爬虫学习--MOOC爬取豆瓣top250
scrapy框架
scrapy是一套基于Twisted的异步处理框架,是纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松实现一个爬虫,用来抓取网页内容或者各种图片。
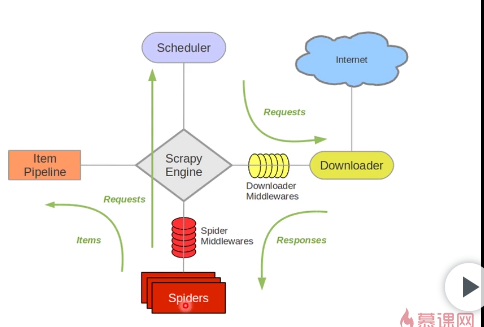
scrapy Engine:scrapy引擎
负责调度器,下载器,管道和爬虫之间的通讯信号和数据的传递,相当于交通站
Scheduler:调度器 简单来说就是一个队列,负责接受引擎发来的request请求,然后将请求排队,当引擎需要请求数据的时候,就将请求队列中的数据交给引擎。
Downloader:下载器
下载引擎发送过来的所有request请求,并将获得的response交还给引擎,再由引擎将response交还给Spider解析。
Item Pipeline:管道
管道组件,封装去重类,存储类的地方,负责处理spider中获取的数据,并进行后期处理。
Spiders:爬虫
spider是爬虫组件,Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。负责处理所有的response。
两个中间件:Downloader Minddlewares 下载中间件
封装代理,或者http头,隐藏我们自己的地方。下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response(也包括引擎传递给下载器的Request)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
一句话总结就是:处理下载请求部分
Spider Middlewares Spider中间件
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
一句话总结就是:处理解析部分
进入代码过程部分:
第一步
使用命令行进入你想要创建爬虫项目的目录键入命令:
scrapy startproject testdada
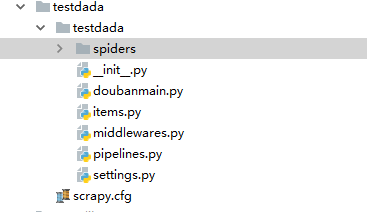

即会出现这样的目录。
第二步
进入spiders的这个目录
scrapy genspiders douban "movie.douban.com"
即创建了spiders下面出现这个douban.py要爬去的一些代码基本就写在里面

第三步
设置settings.py
加入这一句:
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'
为什么要设置user-agent:有些网站不想被爬虫访问,所以会检测连接对象,这个可以模拟浏览器访问,防止被网站发现是爬虫程序。
第四步
编写代码
编写items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class TestdadaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序号
serial_number = scrapy.Field()
# 电影的名称
movie_name = scrapy.Field()
# 电影的介绍
introduce = scrapy.Field()
# 星级
star = scrapy.Field()
# 电影的评论数
evaluate = scrapy.Field()
# 电影的描述
describe = scrapy.Field()
就是一些想要查询的一些信息
douban.py的编写
# -*- coding: utf-8 -*-
import scrapy
from ..items import TestdadaItem class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/top250']
#默认解析方法
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']//li")
for item in movie_list:
movieitem = TestdadaItem()
movieitem['serial_number'] = item.xpath(".//div[@class='item']//div[@class='pic']//em//text()").extract_first()
movieitem['movie_name']=item.xpath(".//div[@class='info']//div[@class='hd']//a//span[1]//text()").extract_first()
#movieitem['introduce']=item.xpath(".//div[@class='bd']//p[1]/text()").extract_first()
content=item.xpath(".//div[@class='bd']//p[1]/text()").extract()
#遇到多行数据就进行处理
for i_content in content:
content_s="".join(i_content.split())
movieitem['introduce']=content_s
movieitem['star']=item.xpath(".//span[@class='rating_num']/text()").extract_first()
movieitem['evaluate']=item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
movieitem['describe']=item.xpath(".//p[@class='quote']//span[1]/text()").extract_first()
#yield到管道里面去
#解析下一页,获得下一页的url,xpath获得
yield movieitem
next_link=response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link=next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
关于这个包的导入当时遇到了一点问题,解决了,参考的是下方网址:
https://blog.csdn.net/Haihao_micro/article/details/78529370
就是from ..items import TestdadaItem 这句
可以在命令行输:
scrapy crawl douban
来查看爬虫的运行,还可以创建一个doubanmain.py来可以直接在pycharm运行,内容如下:
doubanmain.py
from scrapy import cmdline
cmdline.execute('scrapy crawl douban'.split())
于是直接运行doubanmain.py就行了。
于是爬取到了,豆瓣评分前250的电影,这是最后一个,爬取到的都是unicode字符串
运行结果:
https://movie.douban.com/top250?start=225&filter=>
{'describe': u'\u73b0\u4ee3\u79d1\u5e7b\u7535\u5f71\u7684\u5f00\u5c71\u4e4b\u4f5c\uff0c\u6700\u4f1f\u5927\u5bfc\u6f14\u7684\u6700\u4f1f\u5927\u5f71\u7247\u3002',
'evaluate': u'102672\u4eba\u8bc4\u4ef7',
'introduce': u'1968/\u82f1\u56fd\u7f8e\u56fd/\u79d1\u5e7b\u60ca\u609a\u5192\u9669',
'movie_name': u'2001\u592a\u7a7a\u6f2b\u6e38',
'serial_number': u'',
'star': u'8.7'}
第五步
将数据导出为json或者csv
然后可以在命令行将爬取到的数据转换为json或者csv文件。
douban的意思是douban.py这个的文件名
scrapy crawl douban -o test.json
同理,把json换成csv就会导出csv文件了。
我得到的csv文件: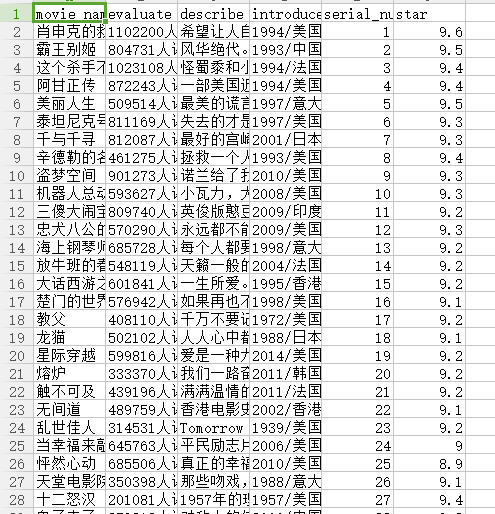
第六步
存到数据库
把csv文件存入mongdb数据库
pipelines.py的编写
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from .settings import mongo_host,mongo_port,mongo_db_name,mongo_db_collection
class TestdadaPipeline(object):
def __init__(self):
host=mongo_host
port=mongo_port
dbname=mongo_db_name
sheetname=mongo_db_collection
client=pymongo.MongoClient(host=host,port=port)
mydb=client[dbname]#database
self.post=mydb[sheetname]#集合名
def process_item(self, item, spider):
data =dict(item)
self.post.insert(data)
return item
写完代码还不算完,一定一定要在settings.py加入:
ITEM_PIPELINES = {
'testdada.pipelines.TestdadaPipeline': 300,
}
否则根本不会运行这一段的代码。不会执行存数据库的操作。
好的,看看我们的mongodb数据库。
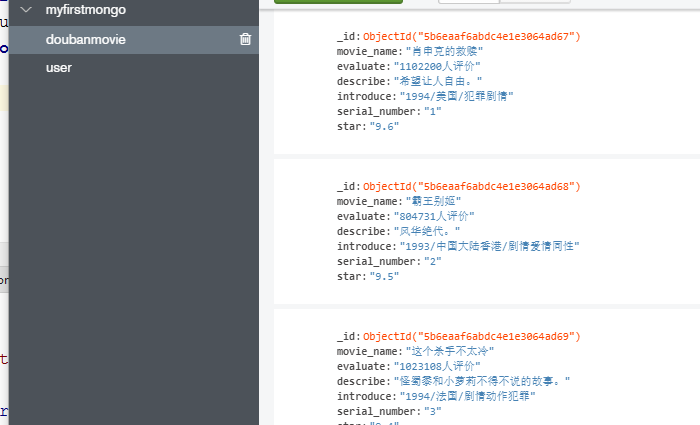
其他
ip代理中间件的编写:爬虫的伪装
因为如果不进行伪装的话,很有可能在爬取数据的时候被防火墙或者对方的安全设备发现使我们无法爬取到数据。
两种伪装方式:
1.设置代理ip
2.设置随机user-agent
通过设置request的meta属性来实现代理ip的使用。
class my_proxy(object):
def process_request(self,request,spider):
request.meta['proxy'] = 'http://your_proxy_ip:port'
#加个b,加密,因为base64只能加密base类型的数据
proxy_name_pass = b'username:password'
#加密
encode_pass_name=base64.b64encode(proxy_name_pass)
#注意这句的空格
request.headers['Proxy-Authorization']='Basic '+encode_pass_name.decode()
class my_useragent(object):
def process_request(self,request,spider):
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
agent=random.choice(USER_AGENT_LIST)
request.headers['User_Agent']=agent
别忘记了设置setting:
DOWNLOADER_MIDDLEWARES = {
#'testdada.middlewares.TestdadaDownloaderMiddleware': 543,
'testdada.middlewares.my_proxy': 543,
'testdada.middlewares.my_useragent' : 543,
}
注意事项:
中间件定义完一定要在settings中启用
爬虫文件名和爬虫名称不能相同,spider目录内不能存爱相同爬虫名称的项目文件。
over!
爬虫学习--MOOC爬取豆瓣top250的更多相关文章
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python爬虫+正则表达式实例爬取豆瓣Top250的图片
直接上全部代码 新手上路代码风格可能不太好 import requests import re from fake_useragent import UserAgent #### 用来伪造爬头部信息 ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- 2019-02-01 Python爬虫爬取豆瓣Top250
这几天学了一点爬虫后写了个爬取电影top250的代码,分别用requests库和urllib库,想看看自己能不能搞出个啥东西,虽然很简单但还是小开心. import requests import r ...
- Python 爬取豆瓣TOP250实战
学习爬虫之路,必经的一个小项目就是爬取豆瓣的TOP250了,首先我们进入TOP250的界面看看. 可以看到每部电影都有比较全面的简介.其中包括电影名.导演.评分等. 接下来,我们就爬取这些数据,并将这 ...
- Python-爬虫实战 简单爬取豆瓣top250电影保存到本地
爬虫原理 发送数据 获取数据 解析数据 保存数据 requests请求库 res = requests.get(url="目标网站地址") 获取二进制流方法:res.content ...
- python3爬取豆瓣top250电影
需求:爬取豆瓣电影top250的排名.电影名称.评分.评论人数和一句话影评 环境:python3.6.5 准备工作: 豆瓣电影top250(第1页)网址:https://movie.douban.co ...
随机推荐
- HP880G3 安装RHEL6.5
###关于读不到网卡驱动的问题 HP 880G3 在安装系统的时候会提示acpi错误 需要按F9 选择 lency开头走U盘安装系统 进入安装界面按tab 输入 acpi=off 这样就可以安装了 ...
- js-语法
js中slice方法(转) 1.String.slice(start,end)returns a string containing a slice, or substring, of string. ...
- 发现一个非常有趣好用的git博主,收录热门OC、swift项目三方架构
日常学习: https://github.com/iOShuyang/Book-Recommend-Github
- NPOI 导出Excel部分
) { MessageBox.Show("没有找到相关的数据!", "系统提示", MessageBoxButtons.OK, MessageBoxIcon.I ...
- win nginx + php bat启动/停止脚本
启动脚本 @echo offREM Windows 下无效REM set PHP_FCGI_CHILDREN=5 REM 每个进程处理的最大请求数,或设置为 Windows 环境变量set PHP_F ...
- Android 开发 倒计时功能 转载
原文地址:https://www.cnblogs.com/xch-yang/p/7920419.html Android为我们封装好了一个抽象类CountDownTimer,可以实现计时器功能: /* ...
- 爬虫基础——HTTP基本原理
## 学习爬虫务必从了解请求网页的工作流程和网页的组成原理开始,不然直接去学爬虫操作像是请求库等等,大概率会知其然而不知其所以然(个人体会) URL和HTTP简介 URL(Uniform Resour ...
- command not found所有执行命令总是报找不到
输入 ll命令 提示: bash: ls: 未找到命令… 相似命令是: 'lz' 原因: 环境变量PATH被修改了 解决办法: 执行: export PATH=/bin:/usr/bin:$PATH ...
- mass
@python青岛qq群 1.爬取豆瓣,登录一次爬取后再循环就退出登录,抓不到了: 2.用requests.session试试,只要session对象不释放,就能记住登录状态的cookie: 3.se ...
- vue缓存页面之后的生命周期
一:<router-view :key="key"></router-view> 没有作缓存时的状态 created :某单页面刚刚创建时候的回掉函数. m ...