K Nearest Neighbor 算法
文章出处:http://coolshell.cn/articles/8052.html
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法。其中的K表示最接近自己的K个数据样本。KNN算法和K-Means算法不同的是,K-Means算法用来聚类,用来判断哪些东西是一个比较相近的类型,而KNN算法是用来做归类的,也就是说,有一个样本空间里的样本分成很几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。你可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
Wikipedia上的KNN词条中有一个比较经典的图如下:
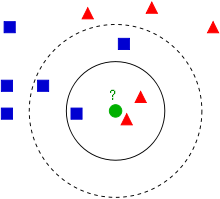
从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
- 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
- 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
我们可以看到,机器学习的本质——是基于一种数据统计的方法!那么,这个算法有什么用呢?我们来看几个示例。
产品质量判断
假设我们需要判断纸巾的品质好坏,纸巾的品质好坏可以抽像出两个向量,一个是“酸腐蚀的时间”,一个是“能承受的压强”。如果我们的样本空间如下:(所谓样本空间,又叫Training Data,也就是用于机器学习的数据)
|
向量X1 耐酸时间(秒) |
向量X2 圧强(公斤/平方米) |
品质Y |
|
7 |
7 |
坏 |
|
7 |
4 |
坏 |
|
3 |
4 |
好 |
|
1 |
4 |
好 |
那么,如果 X1 = 3 和 X2 = 7, 这个毛巾的品质是什么呢?这里就可以用到KNN算法来判断了。
假设K=3,K应该是一个奇数,这样可以保证不会有平票,下面是我们计算(3,7)到所有点的距离。(关于那些距离公式,可以参看K-Means算法中的距离公式)
|
向量X1 耐酸时间(秒) |
向量X2 圧强(公斤/平方米) |
计算到 (3, 7)的距离 |
向量Y |
|
7 |
7 |
|
坏 |
|
7 |
4 |
|
N/A |
|
3 |
4 |
|
好 |
|
1 |
4 |
|
好 |
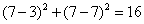
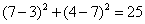
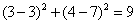
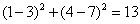
所以,最后的投票,好的有2票,坏的有1票,最终需要测试的(3,7)是合格品。(当然,你还可以使用权重——可以把距离值做为权重,越近的权重越大,这样可能会更准确一些)
注:示例来自这里,K-NearestNeighbors Excel表格下载
预测
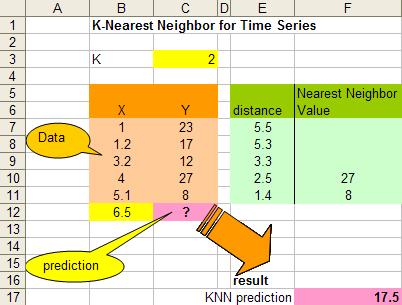
假设我们有下面一组数据,假设X是流逝的秒数,Y值是随时间变换的一个数值(你可以想像是股票值)
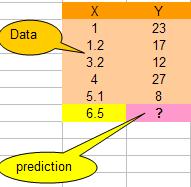
那么,当时间是6.5秒的时候,Y值会是多少呢?我们可以用KNN算法来预测之。
这里,让我们假设K=2,于是我们可以计算所有X点到6.5的距离,如:X=5.1,距离是 | 6.5 – 5.1 | = 1.4, X = 1.2 那么距离是 | 6.5 – 1.2 | = 5.3 。于是我们得到下面的表:
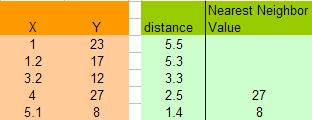
注意,上图中因为K=2,所以得到X=4 和 X =5.1的点最近,得到的Y的值分别为27和8,在这种情况下,我们可以简单的使用平均值来计算: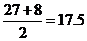
于是,最终预测的数值为:17.5
注:示例来自这里,KNN_TimeSeries Excel表格下载
插值,平滑曲线
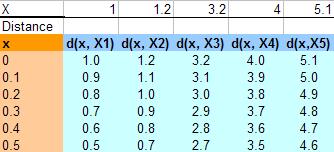
KNN算法还可以用来做平滑曲线用,这个用法比较另类。假如我们的样本数据如下(和上面的一样):

要平滑这些点,我们需要在其中插入一些值,比如我们用步长为0.1开始插值,从0到6开始,计算到所有X点的距离(绝对值),下图给出了从0到0.5 的数据:
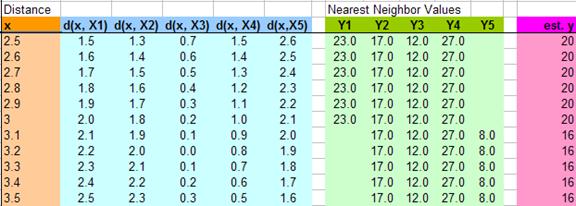
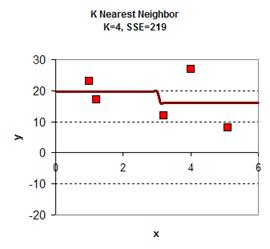
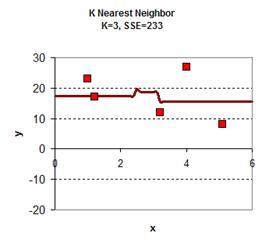
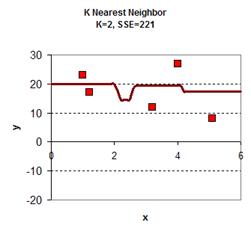
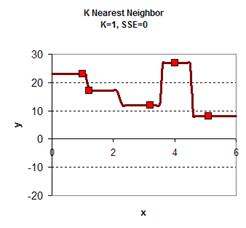
下图给出了从2.5到3.5插入的11个值,然后计算他们到各个X的距离,假值K=4,那么我们就用最近4个X的Y值,然后求平均值,得到下面的表:
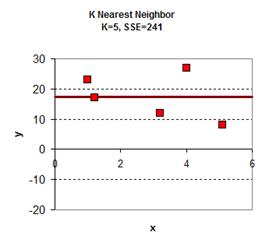
于是可以从0.0, 0.1, 0.2, 0.3 …. 1.1, 1.2, 1.3…..3.1, 3.2…..5.8, 5.9, 6.0 一个大表,跟据K的取值不同,得到下面的图:
 |
 |
 |
 |
 |
注:示例来自这里,KNN_Smoothing Excel表格下载
后记
最后,我想再多说两个事,
1) 一个是机器学习,算法基本上都比较简单,最难的是数学建模,把那些业务中的特性抽象成向量的过程,另一个是选取适合模型的数据样本。这两个事都不是简单的事。算法反而是比较简单的事。
2)对于KNN算法中找到离自己最近的K个点,是一个很经典的算法面试题,需要使用到的数据结构是“最大堆——Max Heap”,一种二叉树。你可以看看相关的算法。
K Nearest Neighbor 算法的更多相关文章
- K NEAREST NEIGHBOR 算法(knn)
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法.其中的K表示最接近自己的K个数据样本.KNN算法和K-M ...
- K nearest neighbor cs229
vectorized code 带来的好处. import numpy as np from sklearn.datasets import fetch_mldata import time impo ...
- K-Means和K Nearest Neighbor
来自酷壳: http://coolshell.cn/articles/7779.html http://coolshell.cn/articles/8052.html
- [机器学习系列] k-近邻算法(K–nearest neighbors)
C++ with Machine Learning -K–nearest neighbors 我本想写C++与人工智能,但是转念一想,人工智能范围太大了,我根本介绍不完也没能力介绍完,所以还是取了他的 ...
- 【cs231n】图像分类-Nearest Neighbor Classifier(最近邻分类器)【python3实现】
[学习自CS231n课程] 转载请注明出处:http://www.cnblogs.com/GraceSkyer/p/8735908.html 图像分类: 一张图像的表示:长度.宽度.通道(3个颜色通道 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- K近邻分类算法实现 in Python
K近邻(KNN):分类算法 * KNN是non-parametric分类器(不做分布形式的假设,直接从数据估计概率密度),是memory-based learning. * KNN不适用于高维数据(c ...
- Nearest neighbor graph | 近邻图
最近在开发一套自己的单细胞分析方法,所以copy paste事业有所停顿. 实例: R eNetIt v0.1-1 data(ralu.site) # Saturated spatial graph ...
- K邻近分类算法
# -*- coding: utf-8 -*- """ Created on Thu Jun 28 17:16:19 2018 @author: zhen "& ...
随机推荐
- python中requests已安装却仍报No module named requests错的原因
调用pip list可见已经成功安装了: requests 但是在运行时仍报错: userdeMacBook-Pro:xiaohui user$ python test_web.py Tracebac ...
- IDEA里面添加lombok插件,编写简略风格Java代码(转)
文章转自http://blog.csdn.net/hinstenyhisoka/article/details/50468271 在 java平台上,lombok 提供了简单的注解的形式来帮助我们消除 ...
- Linux中添加、修改和删除用户和用户组
宽为限 紧用功 功夫到 滞塞通 一.用户: 在创建用户时,需要为新建用户指定一用户组,如果不指定其用户所属的工作组,自动会生成一个与用户名同名的工作组.创建用户user1的时候指定其所属工作组user ...
- PAT A1145 Hashing - Average Search Time (25 分)——hash 散列的平方探查法
The task of this problem is simple: insert a sequence of distinct positive integers into a hash tabl ...
- Html5 标签二(超链接)
1.五种超链接形式 2.超链接属性 一 五种超链接 <!DOCTYPE html> <html lang="en"> <head> <me ...
- qt 程序中执行额外程序和脚本
1.最简单的,我们可以通过system直接启动一个应用程序或者脚本:(但是要调用 #include <stdlib.h>) system("./helloworld") ...
- Android之TCP服务器编程
推荐一个学java或C++的网站http://www.weixueyuan.net/,本来想自己学了总结出来再写博客,现在没时间,打字太慢!!!!,又想让这好东西让许多人知道. 关于网络通信:每一台电 ...
- LiveCharts文档-3开始-2基础
原文:LiveCharts文档-3开始-2基础 LiveCharts文档-3开始-2基础 基本使用 LiveCharts设计的很容易使用,所有的东西都可以自动的实现更新和动画,库会在它觉得有必要更新的 ...
- WPF 滚动文字控件MarqueeControl
原文:WPF 滚动文字控件MarqueeControl WPF使用的滚动文字控件,支持上下左右滚动方式,支持设置滚动速度 XAML部分: <UserControl x:Class="U ...
- BootStrap学习(5)_多媒体对象&列表组
一.多媒体对象 这些抽象的对象样式用于创建各种类型的组件(比如:博客评论),我们可以在组件中使用图文混排,图像可以左对齐或者右对齐.媒体对象可以用更少的代码来实现媒体对象与文字的混排. .media: ...