手写LRU热点缓存数据结构
引言
LRU是开发过程中设计缓存的常用算法,在此基础上,如何设计一个高效的缓存呢?本文就带大家分析并手撸一个LRUCache。
LRU算法
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
如何储存
做为缓存,它应该有查询速度快,同时尽可能的修改也快,怎么储存才能查询速度能够保证的情况下,尽可能地提高缓存的修改速度?
使用数组
如果使用数组,可以肯定的是,它的查询速度肯定快,因为它的查询是通过索引下标来进行的,天然速度很快。但是数组大小一旦固定下来,它是不可变的,即使是我们的ArrayList,它要在扩容的时候,效率依然较低。同时如果对数组进行了删除操作,所以的位于被删除结点后面的结点都应该往前移动,它的花销不容小觑。
使用链表
对于链表而言,它的查询速度很慢,因为链表中的查询是通过for遍历来查找的,在最坏的情况下,时间复杂度为O(n),其中n是指当前链表的长度。虽然java中的LinkedList是通过双向队列来实现的,它的效果也依然较慢
高效LRUCache储存方案
通过对以上问题的思考,要想提高LRUCache的查询修改效率,就必须合理设计其中的数据结构。
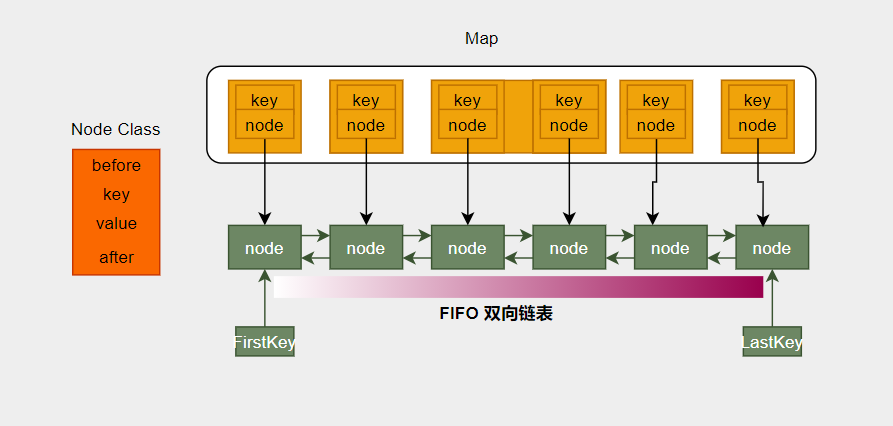
本文中,通过HashMap 和 链表组合使用的方式,来提高LRUCache的查询、修改效率。
HashMap中记录着每一个K值,和与之对应的Node结点,如果只是查询,通过map.get(key)操作,能够快速的将结果查询出来,根据LRU理论,如果数据被访问过,那么它将来被再次访问的几率也更高,所以需要将被访问的数据移至尾部(存放最热的数据)
当LRUCache的容量被使用完后,对于冷数据(相对于热点数据)而言,再次插入的时候,应该将冷数据移出,并把刚刚插入的数据加在尾部(热点数据存在于末尾)。也就是所谓的FIFO(先进先出)。
代码实现
Node结点
采用双向队列(前驱结点、后驱结点、当前Node的ket,当前Node的value)
class Node {
//前驱结点
private Node before;
//当前结点的key值
private String key;
//当前结点的value值
private T value;
//后驱结点
private Node after;
}
LRUCache类
//头结点
private String firstKey;
//尾结点
private String lastKey;
//最大容量
private int capacity;
/**
* map
*/
private Map<String, Node> map;
/**
* 构造一个指定容量的LRUCache
*
* @param capacity
*/
public LRUCache(int capacity) {
this.capacity = capacity;
map = new HashMap<>(this.capacity);
}
/**
* 构造一个无容量限制的LRUCache
*/
public LRUCache() {
this.capacity = Integer.MAX_VALUE;
map = new HashMap<>();
}
添加缓存
新添加的缓存作为热点数据放在链尾,当缓存容量不够时,移除头部的非热点数据
/**
* 添加或更新缓存
*
* @param key key值
* @param value 缓存对象
*/
public void put(String key, T value) {
Node node = map.get(key);
if (node == null) {
if (map.size() >= capacity) {
this.removeMode();
}
node = addNewNode(key);
node.key = key;
node.value = value;
map.put(key, node);
} else {
changeNodeToLast(node);
node.key = key;
node.value = value;
}
}
/**
* 添加新结点到末尾
*
* @param key key值
* @return 添加好的结点
*/
private Node addNewNode(String key) {
Node newNode = new Node();
if (firstKey == null) {
//第一次添加,直接添加到开始位置
firstKey = key;
} else if (lastKey == null) {
//第二次添加,添加到末尾,和head结点互相连接
lastKey = key;
Node firstNode = map.get(firstKey);
newNode.before = firstNode;
firstNode.after = newNode;
} else {
//当头和尾都有Node的时候,添加到末尾
Node lastNode = map.get(lastKey);
newNode.before = lastNode;
lastNode.after = newNode;
lastKey = key;
}
return newNode;
}
/**
* 移除头结点
*/
private void removeMode() {
Node firstNode = map.get(firstKey);
map.remove(firstKey);
if (firstNode.after != null) {
firstKey = firstNode.after.key;
firstNode.after.before = null;
} else {
//只有一个结点
firstKey = null;
lastKey = null;
}
}
查询缓存
对于存在的缓存,经过了一次查询后,应该将其作为热点数据放到链尾
/**
* 查询缓存
*
* @param key
* @return
*/
public T get(String key) {
Node node = map.get(key);
if (node != null) {
changeNodeToLast(node);
return node.value;
}
return null;
}
/**
* 将热点缓存移到尾部
*
* @param node
*/
private void changeNodeToLast(Node node) {
//如果还没有结点,则node就是firstNode
if (firstKey == null) {
firstKey = node.key;
}
//判断是否已经是尾结点
if (lastKey.equals(node.key)) {
return;
}
//判断是否是头结点
if (firstKey.equals(node.key)) {
//如果是头结点,而且没有下个结点,则只有一个结点,直接返回
if (node.after == null) {
return;
}
//如果是是头结点,且存在多个结点
firstKey = node.after.key;
}
Node a = node.after;
Node b = node.before;
if (b != null) {
b.after = a;
}
if (a != null) {
a.before = b;
}
Node lastNode = map.get(lastKey);
lastKey = node.key;
node.before = lastNode;
lastNode.after = node;
lastNode = node;
lastNode.after = null;
}
删除缓存
删除的时候,如果删除的正是头结点或尾结点,则需要更改firstKey或lastKey
/**
* 删除缓存
*
* @param key 要删除的缓存key值
* @return
*/
public boolean delete(String key) {
Node removeNode = map.remove(key);
if (removeNode == null) {
return false;
} else {
Node a = removeNode.after;
Node b = removeNode.before;
//如果是头结点需要移动firstKey指针
if (key.equals(firstKey)) {
firstKey = a.key;
} else if (key.equals(lastKey)) {
//如果是尾结点需要移动lastkey指针
lastKey = b.key;
}
if (a != null) {
a.before = b;
}
if (b != null) {
b.after = a;
}
return true;
}
}
完整代码
public class LRUCache<T> {
class Node {
//前驱结点
private Node before;
//当前结点的key值
private String key;
//当前结点的value值
private T value;
//后驱结点
private Node after;
}
//头结点
private String firstKey;
//尾结点
private String lastKey;
//最大容量
private int capacity;
/**
* map
*/
private Map<String, Node> map;
/**
* 构造一个指定容量的LRUCache
*
* @param capacity
*/
public LRUCache(int capacity) {
this.capacity = capacity;
map = new HashMap<>(this.capacity);
}
/**
* 构造一个无容量限制的LRUCache
*/
public LRUCache() {
this.capacity = Integer.MAX_VALUE;
map = new HashMap<>();
}
/**
* 添加新结点到末尾
*
* @param key key值
* @return 添加好的结点
*/
private Node addNewNode(String key) {
Node newNode = new Node();
if (firstKey == null) {
//第一次添加,直接添加到开始位置
firstKey = key;
} else if (lastKey == null) {
//第二次添加,添加到末尾,和head结点互相连接
lastKey = key;
Node firstNode = map.get(firstKey);
newNode.before = firstNode;
firstNode.after = newNode;
} else {
//当头和尾都有Node的时候,添加到末尾
Node lastNode = map.get(lastKey);
newNode.before = lastNode;
lastNode.after = newNode;
lastKey = key;
}
return newNode;
}
/**
* 移除头结点
*/
private void removeMode() {
Node firstNode = map.get(firstKey);
map.remove(firstKey);
if (firstNode.after != null) {
firstKey = firstNode.after.key;
firstNode.after.before = null;
} else {
//只有一个结点
firstKey = null;
lastKey = null;
}
}
/**
* 将热点缓存移到尾部
*
* @param node
*/
private void changeNodeToLast(Node node) {
//如果还没有结点,则node就是firstNode
if (firstKey == null) {
firstKey = node.key;
}
//判断是否已经是尾结点
if (lastKey.equals(node.key)) {
return;
}
//判断是否是头结点
if (firstKey.equals(node.key)) {
//如果是头结点,而且没有下个结点,则只有一个结点,直接返回
if (node.after == null) {
return;
}
//如果是是头结点,且存在多个结点
firstKey = node.after.key;
}
Node a = node.after;
Node b = node.before;
if (b != null) {
b.after = a;
}
if (a != null) {
a.before = b;
}
Node lastNode = map.get(lastKey);
lastKey = node.key;
node.before = lastNode;
lastNode.after = node;
lastNode = node;
lastNode.after = null;
}
/**
* 查询缓存
*
* @param key
* @return
*/
public T get(String key) {
Node node = map.get(key);
if (node != null) {
changeNodeToLast(node);
return node.value;
}
return null;
}
/**
* 添加缓存
*
* @param key key值
* @param value 缓存对象
*/
public void put(String key, T value) {
Node node = map.get(key);
if (node == null) {
if (map.size() >= capacity) {
this.removeMode();
}
node = addNewNode(key);
node.key = key;
node.value = value;
map.put(key, node);
} else {
changeNodeToLast(node);
node.key = key;
node.value = value;
}
}
/**
* 删除缓存
*
* @param key 要删除的缓存key值
* @return
*/
public boolean delete(String key) {
Node removeNode = map.remove(key);
if (removeNode == null) {
return false;
} else {
Node a = removeNode.after;
Node b = removeNode.before;
//如果是头结点需要移动firstKey指针
if (key.equals(firstKey)) {
firstKey = a.key;
} else if (key.equals(lastKey)) {
//如果是尾结点需要移动lastkey指针
lastKey = b.key;
}
if (a != null) {
a.before = b;
}
if (b != null) {
b.after = a;
}
return true;
}
}
/**
* 输出
*/
public void print() {
Node node = map.get(firstKey);
while (node != null) {
System.out.println(node.value);
node = node.after;
}
}
}
以上代码并未考虑线程安全问题
手写LRU热点缓存数据结构的更多相关文章
- java 手写 jvm高性能缓存
java 手写 jvm高性能缓存,键值对存储,队列存储,存储超时设置 缓存接口 package com.ws.commons.cache; import java.util.function.Func ...
- HashMap+双向链表手写LRU缓存算法/页面置换算法
import java.util.Hashtable; class DLinkedList { String key; //键 int value; //值 DLinkedList pre; //双向 ...
- python实现LRU热点缓存
基于列表+Hash的LRU算法实现. 访问某个热点时,先将其从原来的位置删除,再将其插入列表的表头 为使读取及删除操作的时间复杂度为O(1),使用hash存储热点的信息的键值 class LRUCac ...
- Javascript 手写 LRU 算法
LRU 是 Least Recently Used 的缩写,即最近最少使用.作为一种经典的缓存策略,它的基本思想是长期不被使用的数据,在未来被用到的几率也不大,所以当新的数据进来时我们可以优先把这些数 ...
- 第三节:工厂+反射+配置文件(手写IOC)对缓存进行管理。
一. 章前小节 在前面的两个章节,我们运用依赖倒置原则,分别对 System.Web.Caching.Cache和 System.Runtime.Cacheing两类缓存进行了封装,并形成了ICach ...
- 手写LRU算法
import java.util.LinkedHashMap; import java.util.Map; public class LRUCache<K, V> extends Link ...
- 手写LRU实现
完整基于 Java 的代码参考如下 class DLinkedNode { String key; int value; DLinkedNode pre; DLinkedNode post; } LR ...
- 面试题目:手写一个LRU算法实现
一.常见的内存淘汰算法 FIFO 先进先出 在这种淘汰算法中,先进⼊缓存的会先被淘汰 命中率很低 LRU Least recently used,最近最少使⽤get 根据数据的历史访问记录来进⾏淘汰 ...
- java手写多级缓存
多级缓存实现类,时间有限,该类未抽取接口,目前只支持两级缓存:JVM缓存(实现 请查看上一篇:java 手写JVM高性能缓存).redis缓存(在spring 的 redisTemplate 基础实现 ...
- 《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU
你知道的越多,你不知道的越多 点赞再看,养成习惯 前言 Redis在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在Redis的使用和原理方面对小伙伴们进行360°的刁难.作为一个在互联 ...
随机推荐
- Apache Dubbo 3.0.0 正式发布 - 全面拥抱云原生
简介: 一个新的里程碑! 一.背景 自从 Apache Dubbo 在 2011 年开源以来,在一众大规模互联网.IT公司的实践中积累了大量经验后,Dubbo 凭借对 Java 用户友好.功能丰富.治 ...
- 获国际架构顶会ATC2021最佳论文!Fuxi2.0去中心化的调度架构详解
简介: 近日,在国际体系架构顶会USENIX ATC2021上,阿里云飞天伏羲团队与香港中文大学合作的一篇论文<Scaling Large Production Clusters with Pa ...
- [FAQ] puppeteer 清空输入框的值 并 重新输入
一种方式是,清空输入框可以通过如下注入代码实现,但是可能存在 和页面本身的操作 存在优先级问题. await page.evaluate( () => document.getElementBy ...
- [FAQ] IDE: Goland 注释符后面添加空行
如图所示,Code Style 对应语言 Go 勾选上注释空行的选项. Refer:Goland官网 Goland下载 Link:https://www.cnblogs.com/farwish/p/1 ...
- [FE] Canvas 转图片并下载的方式
先获取 canvas 节点,使用 toDataURL 转为 image 数据,最后使用 a 链接下载. // Trans to image const canvas = document.getEle ...
- [ML] 机器学习简介
监督学习(Supervised Learning) 添加标签,手把手训练. 比如线性回归算法. 半监督学习(Semi-supervised Learning) 非监督学习(Unsupervised L ...
- WPF 布局 在有限空间内让两个元素尽可能撑开的例子
我在尝试写一个显示本机 WIFI 热点的账号和密码的控件,要求此控件在有限的空间内显示.但是尽可能显示出热点的账号和密码.而热点的账号和密码是用户配置的,也许长度很长.我的需求是在假如账号的长度较短的 ...
- c++图像处理程序编译成.so动态链接库供Java调用(包含jni文件与引用第三方动态链接库opencv)
一.linux编译so文件需要准备的环境 1.安装JDK(注意:不能安装openjdk,因为openjdk没有include目录,编译时需要用到include目录的头文件) 2.安装gcc和g++ ...
- XPRA: SAP传输后自动运行程序
今天了解到一个功能,允许TR导入后自动运行指定程序.比如使用VOFM创建新的例程后,需要运行RV80HGEN来重新生成程序.可以在TR中包含以下对象,则TR导入完成后,会自动运行RV80HGEN. P ...
- centos中普通用户使用sudo报错:centos is not in the sudoers file. This incident will be reported.
centos中普通用户使用sudo报错:centos is not in the sudoers file. This incident will be reported. su - chmod u+ ...