class-决策树Decision Tree
1.1 决策树概念
1.2 决策树与if-then规则
1.3 决策树与条件概率分布
1.4 Training the decision tree
2 特征选择
2.1 概述
2.2 信息增益(Information Gain)
2.3 信息增益比
3 决策树生成
3.1 ID3算法
3.2 C4.5算法
4 决策树剪枝decision tree pruning
5 CART算法
5.1 CART生成
5.2 CART剪枝
1 决策树model与training
1.1 决策树概念
定义:分类决策树模型描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。有两种结点:(internal) node,leaf node,内部结点表示一个特征和属性,叶子结点表示一个类。
过程:用决策树分类,从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到子结点,这时每一个子结点对应一个该特征的取值,如此递推对实例进行测试并分配,直至到达叶子结点,最后将实例的类放到叶子结点中。
1.2 决策树与if-then规则
决策树由根结点到叶子结点的每一条路径构建一条规则;路径上内部结点的特征对应规则的条件,叶子结点对应规则的结论。if-then规则具备的特点是:互斥且完备。即每一个实例都被一条路径或一条规则所覆盖,而且只被一条路径或一条规则所覆盖(实例满足的规则条件)。
1.3 决策树与条件概率分布
可以表示为特定条件下类的条件概率分布,其定义在特征空间的一个划分(partition)上,将特征空间划分为互不相交的单元(cell)或区域(region),并在每个单元上定义一个类的概率分布就构成了条件概率分布。表示为P(Y|X),放入概率大的叶子结点上,即决策树分类时将该结点的实例强行分到条件概率大的那一类去。
具体过程可以解释为:对于某一不知类别的实例x,从根节点输入,然后判断x的第一维满足的条件,当找到满足条件的node单元后,在将第二维数据判断下一个条件,然后再分node,直到分到最后一个维度的数据规则,然后下一结点为leaf node。
1.4 Training the decision tree
这里主要是文字的讲解。
训练目标:损失函数(通常是正则化的极大似然函数),学习的策略就是将目标函数最小化。训练的model应该是与训练数据矛盾较小,尽管基于特征空间划分的类的条件概率model有多个,应该选择对训练集有很好的拟合度,并且也能对未知数据有很好的预测。
学习算法:递归的选择最优特征,根据特征对训练数据进行分割,使得对各个子数据集有一个最好的分类过程——对应特征空间的划分和决策树的构建。首先,构建根节点,将所有的训练数据都放在根节点。然后,选择最优的特征,基于此将训练数据集分割,使得各个子集在当前条件下最好的分类。最后,如果这些子集被正确分类,那么构建叶子结点,将这些子集对应到叶子结点中去;若还有子集不能正确分类那么对这些子集选择最优特征,继续分割,构建相应的结点,直到所有训练数据集被正确分类或者没有合适的特征为止,最后每个子集都分到叶子结点上,就有了明确的类。——这就生成了decision tree。
————此算法对训练集可能有很好的分类能力,但是不一定对未知数据很好,可能会发生过拟合。解决方法是:树剪枝。
2 特征选择
2.1 概述
特征选择在于选取对训练数据具有分类能力的特征,这样可以提高决策树的学习(训练)效率。通常特征选择准则是信息增益或信息增益比。特征选择实质是决定用哪个特征来划分特征空间。
2.2 信息增益(Information Gain)
熵(entropy)是表示随机变量不确定性的度量。
定义:
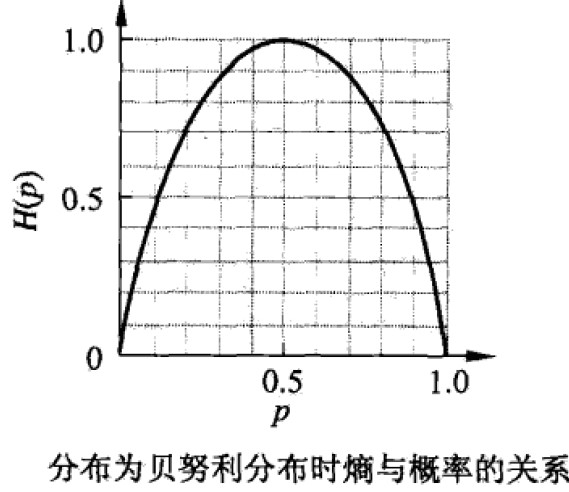
假设X是离散随机有限值变量概率分布为P(X=xi)=pi, i=1,2,…n;则随机变量X的熵为: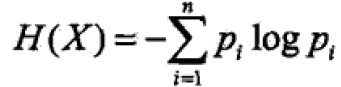 (定义0log0=0)以2为底的单位为比特bit,以e为底的自然对数单位为纳特nat,只与X的分布有关,与X本身无关。熵越大,随机变量不确定性越大即0<=H(p)<=logn
(定义0log0=0)以2为底的单位为比特bit,以e为底的自然对数单位为纳特nat,只与X的分布有关,与X本身无关。熵越大,随机变量不确定性越大即0<=H(p)<=logn
几种经典熵分布区曲线
条件熵(conditional entropy)H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性,定义为X给定条件下Y的条件概率分布的熵对X数学期望。pi=P(X=xi)
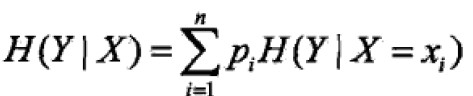
条件熵等定义和理解
http://blog.csdn.net/jxlijunhao/article/details/17690463
http://ccckmit.wikidot.com/st:mutualinformation
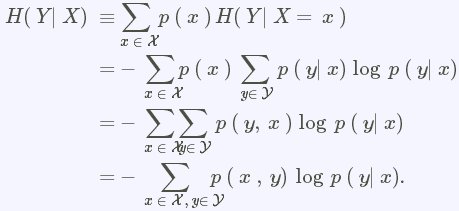
信息增益:得知特征X的信息而使得类Y的信息不确定性减少的程度。对于特征A对训练数据集D的信息增益为g(D,A),定义为D经验熵H(D)与特征A在给定条件下D的经验条件熵H(D|A)之差:g(D,A)=H(D)-H(D|A)
注:一般等号右边叫做互信息(mutual information),因此信息增益等价于训练集中类与特征的互信息。
选择方法:对训练集D计算其每个特征的信息增益,并比较他们的大小,选择信息增益最大的特征。

输入:训练集D和特征A
输出:特征A对训练集D的信息增益g(D,A).

2.3 信息增益比
信息增益是相对于训练集而言的,并无绝对意义。即在经验熵大的时候就变大, 反之变小。故提出信息增益比,定义为信息增益与训练集增益之比:
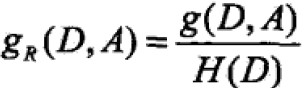
3 决策树生成
3.1 ID3算法
此算法的核心是在决策树各个结点上应用信息增益准则来选择特征,递归的构建决策树。具体流程是:从根结点(root node)开始,对结点计算所有可能的特征信息增益,选择信息增益最大的特征作为结点的特征,并由该特征不同取值建立子结点,再对子结点调用以上方法,构建决策树;直到所有特征的信息增益均很小,或者没有特征可以选择为止,最后得到一个决策树。ID3相当于用极大似然法进行概率模型的选择。


注:该算法产生的树容易过拟合。
3.2 C4.5算法
与ID3算法类似,但使用信息增益比来选择特征。只需将以上算法中的信息增益换成信息增益比即可。
4 决策树剪枝decision tree pruning
利用决策树生成算法递归的产生决策树,直到不能产生为止。此树对训练集分类十分准确,但对未知数据的测试分类容易发生过拟合。原因是在训练数据集学习的tree复杂度高,对训练集精确但是泛化能力变差,因此,对树进行修剪使其简化,叫做剪枝(将从已知树上剪去子树或叶子结点,并将其 根结点或者父结点作为新的叶子结点,从而简化分类树模型。)。
决策树剪枝常通过极小化决策树的loss/cost function来实现。
决策树学习的损失函数:其中树为T,叶结点个数|T|,t是T的叶结点,叶结点有Nt个样本点,其中k类样本点为Ntk个,Ht(T)为叶结点t上的经验熵,alpha为参数
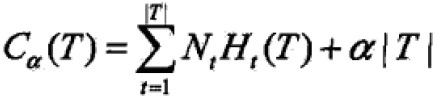
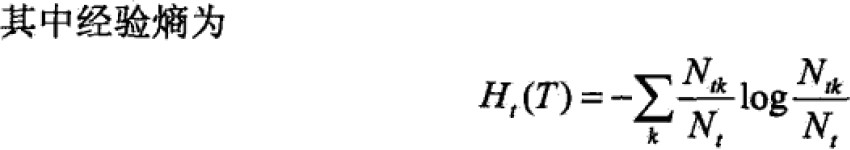
简化修改右端第一项:
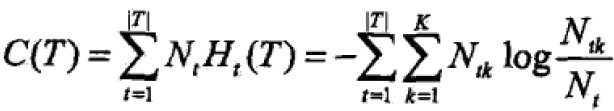
此时:
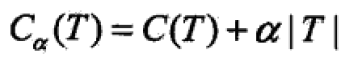
说明:C(T)表示model对训练集的预测误差,即model与训练数据的拟合程度。|T|表示model的复杂度,参数alpha控制二者之间的影响,较大的alpha促使选择简单的model,反之复杂model。alpha=0意味着只考虑 拟合程度不卡盘率复杂度。
剪枝就是alpha确定时,选择较小的loss function。当alpha确定,子树越大,与训练集拟合越好,但是复杂度越高,反之,子树越小,model的复杂度就越低,但是训练集的拟合就越差,这时误差函数就体现了二者的对抗和均衡。
另,损失函数的极小化等价于正则化的极大似然估计。
算法:


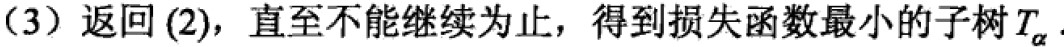
在算法不等式中,只考虑两个树的损失函数的差,其计算可在局部进行,所以决策树剪枝算法可以由一种动态规划算法实现。
5 CART算法
CART(classification and regression tree)分类决策回归树,是广泛的决策树训练(学习)算法——由特征选择,树生成,剪枝组成,既可以用于回归,也可以用于分类。CART是给定输入随机变量X条件下输出随机变量Y的条件概率分布的方法。假设决策树是二叉树,内部结点特征值取值为“是”和“否”。左分支是“是”,右分支是“否”。二叉树递归二分每个特征,将输入空间化为有限个单元,并在这些单元确定预测的概率分布,也就是在输入给定条件下输出的条件概率分布。主要是两步,生成尽可能大的树,然后剪枝选择最优子树,用损失函数作为标准。
5.1 CART生成
递归构建二叉树,对回归树用平方误差最小化准则,对分类树用基尼指数(Gini Index)最小化准则,进行特征选择,生成二叉树。
- 回归树的生成
假设X,Y分别为输入和输出变量,且Y是连续变量,给定训练集:D={(x1,y1),…,(xN,yN)};
一个回归树对应输入/特征空间的一个划分以及在划分单元上的输出值。假设将输入空间划分为M个单元R1,R2,RM,每个单元上固定值为cm,则回归树模型为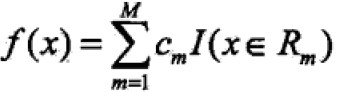 ;
;
当划分确定时,用平方误差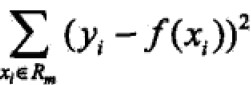 表示回归树对于训练数据的预测误差,用平方误差最小的准则求解每个单元上最优输出值。最优输出值是Rm上所有输入实例xi对应输出yi的均值,即
表示回归树对于训练数据的预测误差,用平方误差最小的准则求解每个单元上最优输出值。最优输出值是Rm上所有输入实例xi对应输出yi的均值,即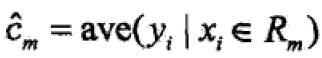 ;
;
如何对空间进行划分——启发式:选择第j个变量x(j)和取值s,作为切分变量(splitting variable)和切分点(splitting point)。并定义两个区域: ;
;
寻找最优变量和最优切分点: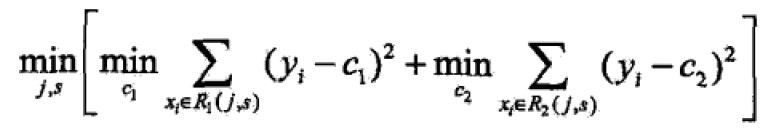 ;
;
对于固定的输入变量j可以找到最优切分点: ;
;
遍历所有输入变量找到最优切分变量和切分点(j,s)对,以此将输入空间分为两个区域,接着重复直到满足停止条件为止。
算法:

说明:此树为最小二乘回归树生成算法 - 分类树的生成
基尼指数定义:分类问题中,假设有K个类,样本点属于第k类的概率为pk,则概率分布的基尼指数为

对于binary class问题:如果第一类的概率为p,则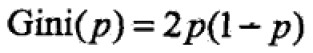 ;
;
给定样本集合D,则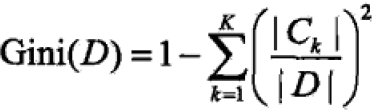 ;
;
集合D根据特征A是否取得某值a被分割成D1,D2两部分,即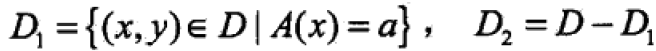
在A条件下,集合D的基尼指数为(相当于加权平均):
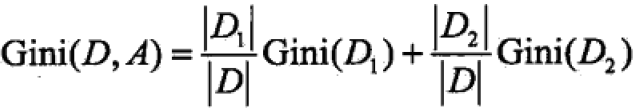
基尼指数表示集合D的不确定性,指数越大,样本集合的不确定性就越大,这一点与熵(具体是熵之半)类似,都可以表示分类误差概率。
算法:


算法的停止条件是结点中样本个数小于预定阈值,或样本基尼指数小于预定阈值,或没有更多的特征。
5.2 CART剪枝
CART对决策树底端剪去一些子树使得model变得简单能够对未知数据很好的预测。有两步:一是从决策树T0底端开始不断剪枝,直到T0的根节点,形成子树序列{T0,T1,…,Tn};然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从而选择最优子树。
- 剪枝形成子树序列
计算子树的损失函数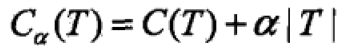 ;对于固定的alpha,一定唯一存在使得损失函数最小的子树T'(最优)。alpha大的时候,最优子树T‘偏小;alpha小的时候,最优子树T’偏大,alpha=0整棵树是最优的,alpha=infinit,根结点的单结点树是最优的。
;对于固定的alpha,一定唯一存在使得损失函数最小的子树T'(最优)。alpha大的时候,最优子树T‘偏小;alpha小的时候,最优子树T’偏大,alpha=0整棵树是最优的,alpha=infinit,根结点的单结点树是最优的。
可以使用递归的方法对树进行剪枝,将alpha从小到大递增,产生一系列小区间,对应最小损失函数的子树T'序列{T0,T1,…}.
具体:从整棵树T0开始剪枝,对T0内部任意结点t,对t单结点树的损失函数为: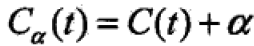
以t为根结点子树Tt损失函数是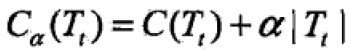 ;
;
当alpha充分小或者为0时,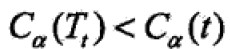 ;
;
在alpha递增过程中一定有一个这样的alpha: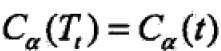 ;再继续增大时不等式反向;
;再继续增大时不等式反向;
因此,alpha值为: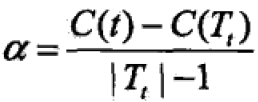 ,Tt与t有相同的损失函数值,且t的结点数目更少,因此t更可取,对Tt进行剪枝。
,Tt与t有相同的损失函数值,且t的结点数目更少,因此t更可取,对Tt进行剪枝。
同时对T0内每一个内部结点t计算损失函数减少程度:
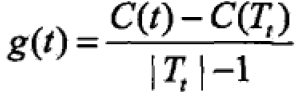
在T0中剪去最小的Tt,将得到子树T1,同时将最小的g(t)设为alpha1,T1为区间[alpha1,alpha2)的最优子树。一直剪枝下去直到根结点,在这一过程中不断增加alpha值产生新的区间。 - 在子树序列T0,T1,…,Tn中通过交叉验证选取最优的子树Talpha
利用独立的验证数据集测试子树序列中各棵子树的平方误差或者基尼指数,其最小的决策树被认为是最优的决策树。每一棵子树都对应一个参数alpha,最优子树Tk确定,alphak也就确定了,即最优子树Talpha。
剪枝算法:

不好理解的地方可以阅读博客或者搜索其他文章
class-决策树Decision Tree的更多相关文章
- 机器学习算法实践:决策树 (Decision Tree)(转载)
前言 最近打算系统学习下机器学习的基础算法,避免眼高手低,决定把常用的机器学习基础算法都实现一遍以便加深印象.本文为这系列博客的第一篇,关于决策树(Decision Tree)的算法实现,文中我将对决 ...
- 数据挖掘 决策树 Decision tree
数据挖掘-决策树 Decision tree 目录 数据挖掘-决策树 Decision tree 1. 决策树概述 1.1 决策树介绍 1.1.1 决策树定义 1.1.2 本质 1.1.3 决策树的组 ...
- 决策树Decision Tree 及实现
Decision Tree 及实现 标签: 决策树熵信息增益分类有监督 2014-03-17 12:12 15010人阅读 评论(41) 收藏 举报 分类: Data Mining(25) Pyt ...
- 用于分类的决策树(Decision Tree)-ID3 C4.5
决策树(Decision Tree)是一种基本的分类与回归方法(ID3.C4.5和基于 Gini 的 CART 可用于分类,CART还可用于回归).决策树在分类过程中,表示的是基于特征对实例进行划分, ...
- (ZT)算法杂货铺——分类算法之决策树(Decision tree)
https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1.摘要 在前面两篇文章中,分别介绍和讨论了朴素贝叶斯分 ...
- 决策树decision tree原理介绍_python sklearn建模_乳腺癌细胞分类器(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 机器学习方法(四):决策树Decision Tree原理与实现技巧
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术.应用感兴趣的同学加入. 前面三篇写了线性回归,lass ...
- 机器学习-决策树 Decision Tree
咱们正式进入了机器学习的模型的部分,虽然现在最火的的机器学习方面的库是Tensorflow, 但是这里还是先简单介绍一下另一个数据处理方面很火的库叫做sklearn.其实咱们在前面已经介绍了一点点sk ...
- 决策树 Decision Tree
决策树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布.树的最顶层是根结点.  决策树的构建 想要构建一个决策树,那么咱们 ...
- 【机器学习算法-python实现】决策树-Decision tree(2) 决策树的实现
(转载请注明出处:http://blog.csdn.net/buptgshengod) 1.背景 接着上一节说,没看到请先看一下上一节关于数据集的划分数据集划分.如今我们得到了每一个特征值得 ...
随机推荐
- JDBC(二)
三层架构的一些基本报结构如下: domain包:下面是一些实体bean,属性为private,提供属性相对应的set和get方法.一般对应于数据库中的一张数据表,属性对应于数据表中的列. dao包,数 ...
- JDBC学习笔记(四)
减少各个Dao类间的重复代码,有以下几种方式: 写一个DBConnectionManager,将公共的查询逻辑做成方法,将sql语句作为参数传递给方法. public class DBConnecti ...
- CF798E. Mike and code of a permutation [拓扑排序 线段树]
CF798E. Mike and code of a permutation 题意: 排列p,编码了一个序列a.对于每个i,找到第一个\(p_j > p_i\)并且未被标记的j,标记这个j并\( ...
- Java随感
创新项目要用java,而我只大概会C++,只能靠自学咯~~~随时将一些重要的概念做笔记在这里吧>_< 1.一个源文件中只能有一个public类,一个源文件可以有多个非public类 2.所 ...
- Vue中,父组件向子组件传值
1:在src/components/child/文件夹下,创建一个名为:child.vue的子组件 2:在父组件中,设置好需要传递的数据 3:在App.vue中引入并注册子组件 4:通过v-bind属 ...
- iis发布网站问题-由于权限不足而无法读取配置文件,无法访问请求的页面
错误一: HTTP Error 500.19 - Internal Server Error 配置错误: 不能在此路径中使用此配置节.如果在父级别上锁定了该节,便会出现这种情况.锁定是默认设置的 (o ...
- Quartz.NET 3.0 正式发布
Quartz.NET是一个强大.开源.轻量的作业调度框架,你能够用它来为执行一个作业而创建简单的或复杂的作业调度.它有很多特征,如:数据库支持,集群,插件,支持cron-like表达式等等.在2017 ...
- [转]【C#】分享一个弹出浮动层,像右键菜单那样召即来挥则去
适用于:.net2.0+ Winform项目 背景: 有时候我们需要开一个简单的窗口来做一些事,例如输入一些东西.点选一个item之类的,可能像这样: 完了返回原窗体并获取刚刚的输入,这样做并没有什么 ...
- Yii2 Ajax Post 实例及常见错误修正
先贴下我的代码: signup.js$('.reg_verify_pic').click(function(){ var csrfToken = $('meta[name="_csrf-To ...
- markdown学习经验
文章首发于我的github博客 前言 markdown是一种简洁有力的文本编辑语言.由于它十分好用,我将所有的博客都换成了markdown编辑器. 学习方法 工具为先,从工具中学习,熟能生巧. 工具选 ...