LORS:腾讯提出低秩残差结构,瘦身模型不掉点 | CVPR 2024
深度学习模型通常堆叠大量结构和功能相同的结构,虽然有效,但会导致参数数量大幅增加,给实际应用带来了挑战。为了缓解这个问题,
LORS(低秩残差结构)允许堆叠模块共享大部分参数,每个模块仅需要少量的唯一参数即可匹配甚至超过全量参数的性能。实验结果表明,LORS减少解码器 70% 的参数后仍可达到与原始模型相当甚至更好的性能来源:晓飞的算法工程笔记 公众号
论文: LORS: Low-rank Residual Structure for Parameter-Efficient Network Stacking

Introduction
在当前大模型繁荣的时代,一个普遍的问题是参数量大幅增加,这给训练、推理和部署带来了挑战。目前有各种方法来减少模型中的参数数量,例如知识蒸馏,将大型模型压缩为较小的模型,同时试图保持其性能,但仍可能导致模型容量的下降;剪枝,从模型中删除冗余参数,但会影响模型的稳定性;量化,降低模型参数的数值精度,降低存储和计算量,但可能会导致模型精度损失;参数共享,通过在不同层之间共享参数来减少参数数量,但可能会限制模型的表达能力。
与上述方法不同,论文观察到一个导致参数数量庞大的重要事实:层堆叠在神经网络中的广泛使用。层堆叠是指那些具有相同架构并执行相同或相似功能的模块,但由于随机初始化和训练更新而具有不同的参数。堆叠的例子可以在许多著名的神经网络中找到,比如经典的ResNet模型和Transformers。特别是,Transformers严重依赖堆栈结构,并且通常在编码器和解码器中采用完全相同的多层堆栈。现在它已成为计算机视觉、自然语言处理等领域许多优秀模型不可或缺的组成部分。
尽管层堆叠对于增强模型容量非常有效,但也会导致参数数量的急剧增加。例如,GPT-3使用 1750 亿个参数,由 96 个堆叠的Transformer层组成。如何才能享受堆栈带来的好处,同时减少所需的参数数量?论文注意到堆叠的解码器具有相同的结构和相似的功能,这表明它们的参数之间应该存在一些共性。然而,由于它们处理不同的输入和输出分布,因此它们的参数也必须有独特的方面。因此,一个自然的想法是:也许可以用共享参数来表示共享方面,同时允许每个堆叠模块仅保留捕获其独特特征的参数,从而减少总体参数使用。
基于上述考虑,论文建议将堆叠模块的参数分解为两部分:代表共性的共享参数和捕获特定特征的私有参数。共享参数可供所有模块使用并共同训练,而私有参数则由每个模块单独拥有,在保持模型性能的同时减少参数量。为了实现这一目标,受LoRA方法的启发,论文引入了低秩残差结构 (LORS) 的概念,本质上是将私有参数添加到共享参数中,就像残差连接将残差信息添加到特征中一样。
为了验证论文的想法,选择AdaMixer(一个强大的基于查询的对象检测器)作为实验对象。其堆叠的解码器中包含大量自适应和静态参数,是展示LORS有效性的理想候选者。自适应参数和静态参数的区别在于是否随着不同的输入而变化,而论文的目标是证明LORS可以有效减少两类参数的总体使用,同时保持模型的性能。对此检测器进行的广泛实验表明,LORS成功地减少了AdaMixer解码器中高达 70% 的参数,同时能够实现与其普通版本相当甚至更优越的性能。
总之,论文的贡献可以总结为:
- 论文提出了用于堆叠网络的新颖低秩残差结构
LORS,与普通结构相比,在大幅减少参数数量的同时保持甚至提高性能。 - 论文引入有效的方法来减少堆叠结构中的静态参数和自适应生成参数,这使得论文提出的
LORS更加通用。 - 论文的方法有潜力作为大型模型的基本网络结构之一,这些模型受到堆叠网络导致的参数过多问题的影响很大。
LORS能使参数更加高效,从而在实际应用中更容易实现。
Approach
Preliminary
The mechanism of LoRA
低秩适应(LoRA)技术是一种新颖的方法,使大型预训练语言模型能够适应特定任务。LoRA的关键思想是引入一个低秩参数矩阵,该矩阵能够捕获任务相关的知识,同时保持原始预训练参数固定。
从数学角度来看,给定一个预训练的参数矩阵 \(W\in \mathbb{R}^{d\times h}\),LoRA使用低秩矩阵 \(B\in\mathbb{R}^{d\times r}\) 和投影矩阵 \(A\in\mathbb{R}^{r\times h}\) 来适应 \(W\) ,其中秩 \(r\ll d,h\)。适应的参数矩阵由以下计算:
\quad\quad(1)
\]
其中\(BA\) 用于捕获特定于任务的知识。
LoRA的主要优势在于显着减少需要微调的参数量,从而降低计算成本以及内存需求。在某些情况下,即使个位数值的秩 \(r\) 也足以将模型微调到所需状态,比直接训练 \(W\) 中的参数的开销少数十倍。此外,通过固定原始参数,LoRA避免了灾难性遗忘,这是微调大型模型时的常见问题。
Query-based object detection
在对象检测领域,基于查询的检测器建立了一种新的范例,利用一组可学习的查询向量与图像特征图进行交互:
\quad\quad(2)
\]
其中 \(Q\)、\(K\) 和 \(V\) 表示查询、键和值。可学习查询 \(Q\) 最终用于预测对象类和边界框,而 \(K\) 和 \({\cal{V}}\) 通常为编码的图像特征。经过连续的解码层,\(Q\) 不断地与 \(K\) 和 \(V\) 交互来细化是一种常见的做法,而这些层通常由结构相同的解码器组成。
Decoders of AdaMixer
AdaMixer是一种基于查询的检测器,添加自适应通道混合(ACM)和自适应空间混合(ASM)方法,大大增强了性能。
给定一个采样特征 \({\textbf{x}}\in\ \mathbb{R}^{P_{\mathrm{in}}\times C}\),其中 \(\textstyle C\ = d_{feat/g}\),\(g\) 为采样组数。采样特征通过组采样操作获得的,该操作将每个多尺度特征的空间通道 \(d_{feat}\) 划分为 \(g\) 组,然后对每个组内特征进行单独3D采样操作,得到的多组采样特征分别进行后续的ACM和ASM操作。
首先对采样特征执行ACM(自适应通道混合)操作,根据对象查询 \(\mathbf{q}\) 生成的自适应权重在通道维度转换特征 \(\mathbf{x}\),增强通道语义:
{{M_{c}=\mathrm{{Linear}(\mathbf{q})}\in\mathbb{R}^{C\times C}}}
\quad\quad(3)
\\
{{\mathrm{ACM}({\bf x})=\mathrm{{ReL}}\mathrm{U(LayerNorm}({\bf x}M_{c}))}}
\quad\quad(4)
\end{array}
\]
随后对通道增强的采样特征执行ASM(自适应空间混合)操作,通过对空间维度应用自适应变换,使得对象查询 \(\mathbf{q}\) 能够适应采样特征的空间结构:
{{M_{s}=\mathrm{{Linear}(\mathbf{q})}\in\mathbb{R}^{P_{\mathrm{in}}\times P_{\mathrm{out}}}}}
\quad\quad(5)
\\
{{\mathrm{ASM}(\mathbf{x})=\mathrm{ReLU}(\mathrm{LayerNorm}(\mathbf{x}^{T}M_{s}))}}
\quad\quad(6)
\end{array}
\]
ACM和ASM都为每个采样组训练独立的参数,最后整合多组输出将形状为 \(\mathbb{R}^{g\times C\times P_{out}}\) 的合并输出展平并通过线性层 \(L_{\mathrm{output}}\) 输出转换为 \(d_{q}\)维度,添加到原对象查询中。
与解码器的其他操作相比,ACM、ASM和输出线性变换 \(L_{\mathrm{output}}\) 拥有更多的参数,是模型参数量的主要贡献者。因此,论文选择它们作为目标组件来验证LORS方法在参数减少方面的有效性。
Formulation of Our Method
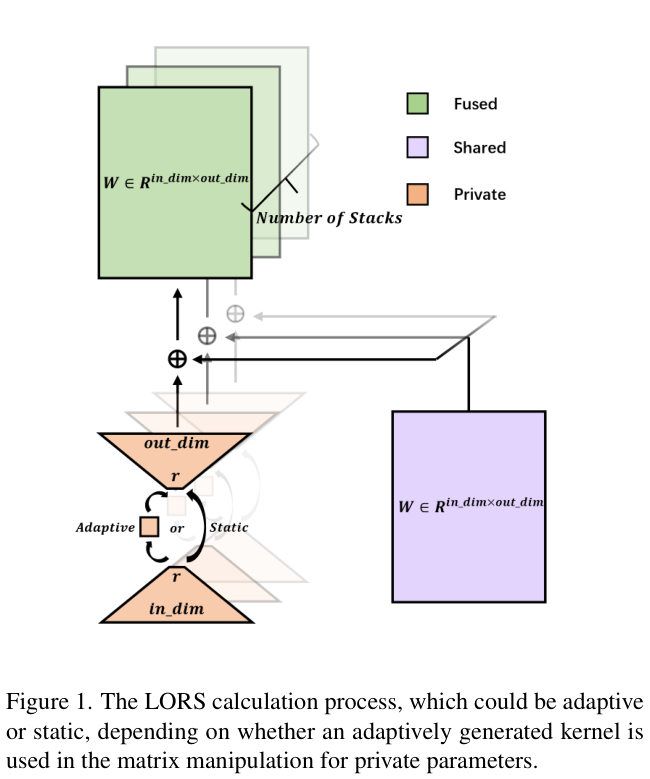
LORS的完整计算过程如图 1 所示,分为两种类型:自适应计算和静态计算。其中,“自适应”表示变换矩阵是否依赖于对象查询。
Static Low Rank Residual Structure (\(\mathrm{LORS}^\mathrm{T}\))
假设单个模块包含 \(N\) 个具有相同架构的堆叠层,并且 \(W_{i}\in\mathbb{R}^{d\times h}\) 是第 \(i\) 层的参数矩阵,则有:
\quad\quad(7)
\]
\(W^{\mathrm{shared}}\) 为所有堆叠层的共享参数,\(W_{i}^{\mathrm{private}}\) 为第 \(i\) 层的私有参数,其计算如下:
\quad\quad(8)
\]
\(B_{ik}\in\mathbb{R}^{d\times r}\),\(A_{ik}\in\mathbb{R}^{r\times h}\),其中秩 \(r\ll d\)。\(K\) 为用于计算\(W_{i}^{\mathrm{private}}\) 的参数组的数量。

\(\mathrm{LORS}^\mathrm{T}\) 计算 \(W_{i}^{\mathrm{private}}\) 的伪代码如图 2 所示。
Adaptive Low Rank Residual Structure (\(\mathrm{LORS}^\mathrm{A}\))
定义 \(\hat{W}_i\in\mathbb{R}^{d\times h}\) 为第 \(i\) 个堆叠层中自适应生成参数,其计算为:
\quad\quad(9)
\]
其中跨层共享参数 \(\hat{W}^{\mathrm{shared}}\in\mathbb{R}^{d\times h}\) 和层私有参数 \({\hat{W}}_{i}^{\mathrm{private}}\in\mathbb{R}^{d\times h}\)都是基于查询 \(q\) 计算得到的:
{{\hat{W}_{i}^{\mathrm{shared}}=\mathrm{Linear(q)}\in\mathbb{R}^{d\times h}}}
\quad\quad(10)
\\
{{\hat{W}_{i}^{\mathrm{private}}=\sum_{k=1}^{K}\hat{B}_{i k}\hat{E}_{i k}\hat{A}_{i k}}}
\quad\quad\ \ (11)
\\
{{\hat{E}_{i k}=\mathrm{Linear(q)}\in\mathbb{R}^{r\times r}}}
\quad\quad\quad\quad(12)
\end{array}
\]
其中 \(\hat{B}_{i k}\ \in\ \mathbb{R}^{d\times r}\),\({\hat{A}}_{ik}\in\mathbb{R}^{r\times h}\),秩 \(r\ll d,h\)。

\(\mathrm{LORS}^\mathrm{A}\) 计算 \({\hat{W}}_{i}^{\mathrm{Private}}\) 的伪代码如图 3 所示。
Applying LORS to AdaMixer’s Decoders
将LORS应用到AdaMixer的每个解码器的ACM、ASM和 \(L_{\mathrm{output}}\) 的线性变换的参数中。
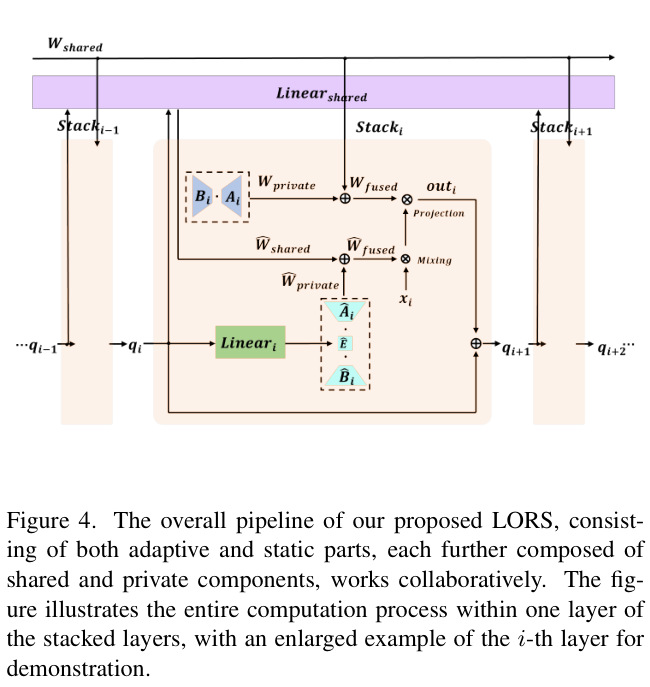
AdaMixer中运行的LORS的整体流程如图 4 所示。对于每组采样点,\(\mathrm{LORS}^\mathrm{A}\) 用于减少ACM的 \({M}_{c}\)(映射 \(\mathbb{R}^{d_q}\) 到 \(\mathbb{R}^{C\times C}\))和ASM的 \(M_{s}\) 的参数(映射 \(\mathbb{R}^{d_q}\) 到 \(\mathbb{R}^{P_{in}\times P_{out}}\),而 \(\mathrm{LORS}^\mathrm{T}\) 则用于最小化 \(L_{\mathrm{output}}\) 中的参数(映射 \(\mathbb{R}^{C\times P_{\mathrm{out}}}\) 到 \(\mathbb{R}^{d_q}\) )。
从上面括号中的映射关系可以看出,\(M_{c}\)、\(M_{s}\)、\(L_{\mathrm{output}}\) 的参数量分别为 \(d_q\times C\times C\)、\(d_{q}\times P_{\mathrm{in}}\times P_{\mathrm{out}}\)、\(d_{q}\times C\times P_{\mathrm{out}}\)。当分组采样策略由 2 组、每组 64 点组成时,变量的值为 \(d_{q}=256\)、\(C= 64\)、\(P_{\mathrm{in}}=64\) 和 \(P_{\mathrm{out}}=128\),进而计算出 \(M_{c}\)、\(M_{s}\) 和 \(L_{\mathrm{output}}\) 的参数数量均超过百万。
事实上,这三个组件共同占据了以ResNet-50为主干的AdaMixer模型总参数的大部分,同时它们也是增强模型性能的主要驱动力。综上,这也就是论文对它们进行LORS实验的动机。
Analysis on Parameter Reduction
定义 \(W\in \mathbb{R}^{d\times h}\) 为堆叠结构中每层都存在的权重参数,\(N\) 为堆叠层数:
- 如果是静态的,则原本就有 \(d\times h\) 个参数,而使用 \(\mathrm{LORS}^\mathrm{T}\) 后平均每层仅需要 \(\frac{1}{N}\times d\times h + K\times(d\times r+r\times h)\)个参数。
- 如果是自适应的,通过 \(q\) 线性变换生成需要 \(d_{q}\times d\times h\) 个参数,其中 \(d_{q}\) 是 \(q\) 的维度,使用 \(\mathrm{LORS}^\mathrm{A}\) 每层平均仅需要 \(\frac{1}{N}\times d_q\times d\times h + K\times(d_q\times r^2 + d\times r + r\times h)\) 个参数。
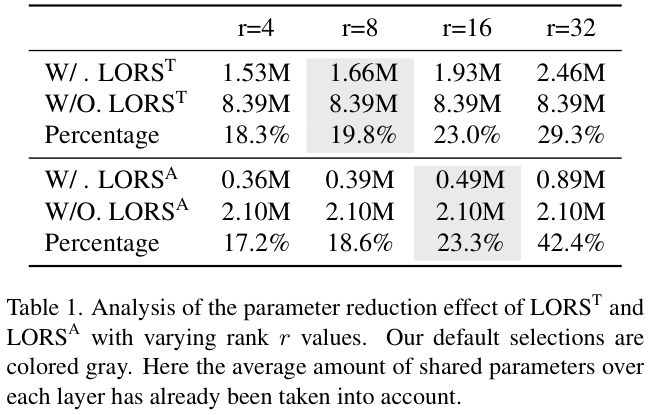
为了更直观地展示LORS的参数减少效果,在ASM设置 \(d_{q}=256\),\(d=64\),\(h=128\),\(K=2\),\(h=256\),\(L_{\mathrm{output}}\) 设置 \(d=2\times 128\times 128\),\(K\,=\,1\) 的情况下,\(\mathrm{LORS}^\mathrm{T}\) 和 \(\mathrm{LORS}^\mathrm{A}\) 对不同 \(r\) 值的参数减少情况如表 1 所示。
Experiments
Implementation Details
Training.
使用权重衰减为 0.0001 的AdamW优化器,在 8 个Nvidia V100 GPU上训练所有模型,批量大小为 16,学习率为 2.5 × e−5。模型训练 12 或 36 个 周期,对于 12 周期训练,学习率在第 8 和 11 周期下降 10 倍;对于 36 周期训练,在第 24 和 33 周期学习率下降 10 倍。
低秩值方面,\(\mathrm{LORS}^\mathrm{A}\) 设置为 \(r=16\),\(\mathrm{LORS}^\mathrm{T}\) 设置为 \(r=8\)。
所有实验中,\(\mathrm{LORS}^\mathrm{A}\) 的参数组数量设置为\(K\,=\,[1,1,2,2,3,3]\),应用于AdaMixer解码器中的ACM和ASM,而\(L_{\mathrm{output}}\)则设置为 \(K\ =\ [1,1,1,1,1,1]\)。
组采用时将特征通道分为 2 组,每组 64 个采样点,而不是AdaMixer默认的 4 组,每组 32 个采样点,旨在增加LORS的参数可压缩空间。根据AdaMixer论文和论文的实验,这并不会简介提高性能。
主干网络使用ImageNet-1k预训练模型进行初始化,LORS参数初始化如下面所示,其余参数则由Xavier初始化。关于模型训练的所有其他方面,如数据增强、损失函数等,只需遵循AdaMixer的设置即可。
Initialization Strategies
论文对LORS中的各个组件尝试了多种初始化方法,确定了整体的初始化方法如下:
- \(\mathrm{LORS}^\mathrm{T}\):对于静态
LORS,对 \(W^\mathrm{shared}\) 和每个 \({\boldsymbol{B}}\) 采用Kaiming初始化,并对每个 \(A\) 进行零初始化。 - \(\mathrm{LORS}^\mathrm{A}\):对于自适应
LORS,将Kaiming初始化每个 \(\tilde{W}^\mathrm{shared}\)、\({\hat{B}}\) 和 \({\hat{A}}\)线性变换权重。此外,论文对每个 \({\hat{E}}\) 的线性变换权重使用零初始化
Main Results
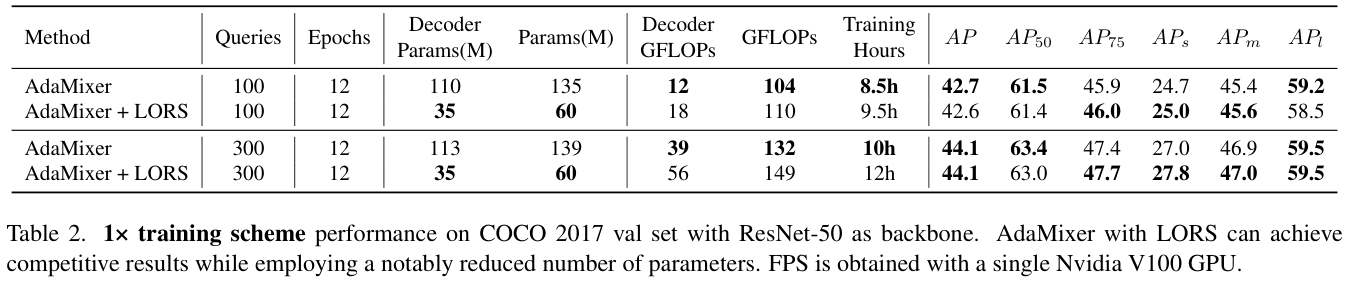
表 2 展示了在 1× 训练方案下使用和不使用LORS技术的性能比较。
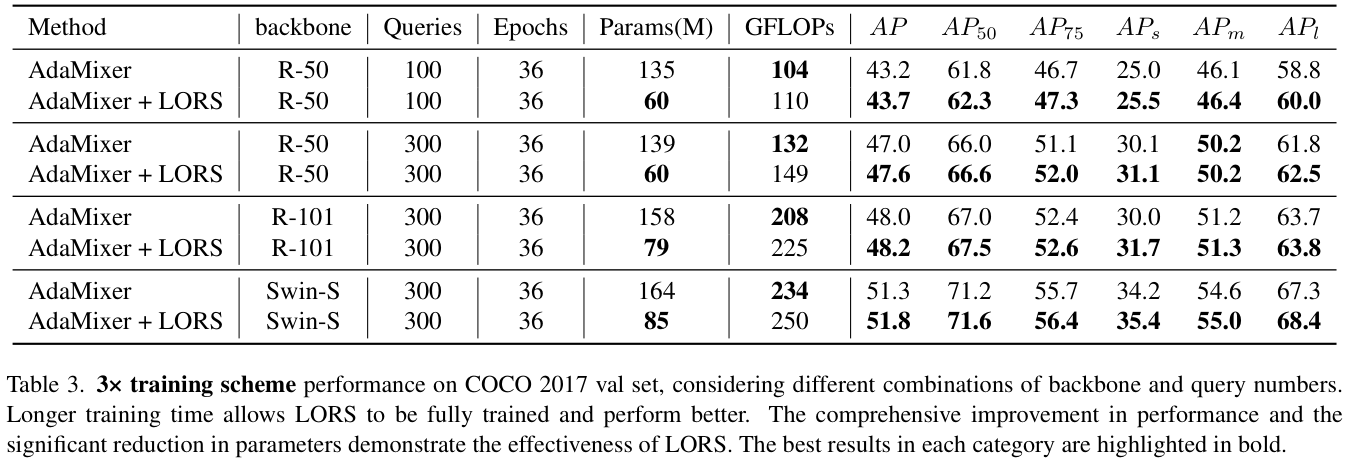
表 3 展示了AdaMixer+LORS方法在不同骨干网和查询数的3×训练方案下的性能。
Ablation Study

表 4 展示了 \(\mathrm{LORS}^\mathrm{A}\) 和 \(\mathrm{LORS}^\mathrm{T}\) 对模型参数和性能的影响进行消融研究

表 5 对比了共享权重和私有权重中哪一个对解码器的性能影响更大。
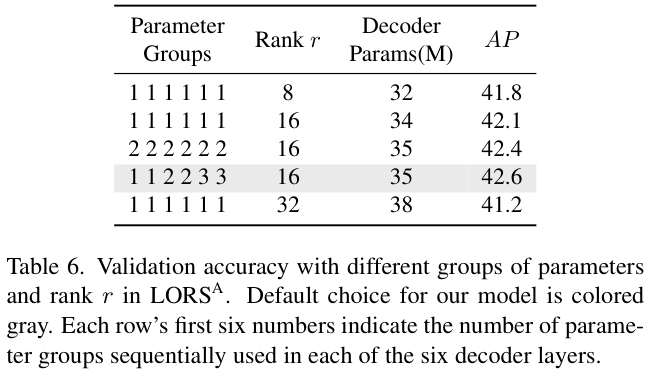
表 6 探索了自适应LORS的最佳参数组数量和秩 \(r\) 的值。
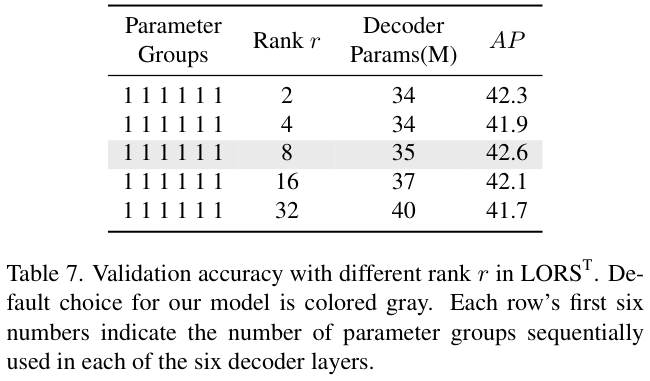
表 7 研究了 \(\mathrm{LORS}^\mathrm{T}\) 的最佳配置设置。
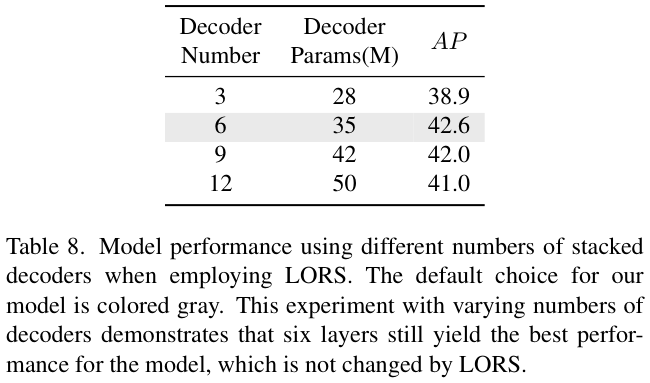
表 8 对结合LORS结构的最佳解码器层数进行实验对比。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

LORS:腾讯提出低秩残差结构,瘦身模型不掉点 | CVPR 2024的更多相关文章
- 【RS】Local Low-Rank Matrix Approximation - LLORMA :局部低秩矩阵近似
[论文标题]Local Low-Rank Matrix Approximation (icml_2013 ) [论文作者]Joonseok Lee,Seungyeon Kim,Guy Lebanon ...
- 低秩稀疏矩阵恢复|ADM(IALM)算法
一曲新词酒一杯,去年天气旧亭台.夕阳西下几时回? 无可奈何花落去,似曾相识燕归来.小园香径独徘徊. ---<浣溪沙·一曲新词酒一杯>--晏殊 更多精彩内容请关注微信公众号 "优化 ...
- DyLoRA:使用动态无搜索低秩适应的预训练模型的参数有效微调
又一个针对LoRA的改进方法: DyLoRA: Parameter-Efficient Tuning of Pretrained Models using Dynamic Search-Free Lo ...
- 吴恩达机器学习笔记59-向量化:低秩矩阵分解与均值归一化(Vectorization: Low Rank Matrix Factorization & Mean Normalization)
一.向量化:低秩矩阵分解 之前我们介绍了协同过滤算法,本节介绍该算法的向量化实现,以及说说有关该算法可以做的其他事情. 举例:1.当给出一件产品时,你能否找到与之相关的其它产品.2.一位用户最近看上一 ...
- HAWQ + MADlib 玩转数据挖掘之(四)——低秩矩阵分解实现推荐算法
一.潜在因子(Latent Factor)推荐算法 本算法整理自知乎上的回答@nick lee.应用领域:"网易云音乐歌单个性化推荐"."豆瓣电台音乐推荐"等. ...
- [转] 图解Seq2Seq模型、RNN结构、Encoder-Decoder模型 到 Attention
from : https://caicai.science/2018/10/06/attention%E6%80%BB%E8%A7%88/ 一.Seq2Seq 模型 1. 简介 Sequence-to ...
- Atitit.软件开发的三层结构isv金字塔模型
Atitit.软件开发的三层结构isv金字塔模型 第一层,Implements 层,着重与功能的实现.. 第二次,spec层,理论层,设计规范,接口,等.流程.方法论 顶层,val层,价值观层,原则, ...
- JVM内存区域的划分(内存结构或者内存模型)
JVM内存区域的划分(内存结构或者内存模型) 运行时数据区域: 根据 JVM 规范,JVM 内存共分为虚拟机栈.堆.方法区.程序计数器.本地方法栈五个部分. 程序计数器(线程私有): 是当前线程所 ...
- 谷歌大脑提出:基于NAS的目标检测模型NAS-FPN,超越Mask R-CNN
谷歌大脑提出:基于NAS的目标检测模型NAS-FPN,超越Mask R-CNN 朱晓霞发表于目标检测和深度学习订阅 235 广告关闭 11.11 智慧上云 云服务器企业新用户优先购,享双11同等价格 ...
- JVM内存结构与内存模型
这篇文章重点讲一下jvm的内存结构和内存模型的知识点.(2023.3.11) 1.内存结构 jvm内存区域主要分为线程私有区域[程序计数器,虚拟机栈,本地方法栈],线程共享区域[堆,方法区],直接内存 ...
随机推荐
- 20个Python random模块的代码示例
本文分享自华为云社区<Python随机数探秘:深入解析random模块的神奇之处>,作者:柠檬味拥抱. 标准库random函数大全:探索Python中的随机数生成 随机数在计算机科学和数据 ...
- epoll实现的简单服务器
#include "../wrap/wrap.h" #include <sys/epoll.h> #define SIZE 1024 #define FUCK prin ...
- MySQL varchar详解
说明:以下结果都是在mysql8.2及Innodb环境下测试. varcahr(255)是什么含义? varchar(255) 表示可以存储最大255个字符,至于占多少个字节由字符集决定. varch ...
- Scratch基础(一):安装和了解软件
Scratch基础(一):安装和了解软件 编写计算机程序代码的能力是当今社会读写能力的重要组成部分.当人们学习使用Scratch进行编码时,他们将学习解决问题,设计项目和交流思想的重要策略. 1.安装 ...
- windows系统命令行cmd查看显卡驱动版本号CUDA
Win+R 输入cmd 进入命令行 输入 nvidia-smi
- LiftPool:双向池化操作,细节拉满,再也不怕丢特征了 | ICLR 2021
论文参考信号处理中提升方案提出双向池化操作LiftPool,不仅下采样时能保留尽可能多的细节,上采样时也能恢复更多的细节.从实验结果来看,LiftPool对图像分类能的准确率和鲁棒性都有不错的提升,而 ...
- 12 JavaScript 关于eval函数
12 eval函数 eval本身在js里面正常情况下使用的并不多. 但是很多网站会利用eval的特性来完成反爬操作. 我们来看看eval是个什么鬼? 从功能上讲, eval非常简单. 它和python ...
- SSL新年欢乐赛暨BPM退役赛(不含FK)
目录 前言 C 大水题 题目 分析 代码 D 简单数据结构题 题目 分析 代码 H 上次题 题目 分析 代码 J 白给题 题目 分析 代码 前言 A,B水题,E,I原题 实际赛时400分(乐多毁我青春 ...
- JDK14性能管理工具:Jconsole详解
目录 简介 JConsole 概览 内存 线程 类 VM信息 MBean 总结 简介 我们在开发java项目的时候,或多或少都会去用到Java的性能管理工具.有时候是为了提升应用程序的性能,有时候是为 ...
- 组合数学——Min-Max容斥
Min-Max 容斥,即 $$\max(S)=\sum_{T\in S,T\neq\emptyset}(-1)^{|T|-1}\min(T)$$ 接下来证明上面那个式子是对的.定义 \(S\) 中共有 ...