine Learning for hackers读书笔记(十二)模型比较
library('ggplot2')df <- read.csv('G:\\dataguru\\ML_for_Hackers\\ML_for_Hackers-master\\12-Model_C ...
- Machine Learning for hackers读书笔记(十)KNN:推荐系统
#一,自己写KNN df<-read.csv('G:\\dataguru\\ML_for_Hackers\\ML_for_Hackers-master\\10-Recommendations\\ ...
- Machine Learning for hackers读书笔记(七)优化:密码破译
#凯撒密码:将每一个字母替换为字母表中下一位字母,比如a变成b. english.letters <- c('a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i' ...
- Machine Learning for hackers读书笔记(六)正则化:文本回归
data<-'F:\\learning\\ML_for_Hackers\\ML_for_Hackers-master\\06-Regularization\\data\\' ranks < ...
- Machine Learning for hackers读书笔记(三)分类:垃圾邮件过滤
#定义函数,打开每一个文件,找到空行,将空行后的文本返回为一个字符串向量,该向量只有一个元素,就是空行之后的所有文本拼接之后的字符串 #很多邮件都包含了非ASCII字符,因此设为latin1就可以读取 ...
- Machine Learning for hackers读书笔记_一句很重要的话
为了培养一个机器学习领域专家那样的直觉,最好的办法就是,对你遇到的每一个机器学习问题,把所有的算法试个遍,直到有一天,你凭直觉就知道某些算法行不通.
- Machine Learning for hackers读书笔记(九)MDS:可视化地研究参议员相似性
library('foreign') library('ggplot2') data.dir <- file.path('G:\\dataguru\\ML_for_Hackers\\ML_for ...
- Machine Learning for hackers读书笔记(八)PCA:构建股票市场指数
library('ggplot2') prices <- read.csv('G:\\dataguru\\ML_for_Hackers\\ML_for_Hackers-master\\08-PC ...
- Machine Learning for hackers读书笔记(五)回归模型:预测网页访问量
线性回归函数 model<-lm(Weight~Height,data=?) coef(model):得到回归直线的截距 predict(model):预测 residuals(model):残 ...
随机推荐
- HDOJ 1428 漫步校园
漫步校园 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- hadoop配置错误
经过上一周的郁闷期(拖延症引发的郁闷),今天终于开始步入正轨了.今天主要是解决hadoop配置的错误以及网络时断时续的问题. 首先说明一下之前按照这篇文章的方法配置完全没有问题,但是等我配置好了发现h ...
- POJ 2531 Network Saboteur (枚举+剪枝)
题意:给你一个图,图中点之间会有边权,现在问题是把图分成两部分,使得两部分之间边权之和最大. 目前我所知道的有四种做法: 方法一:状态压缩 #include <iostream> #inc ...
- iOS视频压缩
// // ViewController.m // iOS视频测试 // // Created by apple on 15/8/19. // Copyright (c) 2015年 tqh. All ...
- ExtJs布局之table
<!DOCTYPE html> <html> <head> <title>ExtJs</title> <meta http-equiv ...
- (转)【移动开发】Android中三种超实用的滑屏方式汇总(ViewPager、ViewFlipper、ViewFlow)
转自: http://smallwoniu.blog.51cto.com/3911954/1308959 现如今主流的Android应用中,都少不了左右滑动滚屏这项功能,(貌似现在好多人使用智能机都习 ...
- 错误处理--pure specifier can only be specified for functions
错误处理--pure specifier can only be specified for functions 今天下载了log4cpp的源代码,在VC6下编译时出现错误: ..\..\includ ...
- linq 常用语句
自己练习的 switch (productDataAnalysisQuery.DataType) { : var data = (from hp in GPEcontext.hbl_product j ...
- Hadoop基础教程之HelloWord
上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello Word. OK,我们先来看一下当时在命令行里输入的内容: ...
- Discuss!X3.2 绑定微信
完整程序 http://pan.baidu.com/s/1jGL5veQ 密码kgga Discuz!X3.2 在继承和完善 Discuz!X3.1 的基础上,针对社区移动端进行了新的尝试.新版本主要 ...