第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
1、映射(mapping)介绍
映射:创建索引的时候,可以预先定义字段的类型以及相关属性
elasticsearch会根据json源数据的基础类型猜测你想要的字段映射,将输入的数据转换成可搜索的索引项,mapping就是我们自己定义的字段数据类型,同时告诉elasticsearch如何索引数据以及是否可以被搜索
作用:会让索引建立的更加细致和完善
类型:静态映射和动态映射
2、内置映射类型(也就是数据类型)
string类型:text,keyword两种
text类型:会进行分词,抽取词干,建立倒排索引
keyword类型:就是一个普通字符串,只能完全匹配才能搜索到
数字类型:long,integer,short,byte,double,float
日期类型:date
bool(布尔)类型:boolean
binary(二进制)类型:binary
复杂类型:object,nested
geo(地区)类型:geo-point,geo-shape
专业类型:ip,competion
3、属性介绍
store属性
index属性
null_value属性
analyzer属性
include_in_all属性
format属性

更多属性:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-boost.html
4、创建索引(相当于创建数据库)、创建表、创建字段-设置字段类型,添加数据
说明:
#创建索引(设置字段类型)
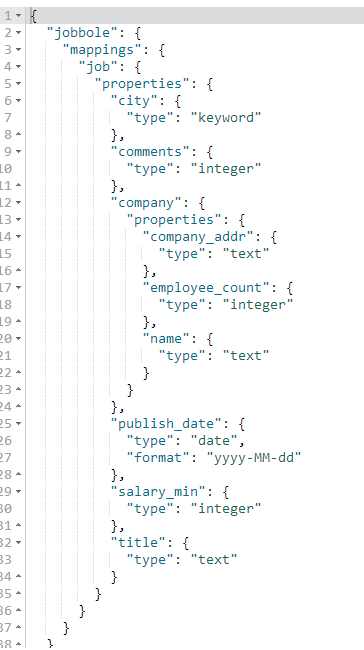
PUT jobbole #创建索引设置索引名称
{
"mappings": { #设置mappings映射字段类型
"job": { #表名称
"properties": { #设置字段类型
"title":{ #title字段
"type": "text" #text类型,text类型可以分词,建立倒排索引
},
"salary_min":{ #salary_min字段
"type": "integer" #integer数字类型
},
"city":{ #city字段
"type": "keyword" #keyword普通字符串类型
},
"company":{ #company字段,是嵌套字段
"properties":{ #设置嵌套字段类型
"name":{ #name字段
"type":"text" #text类型
},
"company_addr":{ #company_addr字段
"type":"text" #text类型
},
"employee_count":{ #employee_count字段
"type":"integer" #integer数字类型
}
}
},
"publish_date":{ #publish_date字段
"type": "date", #date时间类型
"format":"yyyy-MM-dd" #yyyy-MM-dd格式化时间样式
},
"comments":{ #comments字段
"type": "integer" #integer数字类型
}
}
}
}
} #保存文档(相当于数据库的写入数据)
PUT jobbole/job/1 #索引名称/表/id
{
"title":"python分布式爬虫开发", #字段名称:字段值
"salary_min":15000, #字段名称:字段值
"city":"北京", #字段名称:字段值
"company":{ #嵌套字段
"name":"百度", #字段名称:字段值
"company_addr":"北京市软件园", #字段名称:字段值
"employee_count":50 #字段名称:字段值
},
"publish_date":"2017-4-16", #字段名称:字段值
"comments":15 #字段名称:字段值
}
代码:
#创建索引(设置字段类型)
PUT jobbole
{
"mappings": {
"job": {
"properties": {
"title":{
"type": "text"
},
"salary_min":{
"type": "integer"
},
"city":{
"type": "keyword"
},
"company":{
"properties":{
"name":{
"type":"text"
},
"company_addr":{
"type":"text"
},
"employee_count":{
"type":"integer"
}
}
},
"publish_date":{
"type": "date",
"format":"yyyy-MM-dd"
},
"comments":{
"type": "integer"
}
}
}
}
} #保存文档(相当于数据库的写入数据)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园",
"employee_count":50
},
"publish_date":"2017-4-16",
"comments":15
}
5、获取索引下的mappings映射字段类型
#获取一个索引下的所有表的mappings映射字段类型
GET jobbole/_mapping
#获取一个索引下的指定表的mappings映射字段类型
GET jobbole/_mapping/job
【重点】在创建索引时一旦给字段设置了类型后就不可修改了,如果必须要修改就的重新创建索引,所以在创建索引时就必须确定好字段类型
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理的更多相关文章
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
随机推荐
- mongodb导出数据表命令之mongoexport
mongoexport导出文件格式支持csv和json,不同的是csv格式必须显示的指定要导出的字段,如: mongoexport -d rbac -c rbacs -o d:/web/rbac.cs ...
- lua -- handler
handler 将 Lua 对象及其方法包装为一个匿名函数. 格式: 函数 = handler(对象, 对象.方法) 在 quick-cocos2d-x 中,许多功能需要传入一个 Lua 函数做参数, ...
- VS注释与取消注释快捷键
最近在使用VS2010开发ASP.Net,突然发现想全部注释时找不到注释的快捷键,网上查了下,原来很简单,只是需要使用组合键. 注释: 先CTRL+K,然后CTRL+C 取消注释: 先C ...
- SVN文件加锁
原文:SVN与TortoiseSVN实战:文件加锁详解 加锁与解锁的操作对于项目中的二进制文件,如图片.声音.动态库等不可合并文件是非常有用的,可以让这些文件防止产生恼人的冲突,但TortoiseSV ...
- Asp.Net导出文件名中文乱码
Asp.Net导出word为例,Excel等其他文件也一样 protected void Page_Load(object sender, EventArgs e) {string html = “网 ...
- http协议格式
HTTP/1.0 报文类型有两种: 请求,响应. 请求类型 请求行(request-line): 请求类型+空格+url+\r\n. 请求头部(headers):0-n个键值对的集合. 空行(bla ...
- Linux中查看GNOME版本号
在使用图形终端时,可以在虚拟终端中直接输入gnome-about,会弹出如下窗口. 或者在纯命令行模式下使用下面命令: $ gnome-about --gnome-version 注:Gnome 3. ...
- Unique constraint on single String column with GreenDao2
转:http://software.techassistbox.com/unique-constraint-on-single-string-column-with-greendao_384521.h ...
- 【转】关于 SELECT /*!40001 SQL_NO_CACHE */ * FROM 的解惑
由于 在数据库做了缓存,在对数据库做了备份,然后在慢查询日志中发现了这一串字符: SELECT /*!40001 SQL_NO_CACHE */ * FROM 上网查了一下,发现好多答案,好多人说的都 ...
- C++中虚函数的作用是什么?它应该怎么用呢?
虚函数联系到多态,多态联系到继承.所以本文中都是在继承层次上做文章.没了继承,什么都没得谈. 下面是对C++的虚函数这玩意儿的理解. 一, 什么是虚函数(如果不知道虚函数为何物,但有急切的想知道,那你 ...