Hadoop Partition函数应用(归档)
一、实例描述
在这个实例里我们使用简单的数据集,里面包含多条数据,每条数据由姓名、年龄、性别和成绩组成。实例要求是按照如下规则归档用户。
1.找出年龄小于20岁中男生和女生的最大分数
2.找出20岁到50岁男生和女生的最大分数
3.找出50岁以上的男生和女生的最大分数
样例输入:
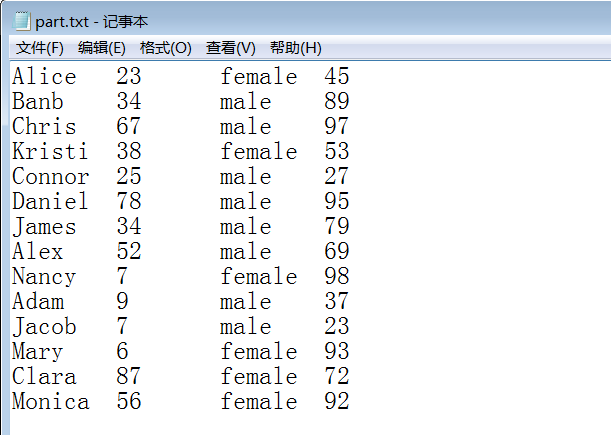
样例输出:
1.年龄小于20岁中男生和女生的最大分数
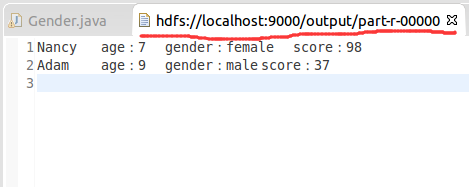
2.20岁到50岁男生和女生的最大分数

3.50岁以上的男生和女生的最大分数
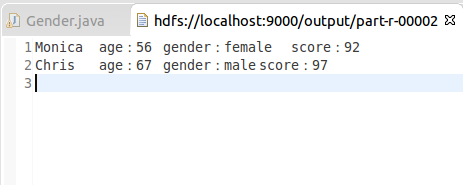
二、设计思路
基于实例需求,我们通过以下几步完成:第一步,编写Mapper类,按需求将数据集解析为key=gender,value=name+age+score,然后输出。第二步,编写Partitioner类,按年龄段,将结果指定给不同的Reduce执行。第三步,编写Reduce类,分别统计出男女学生的最高分。
这里简单介绍一下Partition的概念和使用:
得到map产生的记录后,他们该分配给哪些reducer来处理呢?hadoop默认是根据散列值来派发,但是实际中,这并不能很高效或者按照我们要求的去执行任务。例如,经过partition处理后,一个节点的reducer分配到了20条记录,另一个却分配到了10W万条,试想,这种情况效率如何。又或者,我们想要处理后得到的文件按照一定的规律进行输出,假设有两个reducer,我们想要最终结果中part-00000中存储的是”h”开头的记录的结果,part-00001中存储其他开头的结果,这些默认的partitioner是做不到的。所以需要我们自己定制partition来选择reducer。自定义partitioner很简单,只要自定义一个类,并且继承Partitioner类,重写其getPartition方法就好了,在使用的时候通过调用Job的setPartitionerClass指定一下即可。
MapReduce基于key的全排序的原理:
如何使用mapreduce来做全排序?最简单的方法就是使用一个partition,因为一个partition对应一个reduce的task,然而reduce的输入本来就是对key有序的,所以很自然地就产生了一个全排序文件。但是这种方法在处理大型文件时效率极低,因为一台机器必须处理所有输出文件,从而完全丧失了mapreduce所提供的并行架构的优势。
如果是分多个partition呢,则只要确保partition是有序的就行了。首先创建一系列排好序的文件;其次,串联这些文件(类似于归并排序);最后得到一个全局有序的文件。比如有1000个1-10000的数据,跑10个ruduce任务,如果进行partition的时候,能够将在1-1000中数据的分配到第一个reduce中,1001-2000的数据分配到第二个reduce中,以此类推。即第n个reduce所分配到的数据全部大于第n-1个reduce中的数据。这样,每个reduce出来之后都是有序的了,我们只要concat所有的输出文件,变成一个大的文件,就都是有序的了。
这时候可能会有一个疑问,虽然各个reduce的数据是按照区间排列好的,但是每个reduce里面的数据是乱序的啊?当然不会,不要忘了排序是MapReduce的天然特性 — 在数据达到reducer之前,mapreduce框架已经对这些数据按key排序了。
但是这里又有另外一个问题,就是在定义每个partition的边界的时候,可能会导致每个partition上分配到的记录数相差很大,这样数据最多的partition就会拖慢整个系统。我们期望的是每个partition上分配的数据量基本相同,hadoop提供了采样器帮我们预估整个边界,以使数据的分配尽量平均。
在Hadoop中,patition我们可以用TotalOrderPartitioner替换默认的分区,然后将采样的结果传给他,就可以实现我们想要的分区。在采样时,可以使用hadoop的几种采样工具,如RandomSampler,InputSampler,IntervalSampler。
三、程序代码
程序代码如下:
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class Gender { private static String spiltChar = "\t"; // 字段分隔符 public static class GenderMapper extends Mapper<LongWritable, Text, Text, Text>{ // 调用map解析一行数据,该行的数据存储在value参数中,然后根据\t分隔符,解析出姓名,年龄,性别和成绩
@Override
protected void map(LongWritable key, Text value,Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.map(key, value, context);
String [] tokens = value.toString().split(spiltChar);
String gender = tokens[2];
String nameAgeScore = tokens[0]+spiltChar+tokens[1]+spiltChar+tokens[3];
// 输出 key=gender value=name+age+score
context.write(new Text(gender), new Text(nameAgeScore));
}
} // 合并 Mapper 输出结果
public static class GenderCombiner extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.reduce(arg0, arg1, arg2);
int maxScore = Integer.MIN_VALUE;
int score = 0;
String name = " ";
String age = " ";
for(Text val:values){
String [] valTokens = val.toString().split(spiltChar);
score = Integer.parseInt(valTokens[2]);
if(score>maxScore){
name = valTokens[0];
age = valTokens[1];
maxScore = score;
}
}
context.write(key, new Text(name + spiltChar + age + spiltChar + maxScore));
}
} // 根据age年龄段将map输出结果均匀分布在reduce 上
public static class GenderPartitioner extends Partitioner<Text, Text>{
@Override
public int getPartition(Text key, Text value, int numReduceTasks) {
String [] nameAgeScore = value.toString().split(spiltChar);
int age = Integer.parseInt(nameAgeScore[1]); // 默认指定分区0
if (numReduceTasks == 0) {
return 0;
}
// 年龄小于等于20,指定分区0
if (age <= 20) {
return 0;
}else if (age <= 50) { // 年龄大于20,小于等于50,指定分区1
return 1 % numReduceTasks;
}else { // 剩余年龄指定分区2
return 2 % numReduceTasks;
}
}
} // 统计出不同性别的最高分
public static class GenderReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.reduce(arg0, arg1, arg2);
int maxScore = Integer.MIN_VALUE;
int score = 0;
String name = " ";
String age = " ";
String gender = " "; // 根据key,迭代value集合,求出最高分
for(Text val:values){
String[] valTokens = val.toString().split(spiltChar);
score = Integer.parseInt(valTokens[2]);
if (score > maxScore) {
name = valTokens[0];
age = valTokens[1];
gender = key.toString();
maxScore = score;
}
}
context.write(new Text(name), new Text("age:" + age + spiltChar + "gender:" + gender + spiltChar + "score:" + maxScore));
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length!=2){
System.out.println("Usage:wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf,"Gender");
job.setJarByClass(Gender.class); job.setMapperClass(GenderMapper.class);
job.setReducerClass(GenderReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); job.setCombinerClass(GenderCombiner.class);
job.setPartitionerClass(GenderPartitioner.class);
job.setNumReduceTasks(3); // reduce个数设置为3 FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
} }
Hadoop Partition函数应用(归档)的更多相关文章
- 剑指Offer28 最小的K个数(Partition函数应用+大顶堆)
包含了Partition函数的多种用法 以及大顶堆操作 /*********************************************************************** ...
- 寻找序列中最小的第N个元素(partition函数实现)
Partition为分割算法,用于将一个序列a[n]分为三部分:a[n]中大于某一元素x的部分,等于x的部分和小于x的部分. Partition程序如下: long Partition (long a ...
- 快速排序 partition函数的所有版本比较
partition函数是快排的核心部分 它的目的就是将数组划分为<=pivot和>pivot两部分,或者是<pivot和>=pivot 其实现方法大体有两种,单向扫描版本和双向 ...
- Partition函数
快排中核心的方法应该算是Partition函数了,它的作用就是将整个数组分成小于基准值的左边,和大于基准值的右边. 普通的Partition函数是这样的: public static int part ...
- 字符串的partition函数
partition函数 str1='sdga2a34'aa=str1.partition('a') print(aa) """ ('sdg', 'a', '2a34') ...
- 快速排序中的partition函数的枢纽元选择,代码细节,以及其标准实现
很多笔试面试都喜欢考察快排,叫你手写一个也不是啥事.我很早之前就学了这个,对快速排序的过程是很清楚的.但是最近自己尝试手写,发现之前对算法的细节把握不够精准,很多地方甚至只是大脑中的一个映像,而没有理 ...
- [hadoop] map函数中使用FileSystem对象出现java.lang.NullPointerException的原因及解决办法
问题描述: 在hadoop中处理多个文件,其中每个文件一个map. 我使用的方法为生成一个文件,文件中包含所有要压缩的文件在HDFS上的完整路径.每个map 任务获得一个路径名作为输入. 在eclip ...
- find_if函数与partition函数的转换
编写程序,求大于等于一个给定长度的单词有多少.我们还会修改输出,使程序只打印大于等于给定长度的单词. 使用find_if实现的代码如下: #include<algorithm> #incl ...
- 快速排序的Partition函数
1 //数组中两个数的交换 2 static void swap(int[] nums, int pos1, int pos2){ 3 int temp = nums[pos1]; 4 nums[po ...
随机推荐
- [leetcode]272. Closest Binary Search Tree Value II二叉搜索树中最近的值2
Given a non-empty binary search tree and a target value, find k values in the BST that are closest t ...
- java_30对文件的操作
1.导包 导commons-io-2.4.jar包 2. public class Demo1Commons { public static void main(String[] args) { fu ...
- MAC配置VIM环境
Ruby开发环境配置 ~/.vimrc set nocompatible " be iMproved, required filetype off " required set r ...
- gitlab 误关闭sign-in
sudo gitlab-rails console ApplicationSetting.last.update_attributes(password_authentication_enabled_ ...
- mysql学习--1.事务
转载自孤傲苍狼的博客:http://www.cnblogs.com/xdp-gacl/p/3984001.html 四.事务的四大特性(ACID) 4.1.原子性(Atomicity) 原子性是指事务 ...
- LINUX中printf与echo的区别
(1)首先echo是回显,即代表回车显示,是自带换行的:而printf只是打印出来,没有换行(2)echo只是回显没有变量替换功能:printf是有的举例:假如我们定义好变量a='hello worl ...
- MySQL解压包的安装教程
一.下载MySQL解压包 解压过的文件夹里面是没有 data 文件夹的. 二.创建文件 1.在根目录下创建 my.ini文件 内容如下: [mysqld] # 设置mysql的安装目录 basedir ...
- HTML页面使用layer弹出框输入数据
javascript中layer是一款近年来备受青睐的web弹层组件,layer.open对弹出框进行输入信息,并处理返回结果.详细介绍http://layer.layui.com/ 部署:将laye ...
- 20165213 Exp5 MSF基础应用
Exp5 MSF基础应用 实践内容 本实践目标是掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路.具体需要完成: 1.1一个主动攻击实践,如ms08_067; (1分) 1.2 一 ...
- shapefile添加字段 设置文件名为字段内容
转眼间,这一年又结束了,再记录一点知识吧 同事说他有好多shapefile,想给每个shapefile添加一字段,并设置该字段的内容为shapefile文件名,想着用arcpy实现,于是有了下面的代码 ...