Spark SQL利器:cacheTable/uncacheTable【转】
转自:http://www.cnblogs.com/yurunmiao/p/4936583.html










Spark SQL利器:cacheTable/uncacheTable【转】的更多相关文章
- Spark SQL利器:cacheTable/uncacheTable
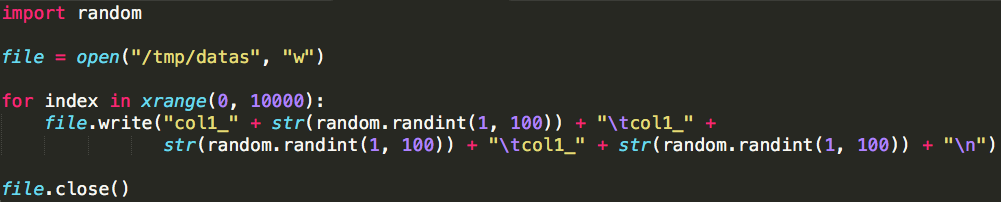
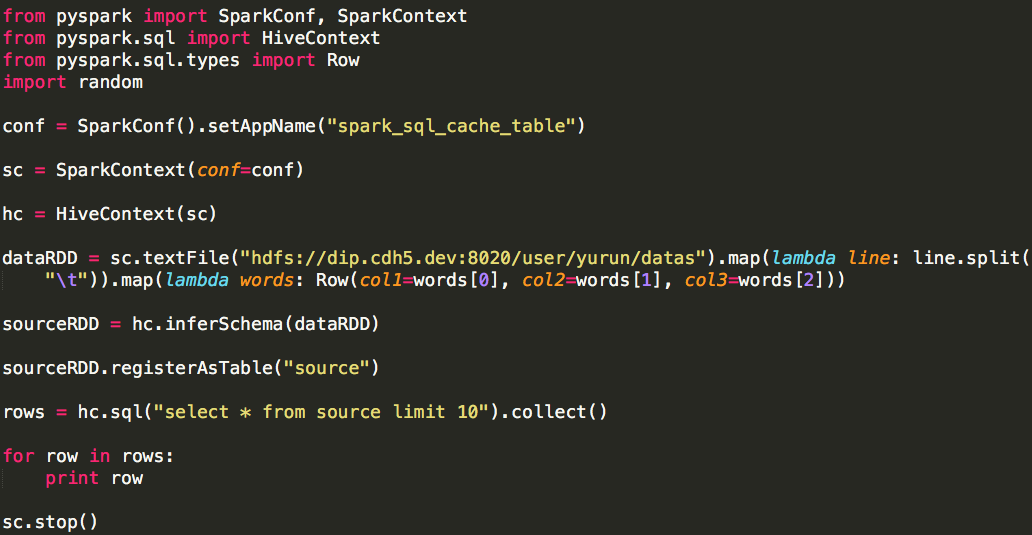
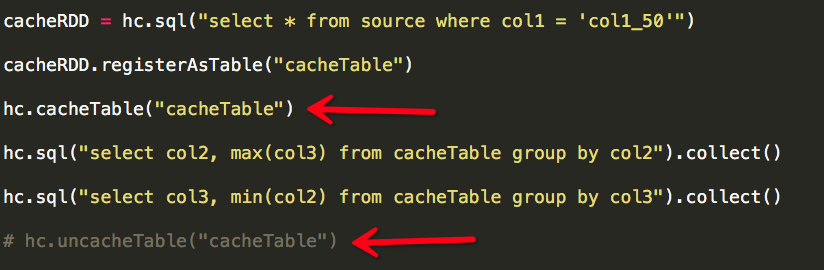
Spark相对于Hadoop MapReduce有一个很显著的特性就是“迭代计算”(作为一个MapReduce的忠实粉丝,能这样说,大家都懂了吧),这在我们的业务场景里真的是非常有用. 假设我们有 ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine 转载请注明出处:http://www.cnblogs.com/BYRans/ 缓 ...
- spark sql cache
1.几种缓存数据的方法 例如有一张hive表叫做activity 1.CACHE TABLE //缓存全表 sqlContext.sql("CACHE TABLE activity" ...
- Spark SQL 初步
已经Spark Submit 2013哪里有介绍Spark SQL.就在很多人都介绍Catalyst查询优化框架.经过一年的发展后,.今年Spark Submit 2014在.Databricks放弃 ...
- Spark SQL笔记——技术点汇总
目录 概述 原理 组成 执行流程 性能 API 应用程序模板 通用读写方法 RDD转为DataFrame Parquet文件数据源 JSON文件数据源 Hive数据源 数据库JDBC数据源 DataF ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
随机推荐
- ios中打包
第一步:这里需要注意,要选择真机,否则Archive 会是灰色的. 点击后,系统会自动编译一次,并跳转到如图界面: 第二步: 在你刚刚生成的程序上点击右键,并且点击Show in Finder. ...
- 理解sklearn.feature.text中的CountVectorizer和TfidfVectorizer
""" 理解sklearn中的CountVectorizer和TfidfVectorizer """ from collections im ...
- 【RS】Local Latent Space Models for Top- N Recommendation-利用局部隐含空间模型进行Top-N推荐
[论文标题]Local Latent Space Models for Top- N Recommendation (KDD-2018 ) [论文作者]—Evangelia Christakopou ...
- 【C++】不要想当然使用resize
#include <iostream> // std::cout #include <vector> // std::vector using namespace std; i ...
- nginx配置文件结构,语法,配置命令解释
摘要: nginx的配置文件类似于一门优雅的编程语言,弄懂了它的规范就可以自定义配置文件了,这个很重要~ 1,结构分析 nginx配置文件中主要包括六块:main,events,http,server ...
- jQuery 自定义网页滚动条样式插件 mCustomScrollbar 的介绍和使用方法(转)
系统默认的滚动条样式,真的已经看的够恶心了.试想一下,如果在一个很有特色和创意的网页中,出现了一根系统中默认的滚动条样式,会有多么的别扭. 为了自己定义网页中的滚动条的方法,我真的已经找了很久了,就目 ...
- centos 为OPENJDK配置JAVA_HOME环境变量,安装MAVEN
1.安装开发者工具包 yum install java--openjdk-devel -y 2.配置环境变量 vim /etc/profile export JAVA_HOME=/usr/lib/jv ...
- C++的std::string的“读时也拷贝”技术!
C++的std::string的读时也拷贝技术! 嘿嘿,你没有看错,我也没有写错,是读时也拷贝技术.什么?我的错,你之前听说写过时才拷贝,嗯,不错的确有这门技术,英文是Copy On Write,简写 ...
- VS2010安装msdn本地帮助
原文链接:http://www.2cto.com/kf/201210/162057.html 下面我们看看如何安装本地msdn技术帮助文档: 一.如何设置vs2010 按F1键时,打开的是本地文档(帮 ...
- RGB 常用颜色对照表
http://blog.csdn.net/xiaoting451292510/article/details/8226325