《GPU高性能编程CUDA实战》第九章 原子性
▶ 本章介绍了原子操作,给出了基于原子操作的直方图计算的例子。
● 章节代码
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "D:\Code\CUDA\book\common\book.h" #define SIZE (100*1024*1024)
#define USE_SHARE_MEMORY true __global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo)
{
int i = threadIdx.x + blockIdx.x * blockDim.x; #if USE_SHARE_MEMORY
__shared__ unsigned int temp[];
temp[threadIdx.x] = ;
__syncthreads(); while (i < size)
{
atomicAdd(&temp[buffer[i]], );
i += blockDim.x * gridDim.x;
}
__syncthreads();
atomicAdd(&(histo[threadIdx.x]), temp[threadIdx.x]);
#else
while (i < size)
{
atomicAdd(&histo[buffer[i]], );
i += blockDim.x * gridDim.x;;
}
#endif
return;
} int main(void)
{
int i;
unsigned char *buffer = (unsigned char*)big_random_block(SIZE);// 内置的生成随机字符数组的函数 cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, ); unsigned char *dev_buffer;
unsigned int *dev_histo;
cudaMalloc((void**)&dev_buffer, SIZE);
cudaMemcpy(dev_buffer, buffer, SIZE, cudaMemcpyHostToDevice); cudaMalloc((void**)&dev_histo, * sizeof(int));
cudaMemset(dev_histo, , * sizeof(int)); cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, );
int blocks = prop.multiProcessorCount;// 书:实验表明使用MPS的两倍计算效率最高
histo_kernel << <blocks * , >> >(dev_buffer, SIZE, dev_histo); unsigned int histo[];
cudaMemcpy(histo, dev_histo, * sizeof(int), cudaMemcpyDeviceToHost); cudaEventRecord(stop, );
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
printf("Time to generate: %3.1f ms\n", elapsedTime); long histoCount = ;
for (i = ; i < ; i++)
histoCount += histo[i];
printf("Histogram Sum: %ld\n", histoCount); for (i = ; i < SIZE; i++)// 验证结果
histo[buffer[i]]--;
for (i = ; i < ; i++)
{
if (histo[i] != )
printf("Failure at hist[%d] == %d\n", i,histo[i]);
}
if (i == )
printf("\n\tSucceeded!\n"); cudaFree(dev_histo);
cudaFree(dev_buffer);
free(buffer);
cudaEventDestroy(start);
cudaEventDestroy(stop); getchar();
return ;
}
● 使用全局内存时,只要在每次线程尝试 +1 时使用原子加法即可;使用共享内存时算法分两步,线程先用原子加法往各线程块的共享内存中写入,同步以后,再用原子加法把各共享内存的结果往全局内存中写入。减缓了全局内存的写入冲突。
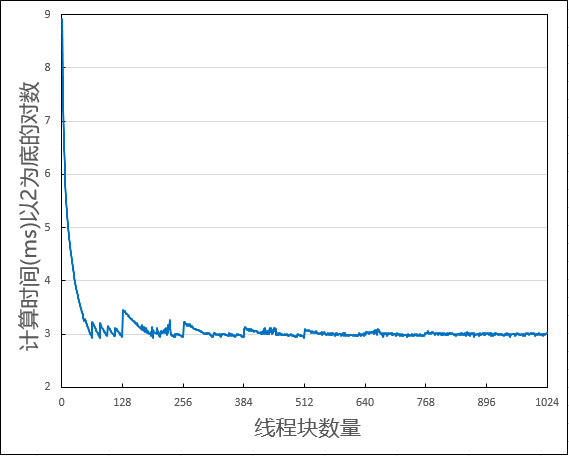
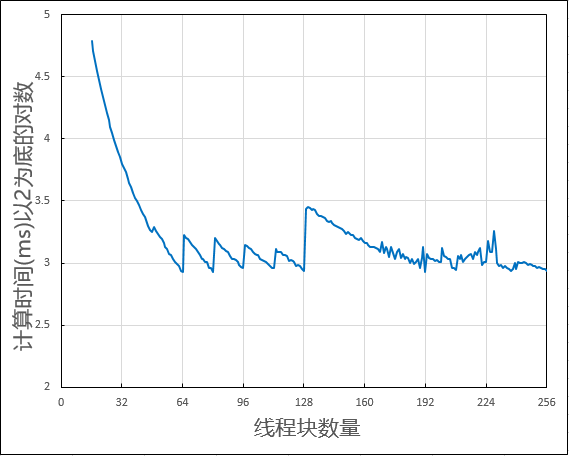
● 代码使用了两倍数量的MPS作为线程块数量,认为这样计算效率最高。在 GTX1070 上 prop.multiProcesser 为 16,程序默认使用 32 个线程块进行计算,我另用 1 到 256 个线程块依次测试,结果如下。
● big_random_block()定义于book.h中
void* big_random_block(int size)
{
unsigned char *data = (unsigned char*)malloc(size);
for (int i = ; i < size; i++)
data[i] = rand();
return data;
}
《GPU高性能编程CUDA实战》第九章 原子性的更多相关文章
- [问题解决]《GPU高性能编程CUDA实战》中第4章Julia实例“显示器驱动已停止响应,并且已恢复”问题的解决方法
以下问题的出现及解决都基于"WIN7+CUDA7.5". 问题描述:当我编译运行<GPU高性能编程CUDA实战>中第4章所给Julia实例代码时,出现了显示器闪动的现象 ...
- 《GPU高性能编程CUDA实战》第十一章 多GPU系统的CUDA C
▶ 本章介绍了多设备胸膛下的 CUDA 编程,以及一些特殊存储类型对计算速度的影响 ● 显存和零拷贝内存的拷贝与计算对比 #include <stdio.h> #include " ...
- 《GPU高性能编程CUDA实战》第五章 线程并行
▶ 本章介绍了线程并行,并给出四个例子.长向量加法.波纹效果.点积和显示位图. ● 长向量加法(线程块并行 + 线程并行) #include <stdio.h> #include &quo ...
- 《GPU高性能编程CUDA实战》第四章 简单的线程块并行
▶ 本章介绍了线程块并行,并给出两个例子:长向量加法和绘制julia集. ● 长向量加法,中规中矩的GPU加法,包含申请内存和显存,赋值,显存传入,计算,显存传出,处理结果,清理内存和显存.用到了 t ...
- 《GPU高性能编程CUDA实战》第七章 纹理内存
▶ 本章介绍了纹理内存的使用,并给出了热传导的两个个例子.分别使用了一维和二维纹理单元. ● 热传导(使用一维纹理) #include <stdio.h> #include "c ...
- 《GPU高性能编程CUDA实战》第六章 常量内存
▶ 本章介绍了常量内存的使用,并给光线追踪的一个例子.介绍了结构cudaEvent_t及其在计时方面的使用. ● 章节代码,大意是有SPHERES个球分布在原点附近,其球心坐标在每个坐标轴方向上分量绝 ...
- 《GPU高性能编程CUDA实战》第三章 CUDA设备相关
▶ 这章介绍了与CUDA设备相关的参数,并给出了了若干用于查询参数的函数. ● 代码(已合并) #include <stdio.h> #include "cuda_runtime ...
- 《GPU高性能编程CUDA实战中文》中第四章的julia实验
在整个过程中出现了各种问题,我先将我调试好的真个项目打包,提供下载. /* * Copyright 1993-2010 NVIDIA Corporation. All rights reserved. ...
- 《GPU高性能编程CUDA实战》附录二 散列表
▶ 使用CPU和GPU分别实现散列表 ● CPU方法 #include <stdio.h> #include <time.h> #include "cuda_runt ...
随机推荐
- Entities、pads、links 实体、垫、链接
Entities.pads.links 实体.垫.链接 Entities:1.实体由一个struct media_entity实例表示.结构通常嵌入到一个较高级别的结构,例如v4l2_subdev或v ...
- asp.net 导出excel的一种方法
项目用到的一种导出excel 的方法予以记录:(具体的业务类可更具情况替换使用) protected void Export(string filename, List<ComponentCon ...
- pow 的使用和常见问题
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/menxu_work/article/details/24540045 1.安装: $ curl ge ...
- 关于 Javascript 严格模式下多文件合并时注意
Javascript 在第一行使用 "use strict" 声明严格模式. 但是在多个 js 文件合并时就需要注意了,可能你的是严格模式,但别的文件不是,就会造成错误. 为什么使 ...
- JUC集合之 ArrayBlockingQueue
ArrayBlockingQueue介绍 ArrayBlockingQueue是数组实现的线程安全的有界的阻塞队列. 线程安全是指,ArrayBlockingQueue内部通过"互斥锁&qu ...
- 如何使用button在tab中新建打开一个链接页
在APPBOX某页中如何使用button按钮打开一个新的链接页.比如说百度.谷歌等 在后台的单击事件中使用以下语句即 string url = "DownloadIma ...
- Vue基础汇总实践
1)双向绑定: <div id="app"> <p>{{message}}</p> <input v-model=" ...
- hadoop零基础入门之DKH安装准备
前几天去参加了一个线下的聚会,参加聚会的基本都是从事互联网工作的.会上有人提到了区块链,从而引发了一场关于大数据方面的探讨.我也是从去年才正式接触大数据,一直在学习hadoop.相信接触过hadoop ...
- Django 配置总结
配置 app urls 项目下的urls.py from django.conf.urls import url,include urlpatterns = [ url(r'^BookApp/', i ...
- HttpClient连接池
HttpClient连接池,发现对于高并发的请求,效率提升很大.虽然知道是因为建立了长连接,导致请求效率提升,但是对于内部的原理还是不太清楚.后来在网上看到了HTTP协议的发展史,里面提到了一个属性C ...