不同大小的缓冲区对 MD5 计算速度的影响
最*需要在计算大文件的 MD5 值时显示进度,于是我写了如下的代码:
public long Length {get; private set; }
public long Position { get; private set; }
public async Task ComputeMD5Async(string file, CancellationToken cancellationToken)
{
using var fs = File.OpenRead(file);
Length = fs.Length;
var task = MD5.HashDataAsync(fs, cancellationToken);
var timer = new PeriodicTimer(TimeSpan.FromMilliseconds(10));
while (await timer.WaitForNextTickAsync(cancellationToken))
{
Position = fs.Position;
if (task.IsCompleted)
{
break;
}
}
}
运行的时候发现不对劲儿了,我的校验速度只能跑到 350MB/s,而别人的却能跑到 500MB/s,相同的设备怎么差距有这么大?带这个疑问我去看了看别人的源码,发现是这么写的:
protected long _progressPerFileSizeCurrent;
protected byte[] CheckHash(Stream stream, HashAlgorithm hashProvider, CancellationToken token)
{
byte[] buffer = new byte[1 << 20];
int read;
while ((read = stream.Read(buffer)) > 0)
{
token.ThrowIfCancellationRequested();
hashProvider.TransformBlock(buffer, 0, read, buffer, 0);
_progressPerFileSizeCurrent += read;
}
hashProvider.TransformFinalBlock(buffer, 0, read);
return hashProvider.Hash;
}
这里使用了 HashAlgorithm.TransformBlock 方法,它能计算输入字节数组指定区域的哈希值,并将中间结果暂时存储起来,最后再调用 HashAlgorithm.TransformFinalBlock 结束计算。上述代码中缓冲区 buffer 大小是 1MB,我敏锐地察觉到 MD5 计算速度可能与这个值有关,接着我又去翻了翻 MD5.HashDataAsync 的源码。
// System.Security.Cryptography.LiteHashProvider
private static async ValueTask<int> ProcessStreamAsync<T>(T hash, Stream source, Memory<byte> destination, CancellationToken cancellationToken) where T : ILiteHash
{
using (hash)
{
byte[] rented = CryptoPool.Rent(4096);
int maxRead = 0;
int read;
try
{
while ((read = await source.ReadAsync(rented, cancellationToken).ConfigureAwait(false)) > 0)
{
maxRead = Math.Max(maxRead, read);
hash.Append(rented.AsSpan(0, read));
}
return hash.Finalize(destination.Span);
}
finally
{
CryptoPool.Return(rented, clearSize: maxRead);
}
}
}
源码中最关键的是上面这部分,缓冲区 rented 设置为 4KB,与 1MB 相差甚远,原因有可能就在这里。
为了找到最佳的缓冲区值,我跑了一大堆 BenchMark,覆盖了从 32B 到 64MB 的范围。没什么技术含量,但工作量实在不小。测试使用 1GB 的文件,基准测试是对 1GB 大小的数组直接调用 MD5.HashData,实际的测试代码如下,分别使用内存流 MemoryStream 和文件流 FileStream 作为入参 Stream,对比无硬盘 IO 和实际读取文件的速度。
public async Task HashDataAsync(Stream stream)
{
var hash = MD5.Create();
byte[] buffer = new byte[1 << size];
int read = 0;
while ((read = await stream.ReadAsync(buffer)) != 0)
{
hash.TransformBlock(buffer, 0, read, buffer, 0);
}
hash.TransformFinalBlock(buffer, 0, read);
if (!(hash.Hash?.SequenceEqual(fileHash) ?? false))
{
throw new Exception("Compute error");
}
}
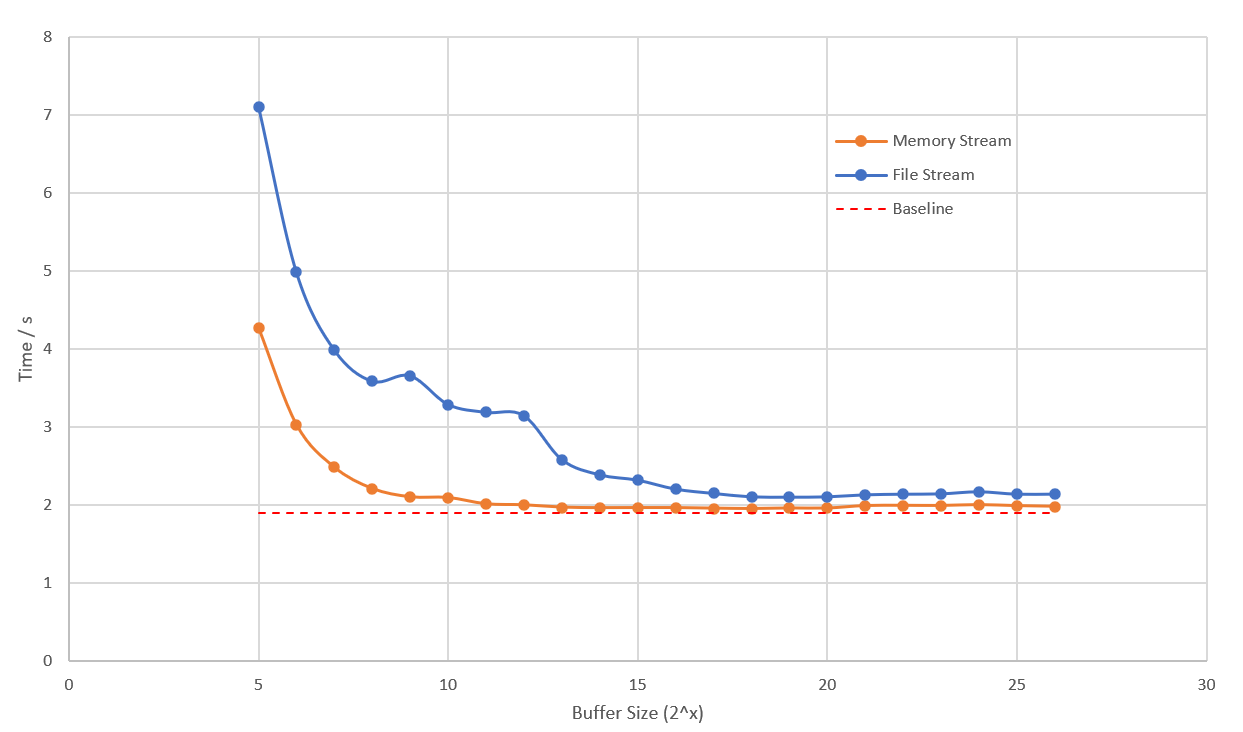
基准测试是那条红色虚线,是所有测试结果中最快的。橙色的曲线是 MemoryStream 的测试结果,在缓存块的 2KB 处降到了一个较低的位置,后续耗时无明显下降。这证明 .NET 源码中使用 4KB 大小的块是一个合理的选择,但是它没有考虑文件 IO 的延迟影响。蓝色的曲线是最接*显示的测试结果,缓存块大于 32KB 时的测试结果才接*于*稳。
总结一下,MD5.HashDataAsync 过慢的原因是文件 IO 影响到了计算速度。使用文件流进行 MD5 校验的时候,缓冲区至少需要 64KB,总体速度才不会被文件 IO 拖后腿。
不同大小的缓冲区对 MD5 计算速度的影响的更多相关文章
- Java中比较不同的MD5计算方式
在项目中经常需要使用计算文件的md5,用作一些用途,md5计算算法,通常在网络上查询时,一般给的算法是读取整个文件的字节流,然后计算文件的md5,这种方式当文件较大,且有很大并发量时,则可能导致内存打 ...
- iOS BCD码、数据流、字节和MD5计算
一.各个之间的相互转换 1.字符串转数据流NSData NSString *str = @"abc123"; NSData *dd = [str dataUsingEncoding ...
- php UTF8 转字节数组,后使用 MD5 计算摘要
Hex.encodeHexString(md5.digest);按 UTF8 转字节数组,后使用 MD5 计算摘要,得到 16 字节数组,使用 Hex 转为长度为 32 的字符串,保持小写 bin2h ...
- 大文本 通过 hadoop spark map reduce 获取 特征列 的 属性值 计算速度
大文本 通过 hadoop spark map reduce 获取 特征列 的 属性值 计算速度
- 一行代码加快pandas计算速度
一行代码加快pandas计算速度 DASK https://blog.csdn.net/sinat_38682860/article/details/84844964 https://cloud.te ...
- Tensorflow使用训练好的模型进行测试,发现计算速度越来越慢
实验时要对多个NN模型进行对比,依次加载直到第8个模型时,发现运行速度明显变慢而且电脑开始卡顿,查看内存占用90+%. 原因:使用过的NN模型还会保存在内存,继续加载一方面使新模型加载特别特别慢,另一 ...
- Cocos Creator 热更新文件MD5计算和需要注意的问题
Creator的热更新使用jsb.热更新基本按照 http://docs.cocos.com/creator/manual/zh/advanced-topics/hot-update.html?h=% ...
- (一)tensorflow-gpu2.0学习笔记之开篇(cpu和gpu计算速度比较)
摘要: 1.以动态图形式计算一个简单的加法 2.cpu和gpu计算力比较(包括如何指定cpu和gpu) 3.关于gpu版本的tensorflow安装问题,可以参考另一篇博文:https://www.c ...
- hashlib的md5计算
hashlib的md5计算 hashlib概述 涉及加密服务:Cryptographic Services 其中 hashlib是涉及 安全散列 和 消息摘要 ,提供多个不同的加密算法借口,如SHA1 ...
- .NET 的 Debug 和 Release build 对执行速度的影响
这篇文章发布于我的 github 博客:原文 在真正开始讨论之前先定义一下 Scope. 本文讨论的范围限于执行速度,内存占用什么的不在评估的范围之内. 本文不讨论算法:编译器带来的优化基本上属于底层 ...
随机推荐
- 权限RBAC、RBAC0 、RBAC1、RBAC2
https://zhuanlan.zhihu.com/p/34608415 权限系统的基本构成 权限系统主要由三个要素构成:帐号,角色,权限. 帐号是登录系统的唯一身份识别,一个账号代表一个用户.由自 ...
- 快收藏!最全GO语言实现设计模式
https://segmentfault.com/a/1190000042859564
- ACM-刷题记录-14届NEFU校赛
P2031凯撒密码 #include<bits/stdc++.h> using namespace std; int main(){ string s; int d; while(cin& ...
- 中心极限定理的模拟—R实现
中心极限定理,是指概率论中讨论随机变量序列部分和分布渐近于正态分布的一类定理.这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量近似服从正态分布的条件.它是概率论中最重要的一类定理,有广泛的 ...
- [软件设计&系统建模] Web软件通用能力模块
0 基础工具 1 日志 2 权限 3 文件处理(下载/上传) 4 对象池 对象池 数据库连接池 线程池 5 微服务 服务网关 配置中心 注册中心 服务调用 服务熔断 健康检测 Actuator 6 缓 ...
- python数据类型、变量以及编码和字符串、格式化
1.数据类型包括整型.浮点型.字符串.布尔型. 整数如果位数太多可以用_隔开,浮点数可以用科学记数法表示,字符串要用单引号或者双引号括起来,布尔型的值只能为True和False 2.变量可以由数字.字 ...
- ViewGroup的TouchTarget设计思维
TouchTarget需要创建的时候先看下池子里面有没有被回收上来的,如果没有可以利用的就给你创建一个新的,否则就从池子里面把头部的那个可以利用的给你,你把你的东西放进去就行了.回收的时候就是把你放在 ...
- 【SpringMVC】(一)
SpringMVC简介 SpringMVC是Spring的一个后续产品,是Spring的一个子项目 基于原生的Servlet,通过了功能强大的DispatcherServlet,对请求和响应进行统一处 ...
- 如何确定 this 指向?改变 this 指向的方式有哪些?
this 指向: 1. 全局上下文(函数外) 无论是否为严格模式,均指向全局对象.注意:严格模式下全局对象为undifined 2. 函数上下文(函数内) 默认的,指向函数的调用对象,且是最直接的调用 ...
- GraalVM(云原生时代的Java)和IoT在边缘侧落地与实践
环顾四周,皆是对手! 云时代的掉队者,由于Java启动的高延时.对资源的高占用.导致在Serverless及FaaS架构下力不从心,在越来越流行的边缘计算.IoT方向上也是难觅踪影; Java语言在业 ...